


A interpolação de quadros em vídeo (VFI) é um problema aberto na pesquisa de vídeo generativo. O desafio consiste em gerar quadros intermediários entre dois quadros existentes em uma sequência de vídeo.
Clique para reproduzir. O framework FILM, uma colaboração entre o Google e a Universidade de Washington, propôs um método eficaz de interpolação de quadros que continua popular tanto entre amadores quanto profissionais. À esquerda, podemos ver os dois quadros separados e distintos superpostos; no meio, o ‘quadro final’; e à direita, a síntese final entre os quadros. Fontes: https://film-net.github.io/ e https://arxiv.org/pdf/2202.04901
De modo geral, essa técnica remonta a mais de um século, sendo utilizada na animação tradicional desde então. Nesse contexto, quadros ‘-chave’ eram gerados por um artista principal, enquanto o trabalho de ‘tweening’ para os quadros intermediários era realizado por outros colaboradores como uma tarefa mais simples.
Antes da ascensão da IA generativa, a interpolação de quadros era utilizada em projetos como Estimativa de Fluxo Intermediário em Tempo Real (RIFE), Interpolação de Quadros de Vídeo Consciente da Profundidade (DAIN) e Interpolação de Quadros para Grandes Movimentos do Google (FILM – veja acima), com o objetivo de aumentar a taxa de quadros de um vídeo existente ou possibilitar efeitos de câmera lenta gerados artificialmente. Isso é realizado dividindo os quadros existentes de um clipe e gerando quadros intermediários estimados.
A VFI também é utilizada no desenvolvimento de codecs de vídeo mais avançados e, de maneira mais geral, em sistemas baseados em fluxo óptico (incluindo sistemas generativos), que utilizam conhecimento avançado de quadros-chave futuros para otimizar e moldar o conteúdo intersticial que os precede.
Quadros Finais em Sistemas de Vídeo Generativo
Sistemas generativos modernos como Luma e Kling permitem que os usuários especifiquem um quadro inicial e um quadro final, e podem realizar essa tarefa analisando os pontos-chave nas duas imagens e estimando uma trajetória entre elas.
Como podemos ver nos exemplos abaixo, fornecer um ‘quadro de fechamento’ permite que o sistema de vídeo generativo (neste caso, Kling) mantenha aspectos como identidade, mesmo que os resultados não sejam perfeitos (particularmente em movimentos amplos).
Clique para reproduzir. Kling é um dos vários geradores de vídeo em crescimento, incluindo Runway e Luma, que permitem ao usuário especificar um quadro final. Na maioria dos casos, movimentos mínimos levam aos resultados mais realistas e menos falhos. Fonte: https://www.youtube.com/watch?v=8oylqODAaH8
No exemplo acima, a identidade da pessoa é consistente entre os dois quadros-chave fornecidos pelo usuário, resultando em uma geração de vídeo relativamente consistente.
Quando apenas o quadro inicial é fornecido, a janela de atenção dos sistemas generativos geralmente não é grande o suficiente para ‘lembrar’ como a pessoa se parecia no início do vídeo. Em vez disso, a identidade provavelmente mudará um pouco a cada quadro, até que toda semelhança seja perdida. No exemplo abaixo, uma imagem inicial foi carregada e o movimento da pessoa foi guiado por um prompt de texto:
Clique para reproduzir. Sem um quadro final, Kling apenas tem um pequeno grupo de quadros imediatamente anteriores para guiar a geração dos próximos quadros. Em casos onde qualquer movimento significativo é necessário, essa atrofia de identidade se torna severa.
Podemos ver que a semelhança do ator não resiste às instruções, pois o sistema generativo não sabe como ele pareceria se estivesse sorrindo, e ele não está sorrindo na imagem inicial (a única referência disponível).
A maioria dos clipes gerados viralmente é cuidadosamente organizada para minimizar essas deficiências. No entanto, o progresso dos sistemas generativos de vídeo temporariamente consistentes pode depender de novos desenvolvimentos do setor de pesquisa em relação à interpolação de quadros, já que a única alternativa possível é depender de CGI tradicional como um vídeo ‘guia’ (e mesmo nesse caso, a consistência de textura e iluminação atualmente está difícil de alcançar).
Além disso, a natureza lentamente iterativa de derivar um novo quadro de um pequeno grupo de quadros recentes torna muito difícil alcançar movimentos grandes e ousados. Isso ocorre porque um objeto que se move rapidamente através de um quadro pode se deslocar de um lado para o outro na passagem de um único quadro, ao contrário dos movimentos mais graduais em que o sistema provavelmente foi treinado.
Da mesma forma, uma mudança significativa e ousada de pose pode levar não apenas a uma mudança de identidade, mas a não-congruências vívidas:
Clique para reproduzir. Neste exemplo do Luma, o movimento solicitado não parece estar bem representado nos dados de treinamento.
Framer
Isso nos leva a um interessante artigo recente da China, que afirma ter alcançado um novo estado da arte em interpolação de quadros com aparência autêntica – e que é o primeiro de sua espécie a oferecer interação do usuário baseada em arrasto.
Framer permite ao usuário direcionar o movimento usando uma interface intuitiva baseada em arrasto, embora também tenha um modo ‘automático’. Fonte: https://www.youtube.com/watch?v=4MPGKgn7jRc
Aplicações centradas em arrasto têm se tornado frequentes na literatura recentemente, à medida que o setor de pesquisa luta para fornecer instrumentalidades para sistemas generativos que não sejam baseados nos resultados algo rudimentares obtidos por prompts de texto.
O novo sistema, intitulado Framer, pode não apenas seguir o arrasto guiado pelo usuário, mas também tem um modo ‘piloto automático’ mais convencional. Além do tweening convencional, o sistema é capaz de produzir simulações em time-lapse, além de morphing e novas visões da imagem de entrada.

Quadros intersticiais gerados para uma simulação em time-lapse no Framer. Fonte: https://arxiv.org/pdf/2410.18978
Em relação à produção de novas visões, o Framer cruza um pouco no território dos Campos de Radiação Neural (NeRF) – embora exija apenas duas imagens, enquanto o NeRF geralmente requer seis ou mais visualizações de entrada.
Em testes, o Framer, que é fundamentado no modelo gerativo de difusão latente Stable Video Diffusion da Stability.ai, foi capaz de superar abordagens rivais aproximadas, em um estudo com usuários.
No momento da redação, o código está programado para ser liberado no GitHub. Amostras de vídeo (das quais as imagens acima foram derivadas) estão disponíveis no site do projeto, e os pesquisadores também lançaram um vídeo no YouTube.
O novo artigo é intitulado Framer: Interpolação Interativa de Quadros, e vem de nove pesquisadores da Universidade de Zhejiang e do Grupo Ant, apoiado pelo Alibaba.
Método
O Framer utiliza interpolação baseada em pontos-chave em qualquer um de seus dois modos, onde a imagem de entrada é avaliada quanto à topologia básica, e pontos ‘móveis’ são atribuídos onde necessário. Na prática, esses pontos são equivalentes a marcos faciais em sistemas baseados em ID, mas se generalizam para qualquer superfície.
Os pesquisadores ajustaram o Stable Video Diffusion (SVD) no conjunto de dados OpenVid-1M, adicionando uma capacidade adicional de síntese do último quadro. Isso facilita um mecanismo de controle de trajetória (canto superior direito na imagem do esquema abaixo) que pode avaliar um caminho em direção ao quadro final (ou de volta a ele).
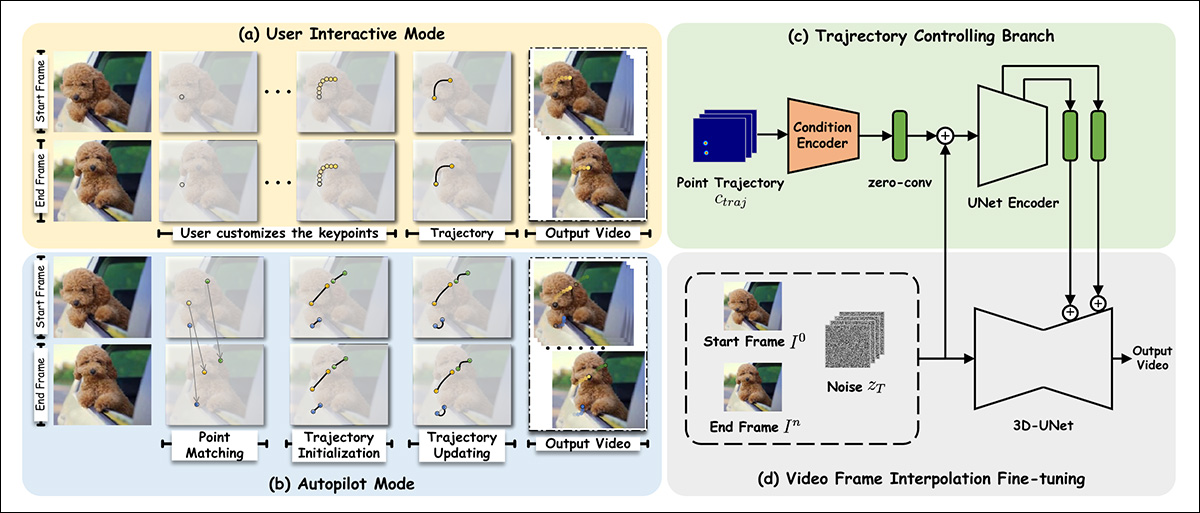
Esquema para o Framer.
Quanto à adição de condicionamento do último quadro, os autores afirmam:
‘Para preservar o prior visual do SVD pré-treinado tanto quanto possível, seguimos o paradigma de condicionamento do SVD e injetamos condições do quadro final no espaço latente e no espaço semântico, respectivamente.’
‘Especificamente, concatenamos a característica latente codificada pelo VAE do primeiro [quadro] com o latente ruidoso do primeiro quadro, como foi feito no SVD. Além disso, concatenamos a característica latente do último quadro, zn, com o latente ruidoso do quadro final, considerando que as condições e os latentes ruidosos correspondentes estão spatialmente alinhados.’
‘Além disso, extraímos a incorporação da imagem CLIP dos primeiros e últimos quadros separadamente e as concatenamos para a injeção de característica de atenção cruzada.’
Para a funcionalidade baseada em arrasto, o módulo de trajetória aproveita o framework CoTracker liderado pelo Meta Ai, que avalia possíveis trilhas à frente. Essas são reduzidas para entre 1 a 10 possíveis trajetórias.
As coordenadas de ponto obtidas são então transformadas por uma metodologia inspirada nas arquiteturas DragNUWA e DragAnything. Isso obtém um mapa de calor gaussiano, que individua as áreas-alvo para movimento.
Subsequentemente, os dados são alimentados nos mecanismos de condicionamento do ControlNet, um sistema de conformidade auxiliar originalmente projetado para a Difusão Estável, e desde então adaptado para outras arquiteturas.
Para o modo piloto automático, o emparelhamento de características é inicialmente realizado via SIFT, que interpreta uma trajetória que pode então ser passada para um mecanismo de autoatualização inspirado no DragGAN e DragDiffusion.
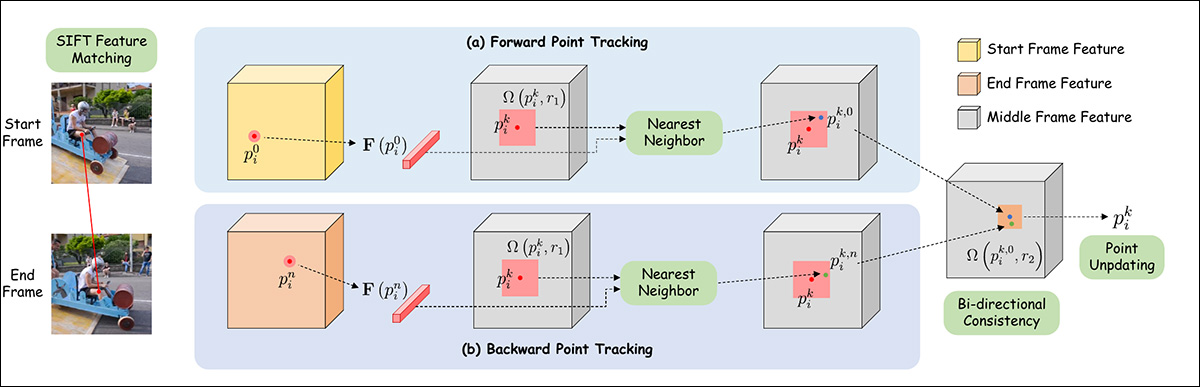
Esquema para estimativa de trajetória de pontos no Framer.
Dados e Testes
Para o ajuste fino do Framer, os blocos de atenção espacial e de resíduos foram congelados, e apenas as camadas de atenção temporal e blocos de resíduos foram afetados.
O modelo foi treinado por 10.000 iterações sob AdamW, com uma taxa de aprendizado de 1e-4 e um tamanho de lote de 16. O treinamento foi realizado em 16 GPUs NVIDIA A100.
Como as abordagens anteriores para o problema não oferecem edição baseada em arrasto, os pesquisadores optaram por comparar o modo piloto automático do Framer com a funcionalidade padrão de ofertas mais antigas.
Os frameworks testados para a categoria de sistemas de geração de vídeo baseados em difusão atuais foram LDMVFI; Dynamic Crafter; e SVDKFI. Para sistemas de vídeo ‘tradicionais’, os frameworks rivais foram AMT; RIFE; FLAVR; e o mencionado FILM.
Além do estudo com usuários, testes foram realizados nos conjuntos de dados DAVIS e UCF101.
Testes qualitativos podem ser avaliados apenas pelas faculdades objetivas da equipe de pesquisa e por estudos com usuários. No entanto, o artigo observa que métricas tradicionais quantitativas são em grande parte inadequadas à proposta em questão:
‘As métricas de [reconstrução] como PSNR, SSIM e LPIPS não conseguem capturar a qualidade dos quadros interpolados com precisão, pois penalizam outros resultados plausíveis de interpolação que não estão pixel-alinhados com o vídeo original.’
‘Enquanto métricas de geração como FID oferecem alguma melhoria, ainda assim falham, pois não levam em conta a consistência temporal e avaliam os quadros isoladamente.’
Apesar disso, os pesquisadores realizaram testes qualitativos com várias métricas populares:
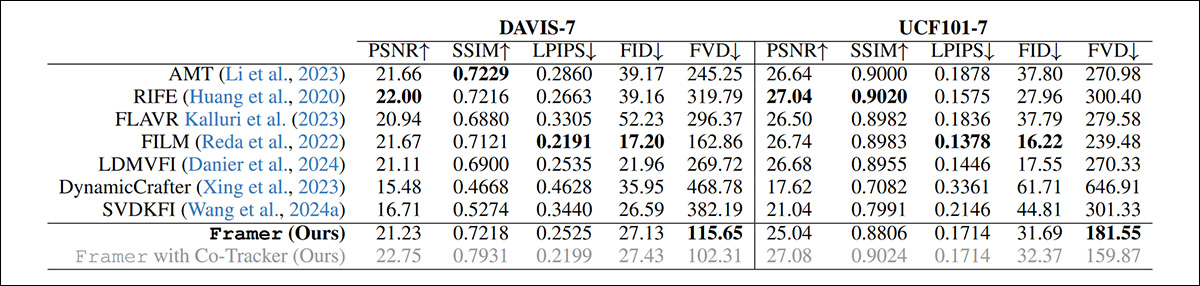
Resultados quantitativos para Framer vs. sistemas rivais.
Os autores observam que, apesar de ter as odds contra eles, o Framer ainda alcança a melhor pontuação FVD entre os métodos testados.
Abaixo estão os resultados de amostra do artigo para uma comparação qualitativa:

Comparação qualitativa com abordagens anteriores. Consulte o artigo para melhor resolução, bem como os resultados em vídeo em https://www.youtube.com/watch?v=4MPGKgn7jRc.
Os autores comentam:
‘[Nosso] método produz texturas significativamente mais claras e movimentos naturais em comparação com técnicas de interpolação existentes. Desempenha especialmente bem em cenários com diferenças substanciais entre os quadros de entrada, onde métodos tradicionais costumam falhar em interpolar o conteúdo com precisão.’
‘Comparado a outros métodos baseados em difusão como LDMVFI e SVDKFI, o Framer demonstra uma melhor adaptabilidade a casos desafiadores e oferece melhor controle.’
Para o estudo com usuários, os pesquisadores reuniram 20 participantes, que avaliaram 100 resultados de vídeo aleatoriamente ordenados dos vários métodos testados. Assim, foram obtidas 1000 classificações, avaliando as ofertas mais ‘realistas’:
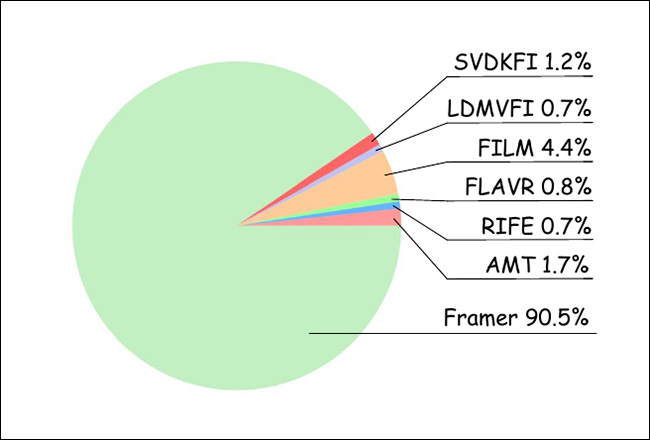
Resultados do estudo com usuários.
Como pode ser visto no gráfico acima, os usuários favoreceram amplamente os resultados do Framer.
O vídeo do projeto no YouTube descreve alguns dos outros possíveis usos para o Framer, incluindo morphing e o tweening de cartoons – onde todo o conceito começou.
Conclusão
É difícil exagerar a importância desse desafio atualmente para a tarefa de geração de vídeo baseada em IA. Até agora, soluções mais antigas como o FILM e o EbSynth (não-AI) foram utilizadas, tanto por comunidades amadoras quanto profissionais, para tweening entre quadros; mas essas soluções vêm com limitações notáveis.
Devido à curadoria enganosa dos vídeos de exemplo oficiais para novas estruturas T2V, há um grande equívoco público de que os sistemas de aprendizado de máquina podem inferir com precisão a geometria em movimento sem recorrer a mecanismos de orientação, como modelos morfáveis em 3D (3DMMs), ou outras abordagens auxiliares, como LoRAs.
Para ser honesto, o tweening em si, mesmo que possa ser executado perfeitamente, apenas constitui um ‘hack’ ou trapaça para esse problema. No entanto, já que muitas vezes é mais fácil produzir duas imagens de quadro bem alinhadas do que efetuar orientação por meio de prompts de texto ou a atual gama de alternativas, é bom ver o progresso iterativo em uma versão baseada em IA desse método mais antigo.
Publicada pela primeira vez na terça-feira, 29 de outubro de 2024



Conteúdo relacionado

FLUX.1 Kontext permite a geração de imagens em contexto para pipelines de IA empresarial.
[the_ad id="145565"] Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba Mais…

Elon se afasta do DOGE e o Vale do Silício entra na fase de ‘descoberta’
[the_ad id="145565"] Elon Musk anunciou oficialmente que está se afastando como um funcionário especial do governo dos EUA e o chefe de fato do Departamento de Eficiência…

Startup de IA com voz emotiva Hume lança novo modelo EVI 3 com criação rápida de vozes personalizadas.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre coberturas líderes da indústria em IA. Saiba…