


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder na indústria. Descubra mais
A introdução do ChatGPT trouxe os modelos de linguagem de grande escala (LLMs) para o uso generalizado em setores tanto tecnológicos quanto não tecnológicos. Essa popularidade se deve principalmente a dois fatores:
- LLMs como um repositório de conhecimento: Os LLMs são treinados com uma vasta quantidade de dados da internet e são atualizados em intervalos regulares (ou seja, GPT-3, GPT-3.5, GPT-4, GPT-4o, entre outros);
- Habilidades emergentes: À medida que os LLMs crescem, eles exibem habilidades que não são encontradas em modelos menores.
Isso significa que já atingimos a inteligência em nível humano, que chamamos de inteligência geral artificial (AGI)? A Gartner define AGI como uma forma de IA que possui a capacidade de entender, aprender e aplicar conhecimento em uma ampla gama de tarefas e domínios. O caminho para a AGI é longo, com um dos principais obstáculos sendo a natureza auto-regressiva do treinamento de LLM, que prevê palavras com base em sequências passadas. Como um dos pioneiros na pesquisa em IA, Yann LeCun aponta que os LLMs podem se afastar de respostas precisas devido à sua natureza auto-regressiva. Consequentemente, os LLMs apresentam várias limitações:
- Conhecimento limitado: Embora treinados com dados vastos, os LLMs carecem de conhecimento atualizado sobre o mundo.
- Raciocínio limitado: Os LLMs têm uma capacidade de raciocínio restrita. Como aponta Subbarao Kambhampati os LLMs são bons na recuperação de conhecimento, mas não são bons em raciocínio.
- Sem Dinamicidade: Os LLMs são estáticos e incapazes de acessar informações em tempo real.
Para superar os desafios dos LLMs, é necessária uma abordagem mais avançada. É aqui que os agentes se tornam cruciais.
Agentes para o resgate
O conceito de agente inteligente em IA evoluiu ao longo de duas décadas, com implementações mudando ao longo do tempo. Hoje, os agentes são discutidos no contexto dos LLMs. Simplificando, um agente é como uma canivete suíço para os desafios dos LLMs: pode nos ajudar no raciocínio, fornecer meios para obter informações atualizadas da Internet (resolvendo problemas de dinamicidade com LLM) e pode realizar uma tarefa de forma autônoma. Com o LLM servindo como sua espinha dorsal, um agente formalmente compreende ferramentas, memória, raciocínio (ou planejamento) e componentes de ação.
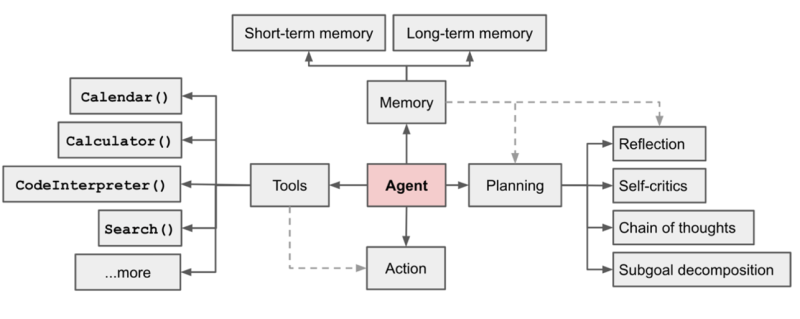
Componentes dos agentes de IA
- Ferramentas permitem que os agentes acessem informações externas — seja da internet, de bancos de dados ou APIs — permitindo-lhes reunir os dados necessários.
- A memória pode ser de curto ou longo prazo. Os agentes usam memória temporária para reter resultados de várias fontes, enquanto o histórico de conversa é um exemplo de memória a longo prazo.
- O Raciocinador permite que os agentes pensem de maneira metódica, dividindo tarefas complexas em subtarefas gerenciáveis para um processamento eficaz.
- Ações: Os agentes realizam ações com base em seu ambiente e raciocínio, adaptando-se e resolvendo tarefas de forma iterativa por meio de feedback. O ReAct é um dos métodos comuns para realizar razão e ação iterativamente.
Em que os agentes se destacam?
Os agentes se destacam em tarefas complexas, especialmente quando estão em modo de interpretação de papéis, aproveitando o desempenho aprimorado dos LLMs. Por exemplo, ao escrever um blog, um agente pode se concentrar na pesquisa enquanto outro lida com a escrita — cada um abordando um subobjetivo específico. Essa abordagem de múltiplos agentes se aplica a numerosos problemas da vida real.
A interpretação de papéis ajuda os agentes a se manterem concentrados em tarefas específicas para atingir objetivos maiores, reduzindo ilusões ao definir claramente partes de um prompt — como papel, instrução e contexto. Como o desempenho do LLM depende de prompts bem estruturados, várias estruturas formalizam esse processo. Uma dessas estruturas, o CrewAI, fornece uma abordagem estruturada para definir a interpretação de papéis, que discutiremos a seguir.
Múltiplos agentes vs agente único
Tome o exemplo da geração aumentada por recuperação (RAG) usando um único agente. É uma maneira eficaz de capacitar os LLMs a lidarem com consultas específicas de domínio ao explorar informações de documentos indexados. No entanto, o RAG de agente único vem com suas próprias limitações, como desempenho de recuperação ou classificação de documentos. O RAG multi-agente supera essas limitações empregando agentes especializados para compreensão de documentos, recuperação e classificação.
Em um cenário de múltiplos agentes, os agentes colaboram de maneiras diferentes, semelhantes aos padrões de computação distribuída: sequenciais, centralizados, descentralizados ou pools de mensagens compartilhadas. Estruturas como CrewAI, Autogen e langGraph+langChain permitem uma resolução complexa de problemas com abordagens de múltiplos agentes. Neste artigo, utilizei o CrewAI como referência para explorar a gestão de fluxo de trabalho autônoma.
Gestão de fluxo de trabalho: Um caso de uso para sistemas de múltiplos agentes
A maioria dos processos industriais envolve a gestão de fluxos de trabalho, seja no processamento de empréstimos, gestão de campanhas de marketing ou até mesmo DevOps. Etapas, sejam sequenciais ou cíclicas, são necessárias para atingir um objetivo particular. Em uma abordagem tradicional, cada etapa (como a verificação de aplicação de empréstimos) exige que um humano realize a tediosa e monótona tarefa de processar manualmente cada aplicação e verificá-las antes de passar para a próxima etapa.
Cada passo requer a contribuição de um especialista na área. Em uma configuração de múltiplos agentes usando CrewAI, cada passo é tratado por uma equipe composta por vários agentes. Por exemplo, na verificação de aplicação de empréstimos, um agente pode verificar a identidade do usuário por meio de verificações de fundo em documentos como a carteira de motorista, enquanto outro agente verifica os detalhes financeiros do usuário.
Isso levanta a questão: uma única equipe (com múltiplos agentes em sequência ou hierarquia) pode lidar com todos os passos do processamento de empréstimos? Embora seja possível, isso complica a equipe, exigindo uma memória temporária extensa e aumentando o risco de desvio de objetivo e alucinação. Uma abordagem mais eficaz é tratar cada etapa do processamento de empréstimos como uma equipe separada, visualizando todo o fluxo de trabalho como um grafo de nós de equipe (usando ferramentas como langGraph) operando sequencialmente ou ciclicamente.
Como os LLMs ainda estão em estágios iniciais de inteligência, a gestão de fluxos de trabalho completos não pode ser totalmente autônoma. Um humano no ciclo é necessário em etapas-chave para verificação do usuário final. Por exemplo, após a equipe concluir a etapa de verificação da aplicação de empréstimos, a supervisão humana é necessária para validar os resultados. Com o tempo, à medida que a confiança na IA cresce, algumas etapas podem se tornar totalmente autônomas. No momento, a gestão de fluxo de trabalho baseada em IA funciona em um papel assistivo, agilizando tarefas tediosas e reduzindo o tempo de processamento geral.
Desafios de produção
Implementar soluções multi-agente na produção pode apresentar vários desafios.
- Escala: À medida que o número de agentes cresce, colaboração e gestão se tornam desafiadoras. Várias estruturas oferecem soluções escaláveis — por exemplo, Llamaindex adota fluxos de trabalho orientados por eventos para gerenciar múltiplos agentes em escala.
- Latência: O desempenho do agente muitas vezes acarreta latência, uma vez que as tarefas são executadas iterativamente, exigindo múltiplas chamadas de LLM. LLMs gerenciados (como GPT-4o) são lentos devido a barreiras implícitas e atrasos na rede. LLMs auto-hospedados (com controle de GPU) são úteis para resolver problemas de latência.
- Desempenho e problemas de alucinação: Devido à natureza probabilística dos LLMs, o desempenho do agente pode variar a cada execução. Técnicas como modelagem de saída (como o formato JSON) e fornecer exemplos suficientes em prompts podem ajudar a reduzir a variabilidade de respostas. O problema da alucinação pode ser ainda mais reduzido treinando agentes.
Considerações finais
Como Andrew Ng aponta, os agentes são o futuro da IA e continuarão a evoluir junto com os LLMs. Sistemas multi-agente avançarão no processamento de dados multimodais (texto, imagens, vídeo, áudio) e na abordagem de tarefas cada vez mais complexas. Enquanto a AGI e sistemas totalmente autônomos ainda estão no horizonte, os multi-agentes servirão de ponte entre os LLMs e a AGI.
Abhishek Gupta é cientista principal de dados na Talentica Software.
DataDecisionMakers
Bem-vindo à comunidade VentureBeat!
DataDecisionMakers é onde especialistas, incluindo aqueles que trabalham com dados, podem compartilhar insights e inovações relacionadas a dados.
Se você deseja ler sobre ideias inovadoras e informações atualizadas, melhores práticas e o futuro dos dados e das tecnologias de dados, junte-se a nós no DataDecisionMakers.
Você pode até considerar contribuir com um artigo próprio!
Leia mais do DataDecisionMakers

Conteúdo relacionado

Sora da OpenAI agora está disponível GRATUITAMENTE para todos os usuários através do Criador de Vídeos do Microsoft Bing no mobile.
[the_ad id="145565"] Here's the rewritten content in Portuguese, maintaining the HTML tags: <div> <div id="boilerplate_2682874" class="post-boilerplate…

Salesforce compra a Moonhub, uma startup desenvolvendo ferramentas de IA para recrutamento.
[the_ad id="145565"] Atualizado às 13h13, horário do Pacífico: Um porta-voz da Salesforce disse ao TechCrunch que a Moonhub não foi adquirida, de fato, pela definição da…

Plataforma de chatbot Character.AI lança geração de vídeos e feeds sociais
[the_ad id="145565"] Uma plataforma para conversar e fazer jogos de interpretação com personagens gerados por IA, a Character.AI anunciou em um post no blog na segunda-feira…