


Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre cobertura de IA líder na indústria. Saiba Mais
A recente liberação do OpenAI o1 trouxe grande atenção para modelos de raciocínio em larga escala (LRMs) e está inspirando novos modelos destinados a resolver problemas complexos que os clássicos modelos de linguagem frequentemente têm dificuldade. Baseando-se no sucesso do o1 e no conceito de LRMs, pesquisadores da Alibaba introduziram Marco-o1, que aumenta as capacidades de raciocínio e aborda problemas com soluções abertas onde padrões claros e recompensas quantificáveis estão ausentes.
O OpenAI o1 utiliza a “expansão de tempo de inferência” para melhorar a habilidade de raciocínio do modelo ao lhe dar “tempo para pensar”. Basicamente, o modelo usa mais ciclos computacionais durante a inferência para gerar mais tokens e revisar suas respostas, o que melhora seu desempenho em tarefas que exigem raciocínio. O o1 é renomado por suas impressionantes capacidades de raciocínio, especialmente em tarefas com respostas padrão, como matemática, física e programação.
No entanto, muitas aplicações envolvem problemas abertos que carecem de soluções claras e recompensas quantificáveis. “Nosso objetivo era expandir ainda mais os limites dos LLMs, aprimorando suas habilidades de raciocínio para enfrentar desafios complexos do mundo real”, escrevem os pesquisadores da Alibaba.
Marco-o1 é uma versão aprimorada do Qwen2-7B-Instruct da Alibaba que integra técnicas avançadas, como o ajuste fino em cadeia de pensamento (CoT), Busca em Árvore de Monte Carlo (MCTS) e estratégias de ação de raciocínio.
Os pesquisadores treinaram o Marco-o1 em uma combinação de conjuntos de dados, incluindo o Conjunto de Dados Open-O1 CoT; o conjunto de dados CoT do Marco-o1, um conjunto de dados sintético gerado usando MCTS; e o conjunto de dados de Instruções do Marco-o1, uma coleção customizada de dados que seguem instruções para tarefas de raciocínio.
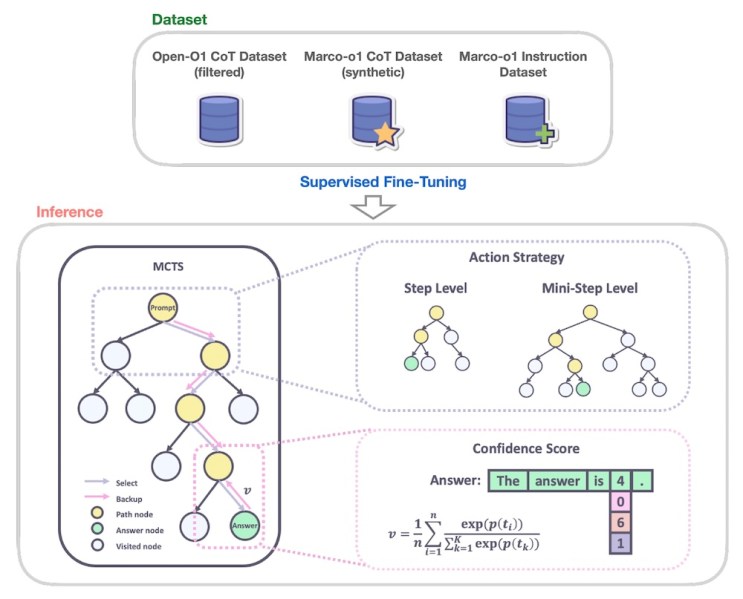
A MCTS é um algoritmo de busca que se mostrou eficaz em cenários complexos de resolução de problemas. Ele explora inteligentemente diferentes caminhos de solução, amostrando repetidamente possibilidades, simulando resultados e construindo gradualmente uma árvore de decisão. Tem se mostrado muito eficaz em problemas complexos de IA, como vencer o jogo Go.
Marco-o1 aproveita a MCTS para explorar múltiplos caminhos de raciocínio à medida que gera tokens de resposta. O modelo utiliza os scores de confiança dos tokens de resposta candidatos para construir sua árvore de decisão e explorar diferentes ramificações. Isso permite que o modelo considere uma gama mais ampla de possibilidades e chegue a conclusões mais informadas e nuançadas, especialmente em cenários com soluções abertas. Os pesquisadores também introduziram uma estratégia de ação de raciocínio flexível que permite ajustar a granularidade dos passos de MCTS definindo o número de tokens gerados em cada nó da árvore. Isso oferece um trade-off entre precisão e custo computacional, dando aos usuários a flexibilidade de equilibrar desempenho e eficiência.
Outra inovação chave no Marco-o1 é a introdução de um mecanismo de reflexão. Durante o processo de raciocínio, o modelo periodicamente se questiona com a frase: “Espere! Talvez eu tenha cometido alguns erros! Preciso repensar do zero.” Isso faz com que o modelo reavalie seus passos de raciocínio, identifique erros potenciais e refine seu processo de pensamento.
“Essa abordagem permite que o modelo atue como seu próprio crítico, identificando erros potenciais em seu raciocínio”, escrevem os pesquisadores. “Ao solicitar explicitamente que o modelo questione suas conclusões iniciais, incentivamos ele a re-expressar e refinar seu processo de pensamento.”
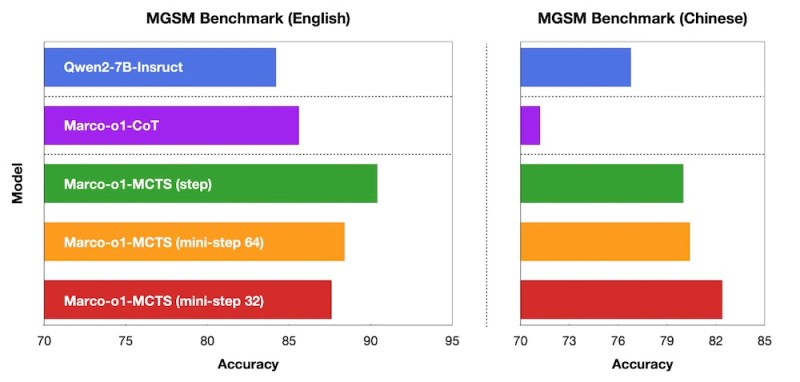
Para avaliar o desempenho do Marco-o1, os pesquisadores realizaram experimentos em várias tarefas, incluindo o benchmark MGSM, um conjunto de dados para problemas matemáticos escolares multilíngues. O Marco-o1 superou significativamente o modelo base Qwen2-7B, especialmente quando o componente MCTS foi ajustado para granularidade de token único.
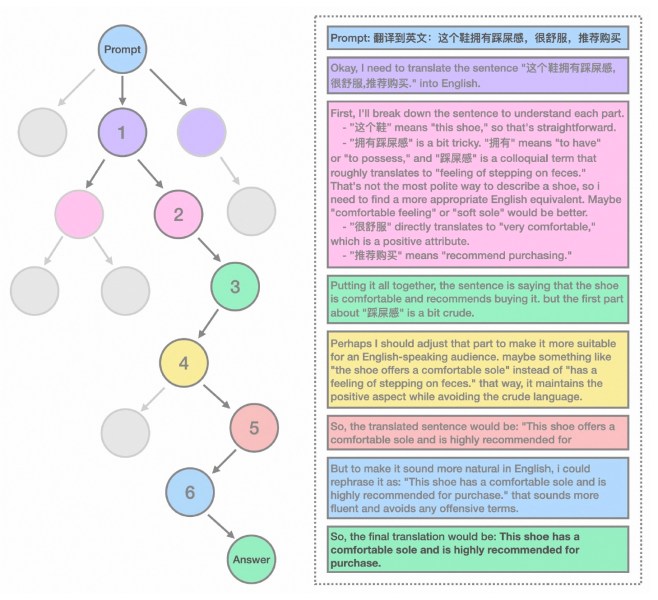
No entanto, o principal objetivo do Marco-o1 foi abordar os desafios do raciocínio em cenários abertos. Para isso, os pesquisadores testaram o modelo na tradução de expressões coloquiais e gírias, uma tarefa que requer a compreensão de nuances sutis de linguagem, cultura e contexto. Os experimentos mostraram que Marco-o1 conseguiu captar e traduzir essas expressões de forma mais eficaz do que as ferramentas de tradução tradicionais. Por exemplo, o modelo traduziu corretamente uma expressão coloquial em chinês, que literalmente significa “Este sapato oferece uma sensação de pisar em cocô”, para o equivalente em inglês, “Este sapato tem uma sola confortável.” A cadeia de raciocínio do modelo mostra como ele avalia diferentes significados potenciais e chega à tradução correta.
Esse paradigma pode se provar útil para tarefas como design de produtos e estratégia, que requerem compreensão aprofundada e contextual e não têm benchmarks e métricas bem definidos.
Uma nova onda de modelos de raciocínio
Desde o lançamento do o1, laboratórios de IA estão correndo para lançar modelos de raciocínio. Na semana passada, o laboratório de IA chinês DeepSeek lançou o R1-Lite-Preview, seu concorrente do o1, que atualmente está disponível apenas através da interface de chat online da empresa. O R1-Lite-Preview supostamente supera o o1 em várias métricas-chave.
A comunidade de código aberto também está alcançando o mercado de modelos privados, liberando modelos e conjuntos de dados que aproveitam as leis de expansão de tempo de inferência. A equipe da Alibaba lançou Marco-o1 no Hugging Face, juntamente com um conjunto de dados de raciocínio parcial que os pesquisadores podem usar para treinar seus próprios modelos de raciocínio. Outro modelo recentemente lançado é o LLaVA-o1, desenvolvido por pesquisadores de várias universidades da China, que traz o paradigma de raciocínio em tempo de inferência para modelos de linguagem e visão de código aberto (VLMs).
A liberação desses modelos ocorre em meio à incerteza sobre o futuro das leis de escalonamento de modelos. Vários relatórios indicam que os retornos do treinamento de modelos maiores estão diminuindo e podem estar atingindo um limite. Mas o que é certo é que estamos apenas começando a explorar as possibilidades da expansão de tempo de inferência.

Conteúdo relacionado

Runway, conhecida por seus modelos de IA para geração de vídeo, arrecada R$ 308 milhões.
[the_ad id="145565"] Runway, uma startup que desenvolve uma variedade de modelos de IA generativa para a produção de mídia, incluindo modelos de geração de vídeo, levantou US$…

Plataforma de IA de Voz Phonic recebe apoio da Lux
[the_ad id="145565"] A qualidade das vozes geradas por IA é suficientemente boa para criar audiolivros e podcasts, ler artigos em voz alta e oferecer suporte ao cliente básico.…

Como Claude Pensa? A Busca da Anthropic para Desvendar a Caixa-preta da IA
[the_ad id="145565"] Modelos de linguagem de grande escala (LLMs) como Claude mudaram a maneira como usamos a tecnologia. Eles alimentam ferramentas como chatbots, ajudam a…