


A grande esperança para os modelos de IA de linguagem-visual é que um dia eles se tornem capazes de maior autonomia e versatilidade, incorporando princípios das leis físicas da mesma forma que desenvolvemos um entendimento inato dessas regras através da experiência inicial.
Por exemplo, os jogos de bola das crianças tendem a desenvolver uma compreensão da cinética do movimento, e do efeito do peso e da textura da superfície na trajetória. Da mesma forma, interações com cenários comuns como banhos, bebidas derramadas, o oceano, piscinas e outros corpos líquidos diversos nos instilam uma compreensão versátil e escalável de como os líquidos se comportam sob a gravidade.
Até mesmo os postulados de fenômenos menos comuns – como combustão, explosões e distribuição de peso arquitetônica sob pressão – são absorvidos inconscientemente através da exposição à programas de TV e filmes, ou vídeos nas redes sociais.
Quando chegamos a estudar os princípios por trás desses sistemas, em um nível acadêmico, estamos apenas ‘retrocedendo’ nossos modelos mentais intuitivos (mas desinformados) sobre eles.
Mestres de Um
Atualmente, a maioria dos modelos de IA são, em contraste, mais ‘especializados’, e muitos deles são ajustados ou treinados do zero em conjuntos de dados de imagem ou vídeo que são bastante específicos para certos casos de uso, em vez de serem projetados para desenvolver uma compreensão geral das leis que governam.
Outros podem apresentar a aparência de compreensão das leis físicas; mas eles podem estar reproduzindo amostras de seus dados de treinamento, em vez de realmente entender os fundamentos de áreas como a física do movimento de uma maneira que possa produzir representações verdadeiramente novas (e cientificamente plausíveis) a partir dos prompts dos usuários.
Neste momento delicado na produção e comercialização de sistemas de IA generativa, cabe a nós, e ao escrutínio dos investidores, distinguir o marketing elaborado de novos modelos de IA da realidade de suas limitações.
Um dos papers mais interessantes de novembro, liderado pela Bytedance Research, abordou essa questão, explorando a lacuna entre as capacidades aparentes e reais de modelos generativos ‘universais’ como o Sora.
O trabalho concluiu que, no estado atual da arte, a saída gerada por modelos desse tipo tem mais probabilidade de estar imitando exemplos de seus dados de treinamento do que realmente demonstrando uma compreensão completa das restrições físicas subjacentes que operam no mundo real.
O paper afirma*:
‘[Esses] modelos podem ser facilmente enviesados por exemplos “enganadores” do conjunto de treinamento, levando-os a generalizar de maneira “baseada em casos” em determinadas condições. Esse fenômeno, também observado em grandes modelos de linguagem, descreve a tendência de um modelo em referenciar casos de treinamento similares ao resolver novas tarefas.
‘Por exemplo, considere um modelo de vídeo treinado com dados de uma bola em alta velocidade movendo-se em movimento linear uniforme. Se uma augmentação de dados for realizada ao inverter horizontalmente os vídeos, introduzindo assim movimento na direção oposta, o modelo pode gerar um cenário onde uma bola de baixa velocidade inverte a direção após os primeiros quadros, mesmo que esse comportamento não seja fisicamente correto.’
Vamos dar uma olhada mais de perto no paper – intitulado Avaliando Modelos Mundiais com LLM para Tomada de Decisão – em breve. Mas primeiro, vejamos o contexto para essas aparentes limitações.
Recordação de Coisas Passadas
Sem generalização, um modelo de IA treinado é pouco mais do que uma planilha cara de referências a seções de seus dados de treinamento: encontre o termo de busca apropriado e você pode convocar uma instância daqueles dados.
Nessa situação, o modelo atua efetivamente como um ‘motor de busca neural’, uma vez que não consegue produzir interpretações abstratas ou ‘criativas’ da saída desejada, mas em vez disso replica alguma variação menor dos dados que viu durante o processo de treinamento.
Isso é conhecido como memorização – um problema controverso que surge porque modelos de IA verdadeiramente dúcteis e interpretativos tendem a faltar detalhes, enquanto modelos realmente detalhados tendem a faltar originalidade e flexibilidade.
A capacidade de modelos afetados pela memorização de reproduzir dados de treinamento é um potencial obstáculo legal, em casos onde os criadores do modelo não tinham direitos irrestritos para usar aqueles dados; e onde benefícios provenientes daqueles dados podem ser demonstrados através de um número crescente de métodos de extração.
Por causa da memorização, vestígios de dados não autorizados podem persistir, encadeados, através de vários sistemas de treinamento, como uma marca d’água indelével e não intencional – mesmo em projetos onde o praticante de aprendizado de máquina teve o cuidado de garantir que dados ‘seguros’ sejam utilizados.
Modelos Mundiais
Entretanto, a questão central de uso com a memorização é que ela tende a transmitir a ilusão de inteligência, ou sugerir que o modelo de IA generalizou leis ou domínios fundamentais, quando, na verdade, é o grande volume de dados memorizados que fornece essa ilusão (ou seja, o modelo tem tantos exemplos de dados potenciais para escolher que é difícil para um humano dizer se está regurgitando conteúdo aprendido ou se possui uma compreensão realmente abstrata dos conceitos envolvidos na geração).
Esse problema tem ramificações para o crescente interesse em modelos mundiais – a perspectiva de sistemas de IA altamente diversos e treinados de forma dispendiosa que incorporam múltiplas leis conhecidas e são ricamente exploráveis.
Os modelos mundiais são de particular interesse no espaço de geração de imagens e vídeos. Em 2023, a RunwayML iniciou uma iniciativa de pesquisa para o desenvolvimento e viabilidade de tais modelos; a DeepMind recentemente contratou um dos criadores do aclamado vídeo gerador Sora para trabalhar em um modelo desse tipo; e startups como a Higgsfield estão investindo significativamente em modelos mundiais para síntese de imagem e vídeo.
Combinações Difíceis
Uma das promessas dos novos desenvolvimentos em sistemas de IA generativa de vídeo é a perspectiva de que eles possam aprender leis físicas fundamentais, como movimento, cinemática humana (como características de marcha), dinâmica de fluidos, e outros fenômenos físicos conhecidos que são, pelo menos, visualmente familiares para os humanos.
Se a IA generativa pudesse alcançar esse marco, poderia se tornar capaz de produzir efeitos visuais hiper-realistas que representam explosões, inundações e eventos de colisão plausíveis entre múltiplos tipos de objetos.
Por outro lado, se o sistema de IA foi simplesmente treinado em milhares (ou centenas de milhares) de vídeos retratando tais eventos, ele poderia ser capaz de reproduzir os dados de treinamento de maneira bastante convincente quando treinado em um ponto de dado similar ao alvo do usuário; porém falhar se a consulta combinar muitos conceitos que não estão representados na combinação.
Além disso, essas limitações não seriam imediatamente aparentes, até que alguém testasse o sistema com combinações desafiadoras desse tipo.
Isso significa que um novo sistema generativo pode ser capaz de gerar conteúdo de vídeo viral que, embora impressionante, pode criar uma falsa impressão das capacidades e da profundidade de compreensão do sistema, pois a tarefa que representa não é um verdadeiro desafio para o sistema.
Por exemplo, um evento relativamente comum e bem difundido, como ‘um edifício é demolido’, pode estar presente em vários vídeos em um conjunto de dados usado para treinar um modelo que supostamente tem alguma compreensão da física. Portanto, o modelo poderia presumivelmente generalizar bem esse conceito, e até produzir resultados genuinamente novos dentro dos parâmetros aprendidos a partir de vídeos abundantes.
Esse é um exemplo in-distribution, onde o conjunto de dados contém muitos exemplos úteis para o sistema de IA aprender.
No entanto, se alguém solicitasse um exemplo mais bizarro ou especioso, como ‘A Torre Eiffel é explodida por invasores alienígenas’, o modelo teria que combinar domínios diversos como ‘propriedades metalúrgicas’, ‘características de explosões’, ‘gravidade’, ‘resistência do vento’ – e ‘naves espaciais alienígenas’.
Esse é um exemplo out-of-distribution (OOD), que combina tantos conceitos entrelaçados que o sistema provavelmente falhará em gerar um exemplo convincente ou recorrerá ao exemplo semântico mais próximo que foi treinado – mesmo que esse exemplo não atenda ao prompt do usuário.
Exceto se o conjunto de dados de origem do modelo contiver VFX de estilo CGI de Hollywood retratando o mesmo ou um evento similar, tal representação exigiria que ele alcançasse uma compreensão bem generalizada e dúctil das leis físicas.
Restrições Físicas
O novo paper – uma colaboração entre Bytedance, a Universidade Tsinghua e o Technion – sugere não apenas que modelos como o Sora não realmente internalizam leis físicas determinísticas dessa forma, mas que aumentar a quantidade de dados (uma abordagem comum nos últimos 18 meses) parece, na maioria dos casos, não produzir nenhuma melhoria real nesse sentido.
O paper explora não apenas os limites da extrapolação de leis físicas específicas – como o comportamento de objetos em movimento quando colidem ou quando seu caminho é obstruído – mas também a capacidade de um modelo de generalização combinatória – instâncias em que as representações de dois princípios físicos diferentes são unidas em uma única saída gerativa.
Um resumo em vídeo do novo paper. Fonte: https://x.com/bingyikang/status/1853635009611219019
As três leis físicas selecionadas para estudo pelos pesquisadores foram movimento parabólico; movimento linear uniforme; e colisão perfeitamente elástica.
Como pode ser visto no vídeo acima, os achados indicam que modelos como o Sora não realmente internalizam leis físicas, mas tendem a reproduzir dados de treinamento.
Além disso, os autores descobriram que facetas como cor e forma tornam-se tão entrelaçadas no momento da inferência que uma bola gerada provavelmente se transformaria em um quadrado, aparentemente porque um movimento semelhante em um exemplo do conjunto de dados apresentava um quadrado e não uma bola (veja o exemplo no vídeo embutido acima).
O paper, que notavelmente engajou o setor de pesquisa nas redes sociais, conclui:
‘Nosso estudo sugere que escalar por si só é insuficiente para modelos de geração de vídeo descobrirem leis físicas fundamentais, apesar do seu papel no sucesso mais amplo do Sora…
‘…[As descobertas] indicam que a escalabilidade por si só não pode resolver o problema OOD, embora melhore o desempenho em outros cenários.
‘Nossa análise aprofundada sugere que a generalização de modelos de vídeo depende mais da referência a exemplos de treinamento similares do que do aprendizado de regras universais. Observamos uma ordem de priorização da cor > tamanho > velocidade > forma nesse comportamento “baseado em casos”.
‘[Nosso] estudo sugere que escalar ingenuamente é insuficiente para modelos de geração de vídeo descobrirem leis físicas fundamentais.’
Quando perguntado se a equipe de pesquisa havia encontrado uma solução para a questão, um dos autores do paper comentou:
‘Infelizmente, não encontramos. Na verdade, essa é provavelmente a missão de toda a comunidade de IA.’
Método e Dados
Os pesquisadores utilizaram uma arquitetura de Autoencoder Variacional (VAE) e DiT para gerar amostras de vídeo. Nesse arranjo, as representações latentes comprimidas produzidas pelo VAE trabalham em conjunto com a modelagem do processo de descaracterização do DiT.
Vídeos foram treinados sobre o Stable Diffusion V1.5-VAE. O esquema foi deixado fundamentalmente inalterado, com apenas melhorias arquitetônicas no fim do processo:
‘[Mantemos] a maioria da convolução 2D original, normalização em grupo e mecanismos de atenção nas dimensões espaciais.
‘Para transformar essa estrutura em um autoencoder espaço-temporal, convertemos os últimos blocos de downsample 2D do encoder e os primeiros blocos de upsample 2D do decoder em 3D, e empregamos várias camadas extras 1D para aprimorar a modelagem temporal.’
Para possibilitar a modelagem de vídeo, o VAE modificado foi treinado conjuntamente com dados de imagem e vídeo HQ, com o componente de Rede Adversarial Generativa (GAN) 2D nativo da arquitetura SD1.5 aumentado para 3D.
O conjunto de dados de imagens utilizado foi a fonte original do Stable Diffusion, LAION-Aesthetics, com filtragem, além de DataComp. Para dados de vídeo, um subconjunto foi selecionado a partir dos conjuntos Vimeo-90K, Panda-70m e HDVG.
Os dados foram treinados por um milhão de passos, com corte aleatório redimensionado e inversão horizontal aleatória aplicadas como processos de aumentação de dados.
Inverter
Como mencionado acima, o processo de aumentação de dados de inversão horizontal aleatória pode ser uma desvantagem ao treinar um sistema projetado para produzir movimento autêntico. Isso ocorre porque a saída do modelo treinado pode considerar ambas as direções de um objeto e causar reversões aleatórias enquanto tenta negociar esses dados conflitantes (veja o vídeo embutido acima).
Por outro lado, se a inversão horizontal for desligada, o modelo é então mais provável de produzir uma saída que se adere apenas a uma direção aprendida a partir dos dados de treinamento.
Portanto, não há uma solução fácil para a questão, exceto que o sistema assimile verdadeiramente todas as possibilidades de movimento tanto da versão nativa quanto da invertida – uma habilidade que as crianças desenvolvem com facilidade, mas que é aparentemente um desafio maior para os modelos de IA.
testes
Para o primeiro conjunto de experimentos, os pesquisadores formularam um simulador 2D para produzir vídeos de movimento de objetos e colisões que correspondem às leis da mecânica clássica, que forneceu um alto volume e um conjunto de dados controlado que excluiu as ambiguidades dos vídeos do mundo real, para a avaliação dos modelos. O motor de física Box2D foi usado para criar esses vídeos.
Os três cenários fundamentais listados acima foram o foco dos testes: movimento linear uniforme, colisões perfeitamente elásticas e movimento parabólico.
Conjuntos de dados de tamanhos crescentes (variando de 30.000 a três milhões de vídeos) foram usados para treinar modelos de diferentes tamanhos e complexidades (DiT-S a DiT-L), com os primeiros três quadros de cada vídeo usados para condicionamento.
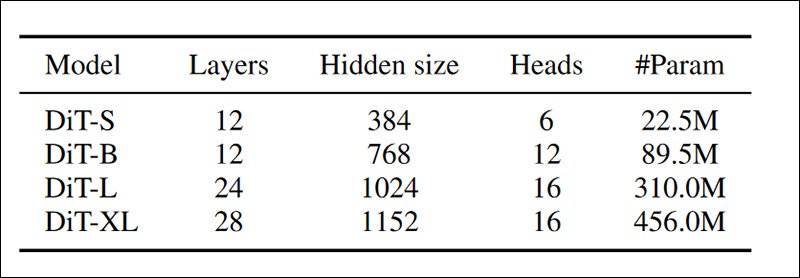
Detalhes dos vários modelos treinados no primeiro conjunto de experimentos. Fonte: https://arxiv.org/pdf/2411.02385
Os pesquisadores descobriram que os resultados in-distribution (ID) escalaram bem com o aumento da quantidade de dados, enquanto as gerações OOD não melhoraram, indicando deficiências na generalização.
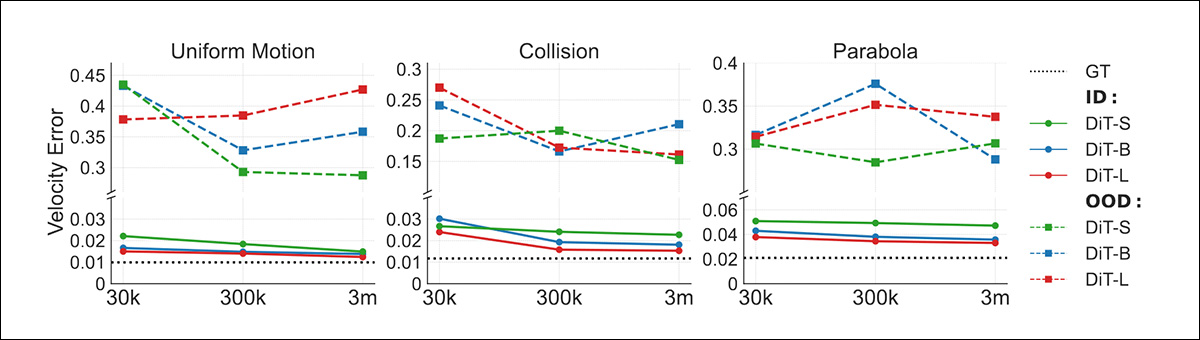
Resultados da primeira rodada de testes.
Os autores observam:
‘Esses achados sugerem a incapacidade da escalabilidade em realizar raciocínio em cenários OOD.’
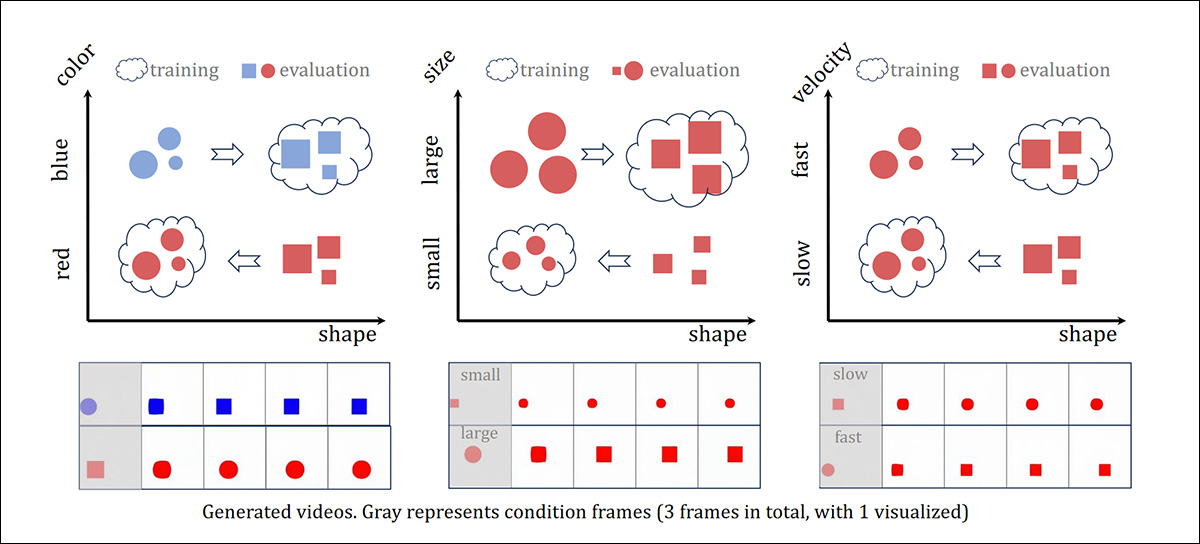
Em seguida, os pesquisadores testaram e treinaram sistemas projetados para exibir proficiência em generalização combinatória, onde dois movimentos contrastantes são combinados para (com esperança) produzir um movimento coeso que é fiel à lei física por trás de cada um dos movimentos separados.
Para esta fase dos testes, os autores utilizaram o simulador PHYRE, criando um ambiente 2D que retrata múltiplos objetos diversamente moldados em queda livre, colidindo entre si em uma variedade de interações complexas.
As métricas de avaliação para este segundo teste foram Distância de Vídeo Fréchet (FVD); Índice de Similaridade Estrutural (SSIM); Relação Sinal-Ruído de Pico (PSNR); Métricas de Similaridade Perceptual Aprendidas (LPIPS); e um estudo humano (denotado como ‘anômalo’ nos resultados).
Três escalas de conjuntos de dados de treinamento foram criadas, com 100.000 vídeos, 0,6 milhão de vídeos e 3-6 milhões de vídeos. Modelos DiT-B e DiT-XL foram utilizados, devido à complexidade aumentada dos vídeos, com o primeiro quadro usado para condicionamento.
Os modelos foram treinados por um milhão de passos na resolução 256×256, com 32 quadros por vídeo.

Resultados da segunda rodada de testes.
O resultado deste teste sugere que simplesmente aumentar o volume de dados é uma abordagem inadequada:
O paper afirma:
‘Esses resultados sugerem que tanto a capacidade do modelo quanto a cobertura do espaço de combinação são cruciais para a generalização combinatória. Essa percepção implica que as leis de escalabilidade para geração de vídeo devem se concentrar em aumentar a diversidade de combinações, em vez de simplesmente aumentar o volume de dados.’
Finalmente, os pesquisadores realizaram mais testes para tentar determinar se um modelo de geração de vídeo pode realmente assimilar leis físicas, ou se simplesmente memoriza e reproduz dados de treinamento no momento da inferência.
Aqui, eles examinaram o conceito de generalização ‘baseada em casos’, onde os modelos tendem a imitar exemplos específicos de treinamento ao enfrentar situações novas, assim como examinar exemplos de movimento uniforme – especificamente como a direção do movimento nos dados de treinamento influencia as previsões do modelo treinado.
Dois conjuntos de dados de treinamento, para movimento uniforme e colisão, foram preparados, cada um consistindo em vídeos de movimento uniforme que retratam velocidades entre 2,5 a 4 unidades, com os primeiros três quadros usados como condicionamento. Valores latentes como velocidade foram omitidos e, após o treinamento, testes foram realizados em cenários conhecidos e desconhecidos.
Abaixo, vemos resultados do teste para geração de movimento uniforme:
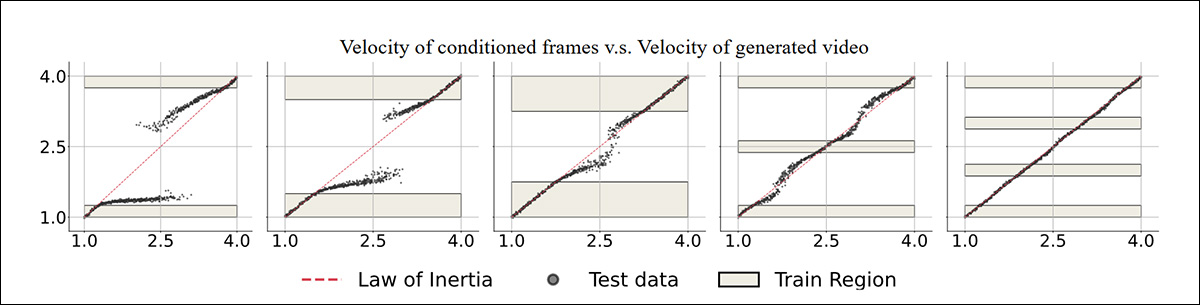
Resultados para testes de geração de movimento uniforme, onde a variável ‘velocidade’ é omitida durante o treinamento.
Os autores afirmam:
‘[Com] uma grande lacuna no conjunto de treinamento, o modelo tende a gerar vídeos onde a velocidade é ou alta ou baixa, para se assemelhar aos dados de treinamento quando os quadros iniciais mostram velocidades em faixa média.’
Para os testes de colisão, muito mais variáveis estão envolvidas, e o modelo deve aprender uma função não linear bidimensional.
Colisão: resultados para a terceira e última rodada de testes.
Os autores observam que a presença de exemplos ‘enganadores’, como movimento reverso (ou seja, uma bola que quica em uma superfície e reverte sua trajetória), pode enganar o modelo e levar a gerar previsões fisicamente incorretas.
Conclusão
Se um algoritmo não-IA (ou seja, um método ‘pré-determinado’) contém regras matemáticas para o comportamento de fenômenos físicos como fluidos, objetos sob gravidade ou sob pressão, existe um conjunto de constantes imutáveis disponíveis para renderização precisa.
No entanto, os achados do novo paper indicam que não se desenvolve tal relação equivalente ou compreensão intrínseca das leis físicas clássicas durante o treinamento de modelos generativos, e que aumentos na quantidade de dados não resolvem o problema, mas sim o obscurecem – pois um maior número de vídeos de treinamento está disponível para o sistema imitar no momento da inferência.
* Minha conversão das citações dos autores em hiperlinks.
Primeira publicação na terça-feira, 26 de novembro de 2024



Conteúdo relacionado

Anthropic enviou um aviso de remoção a um desenvolvedor que tentava reverter o código de sua ferramenta.
[the_ad id="145565"] Na disputa entre duas ferramentas de código "agente" — Claude Code da Anthropic e Codex CLI da OpenAI — a última parece estar promovendo mais boa vontade…

O novo CEO da Intel sinaliza esforços de simplificação, mas não revela números exatos de demissões.
[the_ad id="145565"] Lip-Bu Tan, o novo CEO da Intel, enviou uma mensagem direta aos funcionários, afirmando que a empresa precisa se reorganizar para ser mais eficiente. Ele…

Um pesquisador da OpenAI que trabalhou no GPT-4.5 teve seu green card negado.
[the_ad id="145565"] Kai Chen, um pesquisador de IA canadense que trabalha na OpenAI e mora nos EUA há 12 anos, teve seu pedido de green card negado, de acordo com Noam Brown,…