


Pergunte a qualquer um na comunidade de IA de código aberto, e eles te dirão que a diferença entre eles e as grandes empresas privadas vai além do poder de computação. A AI2 está trabalhando para resolver isso, começando com bancos de dados e modelos totalmente de código aberto, e agora com um regime de pós-treinamento aberto e facilmente adaptável para transformar modelos de linguagem em “bruto” em modelos utilizáveis.
Contrário ao que muitos pensam, os modelos de linguagem “fundamentais” não saem do processo de treinamento prontos para serem utilizados. O processo de pré-treinamento é necessário, é claro, mas está longe de ser suficiente. Alguns acreditam até que o pré-treinamento pode não ser mais a parte mais importante em breve.
Isso porque o processo de pós-treinamento está cada vez mais demonstrando ser onde o verdadeiro valor pode ser criado. É nesse estágio que o modelo é moldado a partir de uma enorme rede que sabe tudo, que pode gerar desde pontos de vista de negação do Holocausto até receitas de biscoitos. Geralmente, você não quer isso!
As empresas são secretivas sobre seus regimes de pós-treinamento porque, embora qualquer um possa fazer scraping da web e criar um modelo usando métodos avançados, tornar esse modelo útil, por exemplo, para um terapeuta ou analista de pesquisa é um desafio completamente diferente.
A AI2 (anteriormente conhecida como Allen Institute for AI) se manifestou sobre a falta de transparência em projetos de IA supostamente “abertos”, como o Llama da Meta. Embora o modelo seja realmente gratuito para qualquer um usar e modificar, as fontes e o processo de criação do modelo bruto, assim como o método de treinamento para uso geral, permanecem segredos cuidadosamente guardados. Não é ruim — mas também não é realmente “aberto”.
A AI2, por outro lado, está comprometida em ser tão aberta quanto possível, expondo sua coleta de dados, curadoria, limpeza e outros fluxos de trabalho, além dos métodos de treinamento que usou para produzir LLMs como o OLMo.
Mas a simples verdade é que poucos desenvolvedores têm a habilidade necessária para rodar seus próprios LLMs desde o início, e ainda menos conseguem fazer o pós-treinamento da mesma forma que a Meta, OpenAI ou Anthropic — em parte porque não sabem, mas também porque é tecnicamente complexo e demorado.
Felizmente, a AI2 quer democratizar esse aspecto do ecossistema de IA também. É aí que entra o Tulu 3. É uma grande melhoria em relação a um processo de pós-treinamento anterior, mais rudimentar (chamado, você adivinhou, Tulu 2); nos testes da organização sem fins lucrativos, isso resultou em pontuações comparáveis aos modelos “abertos” mais avançados disponíveis. É baseado em meses de experimentação, leitura e interpretação do que os grandes estão sugerindo, além de muitas rodadas de treinamento iterativas.
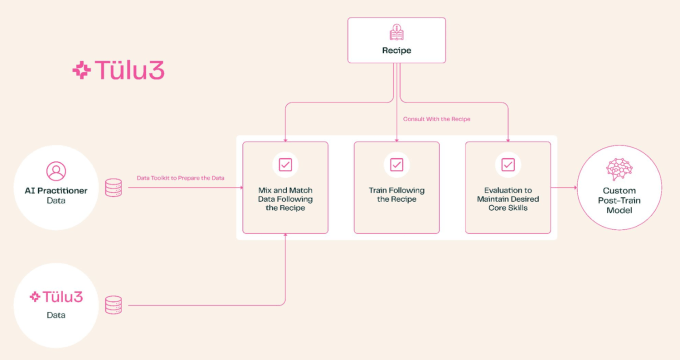
Basicamente, o Tulu 3 cobre tudo, desde escolher quais tópicos você quer que seu modelo se preocupe — por exemplo, desvalorizando as capacidades multilíngues, mas aumentando a matemática e a programação — e então passa por um longo regime de curadoria de dados, aprendizado por reforço, ajuste fino e ajuste de preferências, além de ajustes de vários outros meta-parâmetros e processos de treinamento que eu não conseguiria descrever adequadamente para você. O resultado é, espera-se, um modelo muito mais capaz focado nas habilidades que você precisa que ele tenha.
O ponto real, no entanto, é tirar mais um brinquedo da caixa de brinquedos das empresas privadas. Anteriormente, se você quisesse construir um LLM treinado de forma personalizada, era muito difícil evitar o uso dos recursos de uma grande empresa de alguma forma, ou contratar um intermediário que fizesse o trabalho por você. Isso não só é caro, mas também introduz riscos que algumas empresas relutam em correr.
Por exemplo, empresas de pesquisa e serviços médicos: claro, você poderia usar a API da OpenAI, ou conversar com a Scale ou quem quer que seja para customizar um modelo interno, mas ambos envolvem empresas externas em dados sensíveis dos usuários. Se for inevitável, você só pode engolir em seco — mas se não for? Como se, por exemplo, uma organização de pesquisa lançasse um regime de pré e pós-treinamento completo que você poderia implementar localmente? Essa pode ser uma alternativa melhor.
A AI2 está usando isso ela mesma, o que é o melhor endosse que se pode dar. Mesmo que os resultados dos testes que está publicando hoje usem o Llama como modelo base, eles planejam lançar em breve um modelo baseado no OLMo, treinado pela Tulu-3, que deverá oferecer ainda mais melhorias em relação à linha de base e também ser totalmente de código aberto, do início ao fim.
Se você está curioso sobre como o modelo está se saindo atualmente, faça uma demonstração ao vivo.

Conteúdo relacionado

A OpenAI busca reunir um grupo para aconselhar sobre seus objetivos sem fins lucrativos.
[the_ad id="145565"] Enquanto se prepara para fazer a transição de uma corporação sem fins lucrativos para uma com fins lucrativos, a OpenAI afirma que está convenindo um grupo…

Como a Amex utiliza IA para aumentar a eficiência: 40% menos escalonamentos de TI e 85% de aumento na assistência ao viajante.
[the_ad id="145565"] Participe das nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba mais A…

O modelo o3 da OpenAI pode ser mais caro de operar do que originalmente estimado.
[the_ad id="145565"] Quando a OpenAI revelou seu modelo de IA “reasoning” o3 em dezembro, a empresa se uniu aos criadores do ARC-AGI, um benchmark projetado para testar IAs…