


Em 17 de outubro de 2024, a Microsoft anunciou o BitNet.cpp, um framework de inferência projetado para executar Modelos de Linguagem de Grande Escala (LLMs) quantizados em 1-bit. O BitNet.cpp representa um progresso significativo na Inteligência Artificial Generativa (Gen AI), permitindo a implementação eficiente de LLMs de 1-bit em CPUs padrão, sem a necessidade de GPUs caras. Este desenvolvimento democratiza o acesso aos LLMs, tornando-os disponíveis em uma ampla gama de dispositivos e proporcionando novas possibilidades em aplicações de IA em dispositivos.
Entendendo os Modelos de Linguagem de 1-bit
Os Modelos de Linguagem de Grande Escala (LLMs) tradicionalmente exigiram recursos computacionais significativos devido ao uso de números de ponto flutuante de alta precisão (tipicamente FP16 ou BF16) para os pesos do modelo. Essa necessidade tornou a implementação de LLMs cara e energicamente intensiva.
Fundamentalmente, os LLMs de 1-bit utilizam técnicas de quantização extrema para representar os pesos do modelo usando apenas três valores possíveis: -1, 0 e 1, daí o termo “1.58-bit” (já que requer um pouco mais de um bit para codificar três estados).
Sistema de Pesos Ternário
A Conceituação
A quantização de 1-bit no BitNet.cpp é um sistema de pesos ternário. O BitNet opera apenas com três valores possíveis para cada parâmetro:
- -1 (negativo)
- 0 (neutro)
- 1 (positivo)
Isso resulta em uma exigência de armazenamento de cerca de 1.58 bits por parâmetro, daí o nome BitNet b1.58. Essa drástica redução na largura de bits dos parâmetros leva a uma impressionante diminuição no uso de memória e na complexidade computacional, já que a maioria das multiplicações de ponto flutuante são substituídas por adições e subtrações simples.
Fundamentos Matemáticos
A quantização de 1-bit envolve transformar pesos e ativações em sua representação ternária através das seguintes etapas:
1. Binarização de Pesos
A binarização dos pesos envolve centralizá-los em torno da média (α), resultando em uma representação ternária. A transformação é expressa matematicamente como:
Wf=Sign(W−α)
Onde:
- W é a matriz de pesos original.
- α é a média dos pesos.
- Sign(x) retorna +1 se x > 0 e -1 caso contrário.
2. Quantização de Ativações
A quantização de ativações assegura que as entradas sejam restringidas a uma largura de bit específica:
Onde:
- Qb = 2(b−1)2^{(b-1)} é o nível de quantização máximo para largura deb bits.
- γ é o valor absoluto máximo de x (denotado como ∣∣x∣∣∞).
- ε é um pequeno número para prevenir overflow durante os cálculos.
3. Operação BitLinear
A camada BitLinear substitui as multiplicações matriciais tradicionais por uma operação simplificada:
y=Wf×x^e×(Qbβγ)
Onde:
- β é um fator de escala usado para minimizar erros de aproximação.
- γ escala as ativações.
- Q_b é o fator de quantização.
Essa transformação possibilita computações eficientes ao mesmo tempo que preserva o desempenho do modelo.
Implicações de Desempenho
Eficiência de Memória
O sistema de pesos ternário reduz significativamente os requisitos de memória:
- LLMs Tradicionais: 16 bits por peso
- BitNet.cpp: 1.58 bits por peso
Essa redução se traduz em uma economia de memória de aproximadamente 90% em comparação com os modelos tradicionais de 16 bits, permitindo que modelos maiores se ajustem dentro das mesmas restrições de hardware.
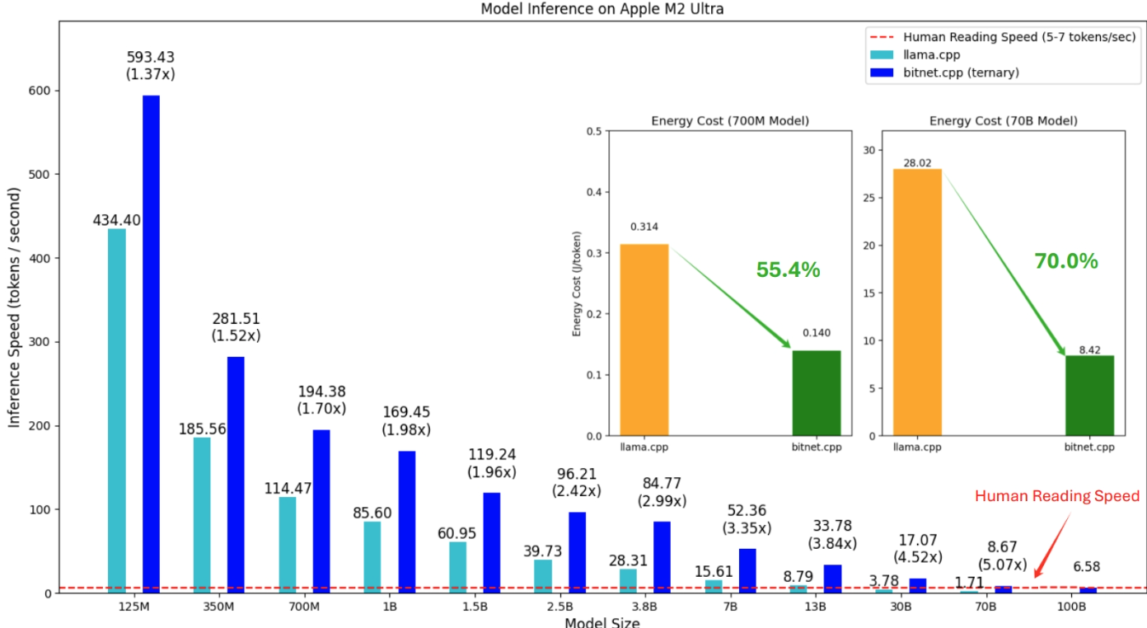
Velocidade de Inferência, Eficiência Energética (Apple M2)
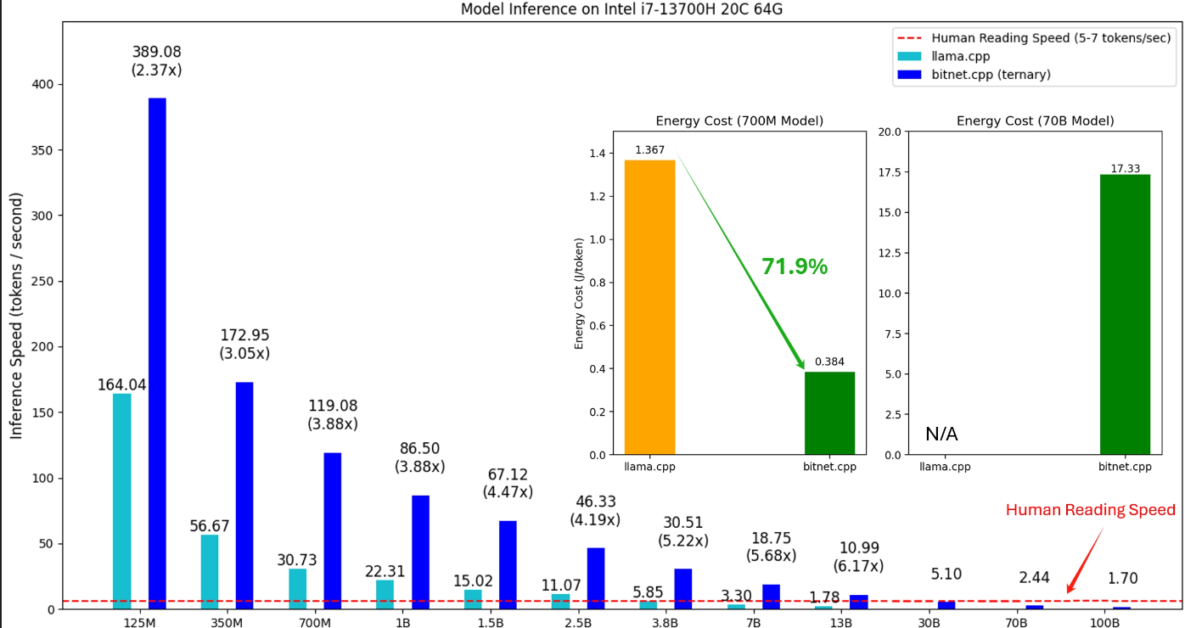
Velocidade de Inferência, Eficiência Energética (i7-13700H)
1. Velocidade de Inferência: Mais Rápido em Ambas as CPUs
A velocidade de inferência é representada como o número de tokens processados por segundo. Aqui está uma divisão das observações:
- No Apple M2 Ultra: O BitNet.cpp alcança até 5.07x de incremento de velocidade para modelos maiores (30B) em comparação ao Llama.cpp, com uma velocidade máxima de 593.43 tokens por segundo para um modelo de 125M, o que é um 1.37x de velocidade. Para modelos maiores, como 3.8B e 7B, o BitNet.cpp mantém uma velocidade acima de 84.77 tokens por segundo, demonstrando sua eficiência em ampla escala.
- No Intel i7-13700H: O BitNet.cpp consegue melhorias de velocidade ainda mais dramáticas. No tamanho do modelo 7B, o BitNet.cpp entrega um incrível 5.68x de aumento de velocidade em comparação ao Llama.cpp. Para modelos menores, como 125M, processa 389.08 tokens por segundo, que é 2.37x mais rápido que o Llama.cpp.
2. Eficiência Energética: Uma Revolução para Dispositivos Edge
Os gráficos apresentados também incluem comparações de custo energético, que mostram uma redução significativa no consumo de energia por token processado:
- No Apple M2 Ultra: As economias de energia do BitNet.cpp são substanciais. Para o modelo de 700M, consome 55.4% menos energia por token em comparação ao Llama.cpp, caindo de 0.314 para 0.140. Essa tendência continua para modelos maiores, com o modelo de 70B mostrando uma redução de 70.0% no consumo de energia.
- No Intel i7-13700H: O BitNet.cpp oferece 71.9% de economia de energia para o modelo de 700M, com o consumo caindo de 1.367 para 0.384. Embora não haja dados de energia para o modelo de 70B no Llama.cpp, o BitNet.cpp permanece eficiente, com consumo de energia em 17.33 para o modelo de 70B.
3. Superando a Referência de Velocidade de Leitura Humana
Uma das descobertas mais interessantes desses gráficos é a referência à velocidade de leitura humana, marcada em 5-7 tokens por segundo. Essa linha vermelha mostra que ambas as implementações, especialmente o BitNet.cpp, podem superar confortavelmente as velocidades de leitura humana mesmo para os maiores modelos:
- No Apple M2 Ultra, o BitNet.cpp supera a velocidade de leitura humana para todos os tamanhos de modelo, com a menor velocidade sendo 8.67 tokens por segundo para um modelo de 70B.
- No Intel i7-13700H, o modelo de 100B ainda alcança 1.70 tokens por segundo, quase tocando a faixa inferior da velocidade de leitura humana, enquanto todos os modelos menores superam esse benchmark.
Considerações sobre Treinamento
Estimador de Passagem Direta (STE)
Como a quantização de 1-bit introduz funções não diferenciáveis, o treinamento envolve uma técnica especial conhecida como Estimador de Passagem Direta (STE). Nesta abordagem, os gradientes fluem inalterados através de pontos não diferenciáveis. Aqui está uma implementação simplificada em Python:
class StraightThroughEstimator(Function):
@staticmethod
def forward(ctx, input):
return input.sign()
@staticmethod
def backward(ctx, grad_output):
return grad_output
Treinamento de Precisão Mista
Para manter a estabilidade durante o treinamento, utiliza-se precisão mista:
- Pesos e Ativações: Quantizados para precisão de 1-bit.
- Gradientes e Estados do Otimizador: Armazenados em precisão mais alta.
- Pesos Latentes: Mantidos em alta precisão para facilitar atualizações precisas durante o treinamento.
Estratégia de Taxa de Aprendizado Alta
Um desafio único com modelos de 1-bit é que pequenas atualizações podem não afetar os pesos binarizados. Para mitigar isso, a taxa de aprendizado é aumentada, garantindo uma convergência mais rápida e uma melhor otimização em comparação com abordagens tradicionais.
Quantização e Normalização em Grupo
O BitNet.cpp introduz a Quantização e Normalização em Grupo para melhorar o paralelismo do modelo. Em vez de calcular parâmetros para toda a matriz de pesos, o BitNet divide pesos e ativações em vários grupos (G).
Esse agrupamento permite o processamento paralelo eficiente sem comunicação adicional entre grupos, facilitando o treinamento e inferência em larga escala do modelo.
Anotações de Implementação e Otimizações
Otimização de CPU
O BitNet.cpp aproveita várias otimizações de baixo nível para alcançar o desempenho máximo da CPU:
- Operações Vetorizadas: Utiliza instruções SIMD para realizar manipulações de bits de forma eficiente.
- Acesso à Memória Amigável ao Cache: Estruturas de dados para minimizar falhas de cache.
- Processamento Paralelo: Distribui a carga de trabalho de maneira eficaz entre vários núcleos da CPU.
Aqui está um exemplo de uma função chave que implementa quantização e inferência no BitNet:
Modelos Suportados
A versão atual do BitNet.cpp suporta os seguintes LLMs de 1-bit disponíveis no Hugging Face:
- bitnet_b1_58-large (0.7B parâmetros)
- bitnet_b1_58-3B (3.3B parâmetros)
- Llama3-8B-1.58-100B-tokens (8.0B parâmetros)
Esses modelos estão disponíveis publicamente para demonstrar as capacidades de inferência do framework. Embora não tenham sido oficialmente treinados ou lançados pela Microsoft, eles ilustram a versatilidade do framework.
Guia de Instalação
Para começar com o BitNet.cpp, siga os passos abaixo:
Pré-requisitos
- Python >= 3.9
- CMake >= 3.22
- Clang >= 18
- Conda (altamente recomendado)
Para usuários de Windows, o Visual Studio deve ser instalado com os seguintes componentes habilitados:
- Desenvolvimento de Desktop com C++
- Ferramentas C++-CMake para Windows
- Git para Windows
- Compilador C++-Clang para Windows
- Suporte MS-Build para o LLVM Toolset (Clang)
Para usuários de Debian/Ubuntu, um script de instalação automática está disponível:
Instalação Passo a Passo
- Clone o Repositório:
- Instale as Dependências:
- Construa e Prepare o Projeto: Você pode baixar um modelo diretamente do Hugging Face e convertê-lo para um formato quantizado:
Alternativamente, baixe e converta o modelo manualmente:
Executando Inferência com BitNet.cpp
Para executar a inferência usando o framework, use o seguinte comando:
Explicação:
-mespecifica o caminho do arquivo do modelo.-pdefine o texto do prompt.-ndefine o número de tokens a serem previstos.-tempajusta a aleatoriedade da amostragem (temperatura) durante a inferência.
Exemplo de Saída
Detalhes Técnicos do BitNet.cpp
Camada BitLinear
O BitNet.cpp implementa uma arquitetura Transformer modificada, substituindo multiplicações matriciais padrão por operações BitLinear. Essa abordagem centraliza os pesos em zero antes da quantização e os escala para reduzir erros de aproximação. A função de transformação chave é a seguinte:
# Função de binarização para pesos de 1-bit
def binarize_weights(W):
alpha = W.mean()
W_binarized = np.sign(W - alpha)
return W_binarized
A combinação de pesos centralizados e escalonamento garante que o erro de quantização permaneça mínimo, preservando assim o desempenho.
Impacto na Indústria
O BitNet.cpp pode ter implicações de longo alcance para a implementação de LLMs:
- Acessibilidade: Permite que LLMs sejam executados em dispositivos padrão, democratizando o acesso a IA poderosa.
- Eficiência de Custo: Reduz a necessidade de GPUs caras, diminuindo a barreira para adoção.
- Eficiência Energética: Economiza energia aproveitando a inferência baseada em CPU padrão.
- Inovação: Abre novas possibilidades para IA em dispositivos, como tradução de idiomas em tempo real, assistentes de voz e aplicações focadas em privacidade sem dependências em nuvem.
Desafios e Direções Futuras
Embora os LLMs de 1-bit tenham potencial, vários desafios permanecem. Estes incluem o desenvolvimento de modelos robustos de 1-bit para diversas tarefas, a otimização de hardware para computação de 1-bit e o incentivo a desenvolvedores a adotarem este novo paradigma. Além disso, explorar a quantização de 1-bit para tarefas de visão computacional ou áudio representa uma direção futura empolgante.
Conclusão
O lançamento do BitNet.cpp pela Microsoft é um avanço significativo. Ao possibilitar inferência eficiente de 1-bit em CPUs padrão, o BitNet.cpp cria acessibilidade e sustentabilidade para a IA. Este framework prepara o terreno para LLMs mais portáteis e economicamente viáveis, empurrando os limites do que é possível com IA em dispositivos.



Conteúdo relacionado

FLUX.1 Kontext permite a geração de imagens em contexto para pipelines de IA empresarial.
[the_ad id="145565"] Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba Mais…

Elon se afasta do DOGE e o Vale do Silício entra na fase de ‘descoberta’
[the_ad id="145565"] Elon Musk anunciou oficialmente que está se afastando como um funcionário especial do governo dos EUA e o chefe de fato do Departamento de Eficiência…

Startup de IA com voz emotiva Hume lança novo modelo EVI 3 com criação rápida de vozes personalizadas.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre coberturas líderes da indústria em IA. Saiba…