


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre o setor de IA. Saiba mais
Google DeepMind e Hugging Face acabam de lançar SynthID Text, uma ferramenta para marcar e detectar textos gerados por grandes modelos de linguagem (LLMs). O SynthID Text codifica uma marca d’água no texto gerado pela IA, ajudando a determinar se um LLM específico o produziu. Mais importante ainda, isso é feito sem modificar o funcionamento do LLM subjacente ou reduzir a qualidade do texto gerado.
A técnica por trás do SynthID Text foi desenvolvida por pesquisadores da DeepMind e apresentada em um artigo publicado na Nature em 23 de outubro. Uma implementação do SynthID Text foi adicionada à biblioteca Transformers da Hugging Face, que é usada para criar aplicações baseadas em LLMs. Vale notar que o SynthID não foi projetado para detectar qualquer texto gerado por um LLM. Ele é feito para marcar a saída de um LLM específico.
Utilizar o SynthID não requer re-treinamento do LLM subjacente. Ele usa um conjunto de parâmetros que podem configurar o equilíbrio entre a força da marca d’água e a preservação da resposta. Uma empresa que utilize LLMs pode ter diferentes configurações de marca d’água para diferentes modelos. Essas configurações devem ser armazenadas de forma segura e privada para evitar que sejam replicadas por outros.
Para cada configuração de marca d’água, é necessário treinar um modelo classificador que recebe uma sequência de texto e determina se ela contém a marca d’água do modelo ou não. Detectores de marca d’água podem ser treinados com alguns milhares de exemplos de texto normal e respostas que foram marcadas com a configuração específica.
Nós tornamos open source o @GoogleDeepMind‘s SynthID, uma ferramenta que permite aos criadores de modelos incorporar e detectar marcas d’água nas saídas de texto de seus próprios LLMs. Mais detalhes publicados na @Nature hoje: https://t.co/5Q6QGRvD3G
— Sundar Pichai (@sundarpichai) 23 de outubro de 2024
Como o SynthID Text funciona
Marcação d’água é uma área de pesquisa ativa, especialmente com o aumento e adoção de LLMs em diferentes campos e aplicações. Empresas e instituições estão buscando maneiras de detectar textos gerados por IA para prevenir campanhas de desinformação em massa, moderar conteúdo gerado por IA e prevenir o uso de ferramentas de IA na educação.
Existem várias técnicas para marcar texto gerado por LLMs, cada uma com suas limitações. Algumas exigem a coleta e armazenamento de informações sensíveis, enquanto outras requerem processamento computacionalmente caro após o modelo gerar sua resposta.
O SynthID utiliza “modelagem generativa”, uma classe de técnicas de marcação d’água que não afetam o treinamento do LLM e apenas modificam o procedimento de amostragem do modelo. As técnicas de marcação generativa modificam o procedimento de geração do próximo token para realizar alterações sutis e específicas ao contexto do texto gerado. Essas modificações criam uma assinatura estatística no texto gerado, mantendo sua qualidade.
Um modelo classificador é então treinado para detectar a assinatura estatística da marca d’água para determinar se uma resposta foi gerada pelo modelo ou não. Um benefício chave dessa técnica é que detectar a marca d’água é computacionalmente eficiente e não requer acesso ao LLM subjacente.
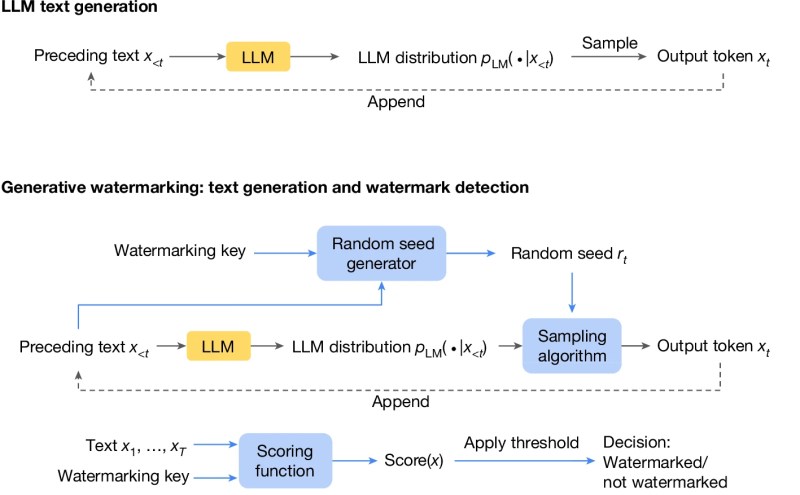
O SynthID Text baseia-se em trabalhos anteriores sobre marcação d’água generativa e utiliza um novo algoritmo de amostragem chamado “amostragem por torneio”, que usa um processo em múltiplas etapas para escolher o próximo token ao criar marcas d’água. A técnica de marcação d’água utiliza uma função pseudo-aleatória para aumentar o processo de geração de qualquer LLM, de modo que a marca d’água seja imperceptível a humanos, mas visível para um modelo classificador treinado. A integração na biblioteca Hugging Face facilitará para os desenvolvedores adicionar capacidades de marca d’água às aplicações existentes.
Para demonstrar a viabilidade da marcação d’água em sistemas de produção em larga escala, pesquisadores da DeepMind realizaram um experimento ao vivo que avaliou feedback de quase 20 milhões de respostas geradas pelos modelos Gemini. Seus achados mostram que o SynthID conseguiu preservar a qualidade das respostas enquanto também permanecia detectável por seus classificadores.
Segundo a DeepMind, o SynthID-Text foi utilizado para marcar o Gemini e o Gemini Advanced.
“Isso serve como prova prática de que a marcação d’água generativa em texto pode ser implementada com sucesso e escalada para sistemas de produção do mundo real, atendendo milhões de usuários e desempenhando um papel integral na identificação e gerenciamento de conteúdo gerado por inteligência artificial,” eles escrevem em seu artigo.
Limitações
De acordo com os pesquisadores, o SynthID Text é robusto a algumas transformações pós-geração, como o corte de trechos de texto ou a modificação de algumas palavras no texto gerado. Ele também é resiliente a parafrasear até certo ponto.
No entanto, a técnica também possui algumas limitações. Por exemplo, é menos eficaz em consultas que exigem respostas factuais e não tem espaço para modificação sem reduzir a precisão. Eles também alertam que a qualidade do detector de marca d’água pode cair consideravelmente quando o texto é reescrito de forma abrangente.
“O SynthID Text não foi projetado para impedir diretamente que adversários motivados causem danos,” escrevem. “No entanto, pode dificultar o uso de conteúdo gerado por IA para fins malignos e pode ser combinado com outras abordagens para oferecer melhor cobertura em diferentes tipos de conteúdo e plataformas.”

Conteúdo relacionado

Anthropic enviou um aviso de remoção a um desenvolvedor que tentava reverter o código de sua ferramenta.
[the_ad id="145565"] Na disputa entre duas ferramentas de código "agente" — Claude Code da Anthropic e Codex CLI da OpenAI — a última parece estar promovendo mais boa vontade…

O novo CEO da Intel sinaliza esforços de simplificação, mas não revela números exatos de demissões.
[the_ad id="145565"] Lip-Bu Tan, o novo CEO da Intel, enviou uma mensagem direta aos funcionários, afirmando que a empresa precisa se reorganizar para ser mais eficiente. Ele…

Um pesquisador da OpenAI que trabalhou no GPT-4.5 teve seu green card negado.
[the_ad id="145565"] Kai Chen, um pesquisador de IA canadense que trabalha na OpenAI e mora nos EUA há 12 anos, teve seu pedido de green card negado, de acordo com Noam Brown,…