


Se 2022 marcou o momento em que o potencial disruptivo da IA generativa capturou a ampla atenção do público, 2024 tem sido o ano em que questões sobre a legalidade dos dados subjacentes ganharam destaque entre empresas ansiosas para aproveitar seu poder.
A doutrina de uso justo dos EUA, juntamente com a licença acadêmica implícita que há muito permitia que setores de pesquisa acadêmica e comercial explorassem a IA generativa, tornou-se cada vez mais insustentável à medida que cresciam as provas de plágio. Consequentemente, os EUA proibiram, por ora, que conteúdos gerados por IA sejam considerados protegidos por direitos autorais.
Essas questões estão longe de ser resolvidas; em 2023, devido em parte à growing media and public concern sobre o status legal da saída gerada por IA, o Escritório de Direitos Autorais dos EUA iniciou uma investigação de anos sobre esse aspecto da IA generativa, publicando o primeiro segmento (relativo a réplicas digitais) em julho de 2024.
Enquanto isso, os interesses comerciais permanecem frustrados com a possibilidade de que os modelos caros que desejam explorar possam expô-los a ramificações legais quando legislação e definições definitivas eventualmente surgirem.
A solução cara no curto prazo tem sido legitimar modelos generativos treinando-os com dados que as empresas têm o direito de explorar. A arquitetura Firefly da Adobe, que gera texto para imagem (e agora texto para vídeo), é alimentada principalmente pela sua aquisição do conjunto de dados de imagens stock Fotolia em 2014, complementada pelo uso de dados do domínio público que expiraram*. Ao mesmo tempo, fornecedores incumbentes de fotos stock, como Getty e Shutterstock, capitalizaram sobre o novo valor de seus dados licenciados, com um número crescente de acordos para licenciar conteúdo ou desenvolver seus próprios sistemas de IA generativa em conformidade com a propriedade intelectual.
Soluções Sintéticas
Como remover dados protegidos por direitos autorais do espaço latente de um modelo de IA é complicado, os erros nessa área podem ser muito custosos para as empresas que estão experimentando soluções de consumo e comerciais que utilizam aprendizado de máquina.
Uma alternativa, e uma solução muito mais barata para sistemas de visão computacional (e também para Modelos de Linguagem de Grande Escala, ou LLMs), é o uso de dados sintéticos, onde o conjunto de dados é composto por exemplos aleatórios gerados do domínio alvo (como rostos, gatos, igrejas, ou mesmo um conjunto de dados mais generalizado).
Sites como thispersondoesnotexist.com popularizaram há muito a ideia de que fotos autênticas de ‘não-reais’ poderiam ser sintetizadas (neste caso particular, usando Redes Generativas Adversariais, ou GANs) sem qualquer relação com pessoas que realmente existem no mundo real.
Portanto, se você treina um sistema de reconhecimento facial ou um sistema generativo com esses exemplos abstratos e não-reais, você pode, em teoria, conseguir um padrão de produtividade fotorealista para um modelo de IA sem precisar considerar se os dados são legalmente utilizáveis.
VAbalancing Act
O problema é que os sistemas que produzem dados sintéticos são eles mesmos treinados com dados reais. Se traços desse data se infiltrarem nos dados sintéticos, isso potencialmente fornece evidências de que material restrito ou não autorizado foi explorado para ganho monetário.
Para evitar isso, e para produzir imagens verdadeiramente ‘aleatórias’, esses modelos precisam ser bem-generalizados. Generalização é a medida da capacidade de um modelo de IA treinado de compreender intrinsicamente conceitos de alto nível (como ‘rosto’, ‘homem’, ou ‘mulher’) sem recorrer à replicação dos dados de treinamento reais.
Infelizmente, para sistemas treinados, pode ser difícil produzir (ou reconhecer) detalhes granulares a menos que sejam treinados extensivamente em um conjunto de dados. Isso expõe o sistema ao risco de memorização: uma tendência a reproduzir, em certa medida, exemplos dos dados de treinamento reais.
Isso pode ser mitigado estabelecendo uma taxa de aprendizado mais relaxada, ou terminando o treinamento em um estágio onde os conceitos principais ainda são maleáveis e não estão associados a nenhum ponto de dados específico (como uma imagem específica de uma pessoa, no caso de um conjunto de dados de rosto).
No entanto, ambas essas soluções provavelmente levarão a modelos com menos detalhes refinados, uma vez que o sistema não teve a chance de progredir além dos ‘básicos’ do domínio alvo e chegar aos específicos.
Portanto, na literatura científica, geralmente são aplicadas taxas de aprendizado muito altas e cronogramas de treinamento abrangentes. Embora os pesquisadores geralmente tentem encontrar um compromisso entre aplicabilidade ampla e granularidade no modelo final, até mesmo sistemas ligeiramente ‘memorizados’ podem frequentemente se representar erroneamente como bem-generalizados – mesmo em testes iniciais.
Revelação Facial
Isso nos leva a um novo paper interessante da Suíça, que afirma ser o primeiro a demonstrar que as imagens reais que alimentam os dados sintéticos podem ser recuperadas de imagens geradas que deveriam, em teoria, ser totalmente aleatórias:

Exemplos de rostos revelados a partir dos dados de treinamento. Na linha acima, vemos as imagens originais (reais); na linha abaixo, vemos imagens geradas aleatoriamente, que correspondem significativamente às imagens reais. Source: https://arxiv.org/pdf/2410.24015
Os resultados, argumentam os autores, indicam que geradores ‘sintéticos’ realmente memorizaram muitos dos pontos de dados de treinamento, em sua busca por maior granularidade. Eles também indicam que sistemas que confiam em dados sintéticos para proteger os produtores de IA de consequências legais podem ser muito pouco confiáveis a esse respeito.
Os pesquisadores realizaram um estudo extenso em seis conjuntos de dados sintéticos de última geração, demonstrando que, em todos os casos, os dados originais (potencialmente protegidos por direitos autorais) podem ser recuperados. Eles comentam:
‘Nossos experimentos demonstram que conjuntos de dados sintéticos de reconhecimento facial de última geração contêm amostras que estão muito próximas das amostras nos dados de treinamento de seus modelos geradores. Em alguns casos, as amostras sintéticas contêm pequenas alterações em relação à imagem original, no entanto, também podemos observar que, em alguns casos, a amostra gerada contém mais variação (por exemplo, pose diferente, condições de iluminação, etc.), enquanto a identidade é preservada.’
‘Isso sugere que os modelos geradores estão aprendendo e memorizando as informações relacionadas à identidade dos dados de treinamento e podem gerar identidades semelhantes. Isso cria preocupações críticas em relação à aplicação de dados sintéticos em tarefas sensíveis à privacidade, como biometria e reconhecimento facial.’
O paper é intitulado Desvendando Rostos Sintéticos: Como Conjuntos de Dados Sintéticos Podem Expor Identidades Reais, e vem de dois pesquisadores do Instituto Idiap em Martigny, da École Polytechnique Fédérale de Lausanne (EPFL) e da Université de Lausanne (UNIL) em Lausanne.
Método, Dados e Resultados
Os rostos memorizados no estudo foram revelados por Ataque de Inferência de Membro. Embora o conceito soe complicado, é bastante autoexplicativo: inferir a pertença, neste caso, refere-se ao processo de questionar um sistema até que ele revele dados que correspondem ou se assemelham significativamente àqueles que você está procurando.

Outros exemplos de fontes de dados inferidos, do estudo. Neste caso, as imagens sintéticas de origem são do conjunto de dados DCFace.
Os pesquisadores estudaram seis conjuntos de dados sintéticos para os quais a origem do conjunto de dados (real) era conhecida. Como tanto os conjuntos de dados reais quanto os sintéticos em questão contêm um volume muito alto de imagens, isso é efetivamente como procurar uma agulha em um palheiro.
Portanto, os autores usaram um modelo de reconhecimento facial que já existe † com uma ResNet100 treinado na AdaFace função de perda (no conjunto de dados WebFace12M).
Os seis conjuntos de dados sintéticos utilizados foram: DCFace (um modelo de difusão latente); IDiff-Face (Uniforme – um modelo de difusão baseado em FFHQ); IDiff-Face (Dois estágios – uma variante utilizando um método de amostragem diferente); GANDiffFace (baseado em Redes Generativas Adversariais e modelos de difusão, utilizando StyleGAN3 para gerar identidades iniciais, e depois DreamBooth para criar exemplos variados); IDNet (um método GAN, baseado no StyleGAN-ADA); e SFace (uma estrutura que protege identidades).
Como o GANDiffFace utiliza métodos de GAN e de difusão, ele foi comparado ao conjunto de dados de treinamento do StyleGAN – o mais próximo de uma origem ‘rosto real’ que essa rede oferece.
Os autores excluíram conjuntos de dados sintéticos que usam CGI em vez de métodos de IA e, na avaliação de resultados, descontaram correspondências para crianças, devido a anomalias de distribuição a esse respeito, assim como imagens que não são de rostos (que podem frequentemente ocorrer em conjuntos de dados de rostos, onde sistemas de raspagem da web produzem falsos positivos para objetos ou artefatos que têm qualidades semelhantes a rostos).
Foi calculada a similaridade cosseno para todos os pares recuperados e concatenada em histogramas, ilustrados abaixo:
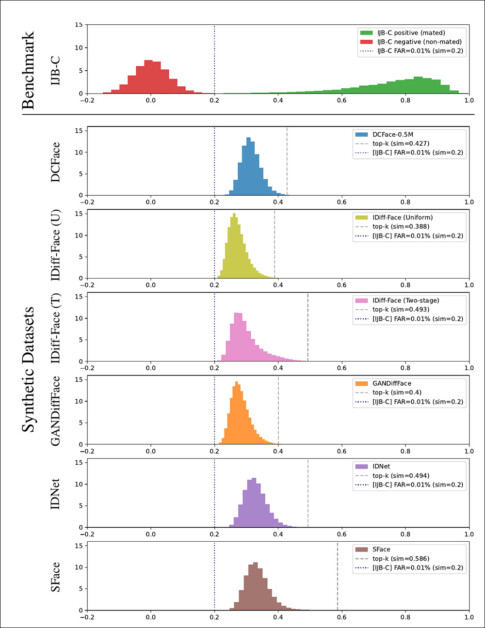
Uma representação histográfica para pontuações de similaridade cosseno calculadas em diferentes conjuntos de dados, juntamente com seus valores relacionados de similaridade para os melhores pares (linhas verticais tracejadas).
A quantidade de similaridades é representada pelos picos no gráfico acima. O artigo também apresenta comparações de amostra dos seis conjuntos de dados e suas respectivas imagens estimadas nos conjuntos de dados originais (reais), de cujas seleções algumas estão destacadas abaixo:

Exemplos de muitas instâncias reproduzidas no artigo fonte, para a qual o leitor é referenciado para uma seleção mais abrangente.
O paper comenta:
‘[Os] conjuntos de dados sintéticos gerados contêm imagens muito semelhantes do conjunto de dados de treinamento de seu modelo gerador, o que levanta preocupações quanto à geração de tais identidades.’
Os autores observam que para essa abordagem específica, escalar para conjuntos de dados de maior volume provavelmente será ineficiente, pois a computação necessária seria extremamente onerosa. Eles observam ainda que a comparação visual foi necessária para inferir correspondências, e que o reconhecimento facial automatizado sozinho provavelmente não seria suficiente para uma tarefa maior.
Sobre as implicações da pesquisa e com um olhar para os caminhos à frente, o trabalho afirma:
‘[Gostaríamos] de destacar que a principal motivação para gerar conjuntos de dados sintéticos é abordar preocupações de privacidade no uso de conjuntos de dados de rostos coletados na web em larga escala.
‘Portanto, a vazamento de qualquer informação sensível (como identidades das imagens reais nos dados de treinamento) no conjunto de dados sintético provoca preocupações críticas em relação à aplicação de dados sintéticos em tarefas sensíveis à privacidade, como biometria. Nosso estudo ilumina as armadilhas de privacidade na geração de conjuntos de dados de reconhecimento facial sintético e pavimenta o caminho para estudos futuros sobre a geração de conjuntos de dados faciais sintéticos responsáveis.’
Embora os autores prometam um lançamento de código para este trabalho na página do projeto, não há atualmente um link de repositório.
Conclusão
Ultimamente, a atenção da mídia enfatizou os retornos decrescentes obtidos ao treinar modelos de IA com dados gerados por IA.
No entanto, a nova pesquisa suíça traz para o foco uma consideração que pode ser mais urgente para o número crescente de empresas que desejam aproveitar e lucrar com a IA generativa – a persistência de padrões de dados protegidos por IP ou não autorizados, mesmo em conjuntos de dados que são projetados para combater essa prática. Se tivéssemos que dar uma definição, neste caso, isso poderia ser chamado de ‘lavagem facial’.
* No entanto, a decisão da Adobe de permitir imagens geradas por IA carregadas por usuários no Adobe Stock efetivamente undermining a ‘pureza’ legal destes dados. A Bloomberg argumentou em abril de 2024 que imagens fornecidas por usuários do sistema de IA generativa MidJourney haviam sido incorporadas nas capacidades do Firefly.
† Este modelo não é identificado no paper.
Publicado pela primeira vez na quarta-feira, 6 de novembro de 2024



Conteúdo relacionado

Sora da OpenAI agora está disponível GRATUITAMENTE para todos os usuários através do Criador de Vídeos do Microsoft Bing no mobile.
[the_ad id="145565"] Here's the rewritten content in Portuguese, maintaining the HTML tags: <div> <div id="boilerplate_2682874" class="post-boilerplate…

Salesforce compra a Moonhub, uma startup desenvolvendo ferramentas de IA para recrutamento.
[the_ad id="145565"] Atualizado às 13h13, horário do Pacífico: Um porta-voz da Salesforce disse ao TechCrunch que a Moonhub não foi adquirida, de fato, pela definição da…

Plataforma de chatbot Character.AI lança geração de vídeos e feeds sociais
[the_ad id="145565"] Uma plataforma para conversar e fazer jogos de interpretação com personagens gerados por IA, a Character.AI anunciou em um post no blog na segunda-feira…