


Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder da indústria. Saiba Mais
A gigante do e-commerce chinês Alibaba lançou o mais recente modelo de sua crescente família Qwen. Este é conhecido como Qwen com Perguntas (QwQ) e serve como o mais recente concorrente de código aberto ao modelo de raciocínio o1 da OpenAI.
Como outros grandes modelos de raciocínio (LRMs), o QwQ utiliza ciclos de computação adicionais durante a inferência para revisar suas respostas e corrigir seus erros, tornando-o mais adequado para tarefas que exigem raciocínio lógico e planejamento, como matemática e programação.
O que é Qwen com Perguntas (OwQ?) e pode ser usado para fins comerciais?
A Alibaba lançou uma versão de 32 bilhões de parâmetros do QwQ com um contexto de 32.000 tokens. O modelo está atualmente em pré-visualização, o que significa que uma versão de melhor desempenho provavelmente seguirá.
De acordo com os testes da Alibaba, o QwQ supera o o1-preview nos benchmarks AIME e MATH, que avaliam habilidades de resolução de problemas matemáticos. Ele também supera o o1-mini no GPQA, um benchmark para raciocínio científico. O QwQ é inferior ao o1 nos benchmarks de codificação LiveCodeBench, mas ainda supera outros modelos de ponta, como o GPT-4o e Claude 3.5 Sonnet.
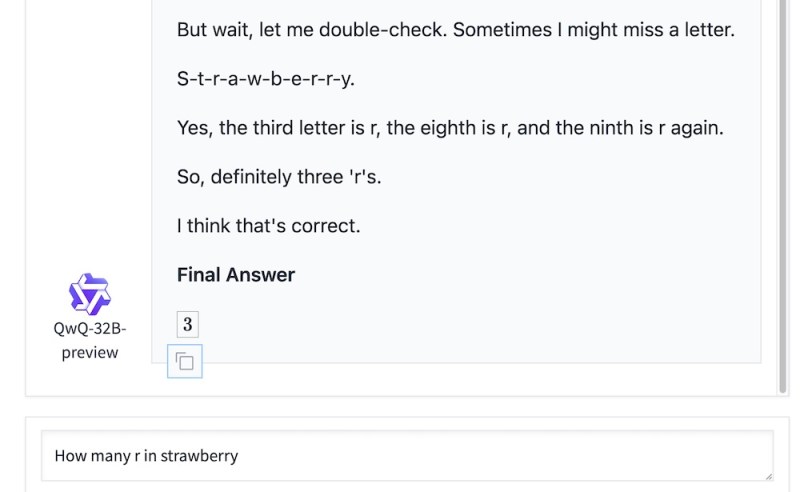
O QwQ não vem com um documento que descreve os dados ou o processo utilizado para treinar o modelo, o que torna difícil reproduzir os resultados do modelo. No entanto, como o modelo é aberto, ao contrário do OpenAI o1, seu “processo de pensamento” não está oculto e pode ser utilizado para entender como o modelo raciocina ao resolver problemas.
A Alibaba também lançou o modelo sob uma licença Apache 2.0, o que significa que pode ser utilizado para fins comerciais.
‘Nós descobrimos algo profundo’
De acordo com um post de blog publicado juntamente com o lançamento do modelo, “Através de uma exploração profunda e inúmeras tentativas, descobrimos algo profundo: quando dado tempo para ponderar, questionar e refletir, a compreensão do modelo sobre matemática e programação floresce como uma flor se abrindo ao sol… Este processo de reflexão cuidadosa e autoquestionamento leva a avanços notáveis na resolução de problemas complexos.”
Isso é muito semelhante ao que sabemos sobre como os modelos de raciocínio funcionam. Ao gerar mais tokens e revisar suas respostas anteriores, os modelos têm mais chances de corrigir potenciais erros. O Marco-o1, outro modelo de raciocínio recentemente lançado pela Alibaba, pode também conter dicas sobre como o QwQ pode estar funcionando. O Marco-o1 utiliza Monte Carlo Tree Search (MCTS) e auto-reflexão durante a inferência para criar diferentes ramificações de raciocínio e escolher as melhores respostas. O modelo foi treinado com uma mistura de exemplos de cadeia de pensamento (CoT) e dados sintéticos gerados com algoritmos MCTS.
A Alibaba aponta que o QwQ ainda possui limitações, como misturar idiomas ou ficar preso em ciclos de raciocínio circular. O modelo está disponível para download no Hugging Face e uma demonstração online pode ser encontrada em Hugging Face Spaces.
A era dos LLMs dá lugar aos LRMs: Modelos de Raciocínio Grande
O lançamento do o1 desencadeou um crescente interesse na criação de LRMs, mesmo que não se saiba muito sobre como o modelo funciona internamente, além de usar a escala de tempo de inferência para aprimorar as respostas do modelo.
Agora há vários concorrentes chineses ao o1. O laboratório de IA chinês DeepSeek lançou recentemente o R1-Lite-Preview, seu concorrente do o1, que atualmente está disponível apenas através da interface de chat online da empresa. O R1-Lite-Preview supostamente supera o o1 em vários benchmarks-chave.
Outra modelo recentemente lançado é o LLaVA-o1, desenvolvido por pesquisadores de várias universidades na China, que traz o paradigma de raciocínio em tempo de inferência para modelos de linguagem de visão de código aberto (VLMs).
O foco em LRMs ocorre em um momento de incerteza sobre o futuro das leis de escalonamento de modelos. Relatórios indicam que laboratórios de IA como OpenAI, Google DeepMind e Anthropic estão enfrentando retornos decrescentes ao treinar modelos maiores. E criar volumes maiores de dados de treinamento de qualidade está se tornando cada vez mais difícil, uma vez que os modelos já estão sendo treinados com trilhões de tokens coletados da internet.
Enquanto isso, a escala de tempo de inferência oferece uma alternativa que pode fornecer o próximo avanço na melhoria das habilidades da próxima geração de modelos de IA. Há relatórios de que a OpenAI está usando o o1 para gerar dados de raciocínio sintéticos para treinar a próxima geração de seus LLMs. O lançamento de modelos de raciocínio abertos provavelmente estimulará o progresso e tornará o espaço mais competitivo.

Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…