


Inscreva-se em nossas newsletters diárias e semanais para receber as últimas atualizações e conteúdos exclusivos sobre inteligência artificial de ponta. Saiba Mais
Os avanços em modelos de linguagem de grande escala (LLMs) reduziram as barreiras para a criação de aplicações de aprendizado de máquina. Com instruções simples e técnicas de engenharia de prompts, você pode fazer com que um LLM execute tarefas que, de outra forma, exigiriam o treinamento de modelos de aprendizado de máquina personalizados. Isso é especialmente útil para empresas que não possuem talentos e infraestrutura de aprendizado de máquina internos, ou para gerentes de produto e engenheiros de software que desejam criar seus próprios produtos alimentados por IA.
No entanto, os benefícios dos modelos fáceis de usar não vêm sem desvantagens. Sem uma abordagem sistemática para acompanhar o desempenho dos LLMs em suas aplicações, as empresas podem acabar obtendo resultados mistos e instáveis.
Benchmarks públicos vs evals personalizados
A maneira popular atual de avaliar LLMs é medir seu desempenho em benchmarks gerais, como MMLU, MATH e GPQA. Os laboratórios de IA frequentemente divulgam o desempenho de seus modelos nesses benchmarks, e os rankings online classificam os modelos com base em suas pontuações de avaliação. Mas, enquanto essas avaliações medem as capacidades gerais dos modelos em tarefas como perguntas e respostas e raciocínio, a maioria das aplicações empresariais quer medir o desempenho em tarefas muito específicas.
“As avaliações públicas são principalmente um método para os criadores de modelos de base divulgarem os méritos relativos de seus modelos,” disse Ankur Goyal, cofundador e CEO da Braintrust, à VentureBeat. “Mas quando uma empresa está construindo software com IA, a única coisa que importa é se esse sistema de IA realmente funciona ou não. E basicamente não há nada que você possa transferir de um benchmark público para isso.”
Em vez de confiar em benchmarks públicos, as empresas precisam criar evals personalizados com base em seus próprios casos de uso. As avaliações normalmente envolvem apresentar ao modelo um conjunto de entradas ou tarefas meticulosamente elaboradas e, em seguida, medir suas saídas de acordo com critérios predefinidos ou referências geradas por humanos. Essas avaliações podem cobrir vários aspectos, como o desempenho específico da tarefa.
A forma mais comum de criar uma eval é capturar dados reais de usuários e formatá-los em testes. As organizações podem então usar essas avaliações para simular suas aplicações e as alterações que realizam nelas.
“Com evals personalizados, você não está testando o modelo em si. Você está testando seu próprio código, que talvez pegue a saída de um modelo e a processe ainda mais,” disse Goyal. “Você está testando seus prompts, que é provavelmente a coisa mais comum que as pessoas estão ajustando, tentando refinar e melhorar. E você está testando as configurações e a forma como usa os modelos juntos.”
Como criar evals personalizados
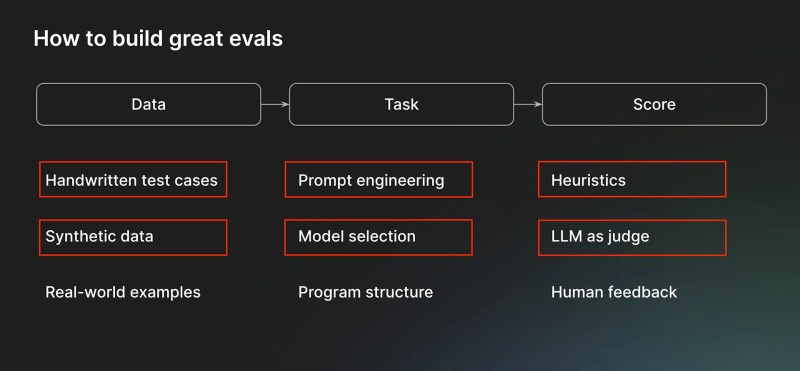
Para criar uma boa eval, cada organização deve investir em três componentes-chave. O primeiro é o dado usado para criar os exemplos que testam a aplicação. Os dados podem ser exemplos escritos à mão criados pelos funcionários da empresa, dados sintéticos gerados com a ajuda de modelos ou ferramentas de automação, ou dados coletados de usuários finais, como chats e tickets.
“Exemplos escritos à mão e dados de usuários finais são dramaticamente melhores do que dados sintéticos,” disse Goyal. “Mas se você conseguir descobrir truques para gerar dados sintéticos, pode ser eficaz.”
O segundo componente é a tarefa em si. Ao contrário das tarefas genéricas que os benchmarks públicos representam, as evals personalizadas das aplicações empresariais fazem parte de um ecossistema mais amplo de componentes de software. Uma tarefa pode ser composta por várias etapas, cada uma com suas próprias técnicas de engenharia de prompts e seleção de modelos. Também pode haver outros componentes que não sejam LLM envolvidos. Por exemplo, você pode primeiro classificar um pedido entrante em uma de várias categorias, em seguida, gerar uma resposta com base na categoria e no conteúdo do pedido e, finalmente, fazer uma chamada de API para um serviço externo para concluir o pedido. É importante que a eval compreenda toda a estrutura.
“O importante é estruturar seu código de modo que você possa chamar ou invocar sua tarefa em suas evals da mesma forma que ela opera em produção,” disse Goyal.
O componente final é a função de pontuação que você usa para avaliar os resultados de sua estrutura. Existem dois tipos principais de funções de pontuação. Heurísticas são funções baseadas em regras que podem verificar critérios bem definidos, como testar um resultado numérico contra a verdade fundamental. Para tarefas mais complexas, como geração de texto e resumo, você pode usar métodos LLM-como-juiz, que solicitam a um modelo de linguagem forte que avalie o resultado. LLM-como-juiz requer engenharia de prompts avançada.
“LLM-como-juiz é difícil de acertar e há muitos equívocos a esse respeito,” disse Goyal. “Mas a principal percepção é que, assim como acontece com problemas matemáticos, é mais fácil validar se a solução está correta do que realmente resolver o problema você mesmo.”
A mesma regra se aplica aos LLMs. É muito mais fácil para um LLM avaliar um resultado produzido do que fazer a tarefa original. Isso só requer o prompt certo.
“Normalmente, o desafio da engenharia é iterar sobre a redação ou o prompting para fazê-lo funcionar bem,” disse Goyal.
Inovando com evals fortes
O cenário dos LLMs está evoluindo rapidamente e os fornecedores estão constantemente lançando novos modelos. As empresas quererão atualizar ou mudar seus modelos à medida que os antigos forem descontinuados e novos forem disponibilizados. Um dos principais desafios é garantir que sua aplicação permaneça consistente quando o modelo subjacente mudar.
Com boas evals implementadas, mudar o modelo subjacente se torna tão simples quanto executar os novos modelos em seus testes.
“Se você tem boas evals, então trocar de modelo é tão fácil que é realmente divertido. E se você não tiver evals, então é horrível. A única solução é ter evals,” disse Goyal.
Outro problema é a mudança de dados que o modelo enfrenta no mundo real. À medida que o comportamento do cliente muda, as empresas precisarão atualizar suas evals. Goyal recomenda implementar um sistema de “pontuação online” que execute continuamente evals em dados reais de clientes. Essa abordagem permite que as empresas avaliem automaticamente o desempenho de seu modelo nos dados mais atuais e incorporem novos exemplos relevantes em seus conjuntos de avaliação, garantindo a continuidade e eficácia das suas aplicações LLM.
À medida que os modelos de linguagem continuam a remodelar o cenário do desenvolvimento de software, adotar novos hábitos e metodologias torna-se crucial. Implementar evals personalizados representa mais do que apenas uma prática técnica; é uma mudança de mentalidade em direção a um desenvolvimento rigoroso e orientado por dados na era da IA. A capacidade de avaliar e refinar sistematicamente soluções alimentadas por IA será um diferenciador chave para empresas de sucesso.

Conteúdo relacionado

Runway, conhecida por seus modelos de IA para geração de vídeo, arrecada R$ 308 milhões.
[the_ad id="145565"] Runway, uma startup que desenvolve uma variedade de modelos de IA generativa para a produção de mídia, incluindo modelos de geração de vídeo, levantou US$…

Plataforma de IA de Voz Phonic recebe apoio da Lux
[the_ad id="145565"] A qualidade das vozes geradas por IA é suficientemente boa para criar audiolivros e podcasts, ler artigos em voz alta e oferecer suporte ao cliente básico.…

Como Claude Pensa? A Busca da Anthropic para Desvendar a Caixa-preta da IA
[the_ad id="145565"] Modelos de linguagem de grande escala (LLMs) como Claude mudaram a maneira como usamos a tecnologia. Eles alimentam ferramentas como chatbots, ajudam a…