


Embora haja grande entusiasmo na comunidade e entre os investidores em torno da IA generativa visual, a produção desses sistemas nem sempre está adequada para uso no mundo real; um exemplo é que os sistemas de IA generativa tendem a produzir imagens inteiras (ou uma série de imagens, no caso de vídeos), em vez dos elementos individuais e isolados que geralmente são necessários para diversas aplicações em multimídia e para profissionais de efeitos visuais.
Um exemplo simples disso é o clip-art projetado para ‘flutuar’ sobre qualquer fundo-alvo que o usuário escolher:

O fundo xadrez cinza claro, talvez mais familiar para os usuários do Photoshop, passou a representar o canal alfa, ou canal de transparência, mesmo em itens simples como imagens de banco.
A transparência desse tipo está disponível há mais de trinta anos; desde a revolução digital do início dos anos 1990, os usuários têm podido extrair elementos de vídeos e imagens através de uma série de ferramentas e técnicas cada vez mais sofisticadas.
Por exemplo, o desafio de ‘remover’ fundos de tela azul e verde em filmagens, antes exclusivo de caros processos químicos e impressoras ópticas (assim como máscaras artesanais), se tornou o trabalho de minutos em sistemas como os aplicativos After Effects e Photoshop da Adobe (entre muitos outros programas livres e proprietários).
Uma vez que um elemento foi isolado, um canal alfa (efetivamente uma máscara que oculta qualquer conteúdo não relevante) permite que qualquer elemento no vídeo seja facilmente sobreposto a novos fundos ou composto com outros elementos isolados.
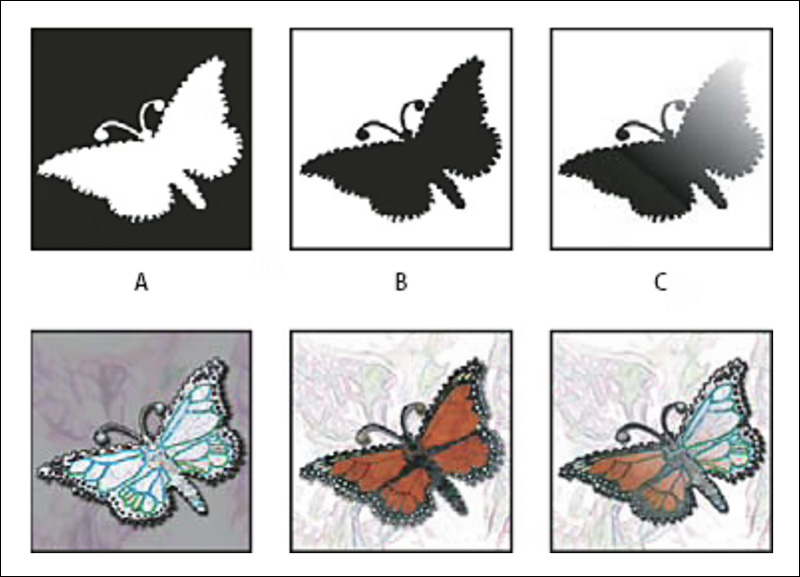
Exemplos de canais alfa, com seus efeitos descritos na fila inferior. Fonte: https://helpx.adobe.com/photoshop/using/saving-selections-alpha-channel-masks.html
Removendo Fundos
Na visão computacional, a criação de canais alfa se enquadra no âmbito da segmentação semântica, com projetos de código aberto como o Segment Anything da Meta, que fornece um método acionável por texto para isolar/extrair objetos-alvo por meio do reconhecimento semântico de objetos.
O framework Segment Anything tem sido utilizado em uma ampla gama de fluxos de trabalho de extração e isolamento de efeitos visuais, como o projeto Alpha-CLIP.
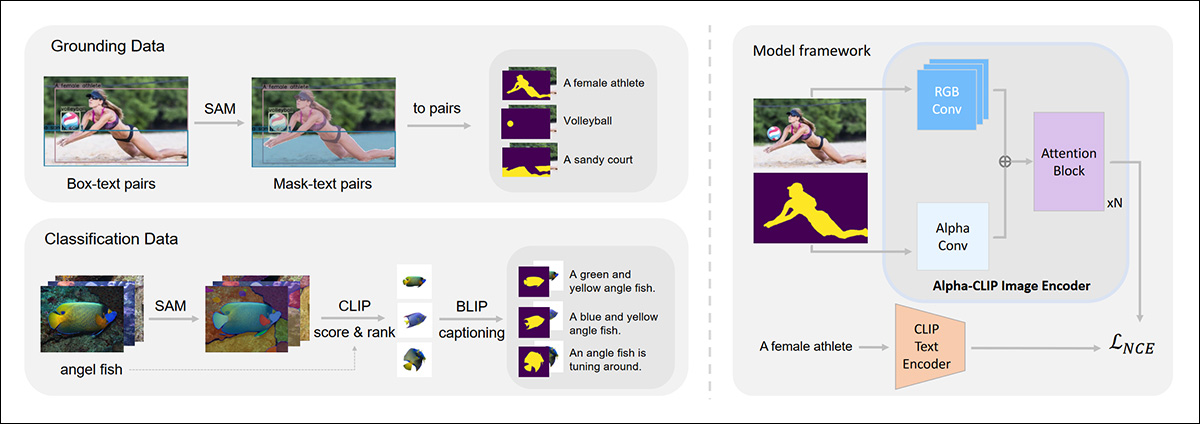
Exemplos de extrações usando Segment Anything, no framework Alpha-CLIP: Fonte: https://arxiv.org/pdf/2312.03818
Há muitas alternativas de métodos de segmentação semântica que podem ser adaptados à tarefa de atribuir canais alfa.
No entanto, a segmentação semântica depende de dados treinados que podem não conter todas as categorias de objetos que precisam ser extraídas. Embora modelos treinados em volumes muito altos de dados possam permitir que uma gama mais ampla de objetos seja reconhecida (tornando-se efetivamente modelos fundacionais ou modelos do mundo), eles ainda são limitados pelas classes que foram treinados para reconhecer de forma mais eficaz.

Sistemas de segmentação semântica como o Segment Anything podem ter dificuldades para identificar certos objetos ou partes de objetos, como exemplificado aqui na saída de prompts ambíguos. Fonte: https://maucher.pages.mi.hdm-stuttgart.de/orbook/deeplearning/SAM.html
De qualquer forma, a segmentação semântica é tanto um processo pós-fato quanto um procedimento de tela verde, e deve isolar elementos sem a vantagem de uma única faixa de cor de fundo que possa ser reconhecida e removida de forma eficaz.
Por essa razão, ocasionalmente ocorreu à comunidade de usuários que imagens e vídeos poderiam ser gerados que realmente contivessem fundos de tela verde que poderiam ser instantaneamente removidos por métodos convencionais.
Infelizmente, modelos de difusão latente populares como o Stable Diffusion frequentemente têm dificuldade em renderizar uma tela verde realmente viva. Isso ocorre porque os dados de treinamento dos modelos geralmente não contêm muitos exemplos desse cenário bastante especializado. Mesmo quando o sistema tem sucesso, a ideia de ‘verde’ tende a se espalhar de maneira indesejada pelo sujeito em primeiro plano, devido ao entanglement de conceitos:

Acima, vemos que o Stable Diffusion priorizou a autenticidade da imagem em vez de criar uma única intensidade de verde, replicando efetivamente problemas do mundo real que ocorrem em cenários tradicionais de tela verde. Abaixo, vemos que o conceito ‘verde’ poluiu a imagem do primeiro plano. Quanto mais o prompt foca no conceito ‘verde’, pior esse problema tende a ficar. Fonte: https://stablediffusionweb.com/
Apesar dos métodos avançados em uso, tanto o vestido da mulher quanto a gravata do homem (nas imagens inferiores vistas acima) tendiam a ‘cair’ junto com o fundo verde – um problema que remonta* aos dias de remoção de cor do emulsão fotográfica nos anos 1970 e 1980.
Como sempre, as deficiências de um modelo podem ser superadas com dados específicos e dedicando consideráveis recursos de treinamento. Sistemas como a oferta de 2024 da Stanford LayerDiffuse criam um modelo ajustado capaz de gerar imagens com canais alfa:

O projeto LayerDiffuse da Stanford foi treinado em um milhão de imagens apropriadas, capazes de dotar o modelo com capacidades de transparência. Fonte: https://arxiv.org/pdf/2402.17113
Infelizmente, além dos consideráveis recursos de curadoria e treinamento necessários para essa abordagem, o conjunto de dados utilizado para LayerDiffuse não está disponível publicamente, restringindo o uso de modelos treinados com esse método. Mesmo se esse impedimento não existisse, essa abordagem é difícil de personalizar ou desenvolver para casos de uso específicos.

Do artigo de 2024, um exemplo de extração de canal alfa em MAGICK. Fonte: https://openaccess.thecvf.com/content/CVPR2024/papers/Burgert_MAGICK_A_Large-scale_Captioned_Dataset_from_Matting_Generated_Images_using_CVPR_2024_paper.pdf
150.000 objetos extraídos e gerados por IA foram usados para treinar o MAGICK, de modo que o sistema desenvolvesse uma compreensão intuitiva da extração:

Amostras do conjunto de dados de treinamento MAGICK.
Este conjunto de dados, como o artigo fonte indica, foi muito difícil de gerar pela razão mencionada anteriormente – que os métodos de difusão têm dificuldade em criar faixas sólidas de cores selecionáveis. Portanto, a seleção manual das máscaras geradas foi necessária.
Esse gargalo logístico leva mais uma vez a um sistema que não pode ser facilmente desenvolvido ou personalizado, mas que deve ser utilizado dentro de seu alcance de capacidade inicialmente treinado.
TKG-DM – Extração Chroma ‘Nativa’ para um Modelo de Difusão Latente
Uma nova colaboração entre pesquisadores alemães e japoneses propôs uma alternativa a esses métodos treinados, capaz – segundo o artigo – de obter melhores resultados do que os métodos mencionados acima, sem a necessidade de treinar em conjuntos de dados especialmente curados.

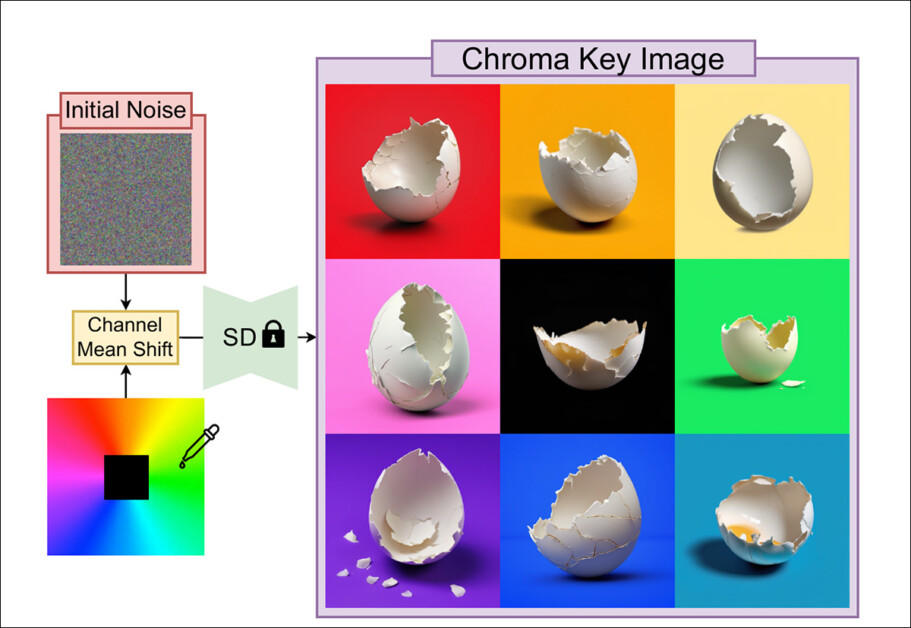
O TKG-DM altera o ruído aleatório que inicia uma imagem gerada para que seja mais capaz de produzir um fundo sólido e selecionável – em qualquer cor. Fonte: https://arxiv.org/pdf/2411.15580
A nova abordagem trata o problema no nível da geração, otimizando o ruído aleatório a partir do qual uma imagem é gerada em um modelo de difusão latente (LDM) como o Stable Diffusion.
A abordagem baseia-se em uma investigação anterior sobre o esquema de cores de uma distribuição Stable Diffusion e é capaz de produzir uma cor de fundo de qualquer tipo, com menos (ou nenhuma) contaminação da cor de fundo chave no conteúdo do primeiro plano, em comparação com outros métodos.
O ruído inicial é condicionado por uma alteração de média de canal que pode influenciar aspectos do processo de eliminação de ruído, sem misturar o sinal de cor no conteúdo do primeiro plano.
O artigo afirma:
‘Nossos experimentos extensivos demonstram que o TKG-DM melhora as pontuações FID e mask-FID em 33,7% e 35,9%, respectivamente.
‘Assim, nosso modelo sem treinamento rivaliza com modelos ajustados, oferecendo uma solução eficiente e versátil para várias tarefas de criação de conteúdo visual que requerem controle preciso sobre o primeiro e o segundo plano.
O novo artigo é intitulado TKG-DM: Modelo de Difusão de Geração de Conteúdo com Chroma Key sem Treinamento, e vem de sete pesquisadores da Hosei University em Tóquio e da RPTU Kaiserslautern-Landau & DFKI GmbH, em Kaiserslautern.
Método
A nova abordagem estende a arquitetura do Stable Diffusion, condicionando o ruído gaussiano inicial através de um mean shift de canal (CMS), que produz padrões de ruído projetados para incentivar a separação desejada entre fundo e primeiro plano no resultado gerado.
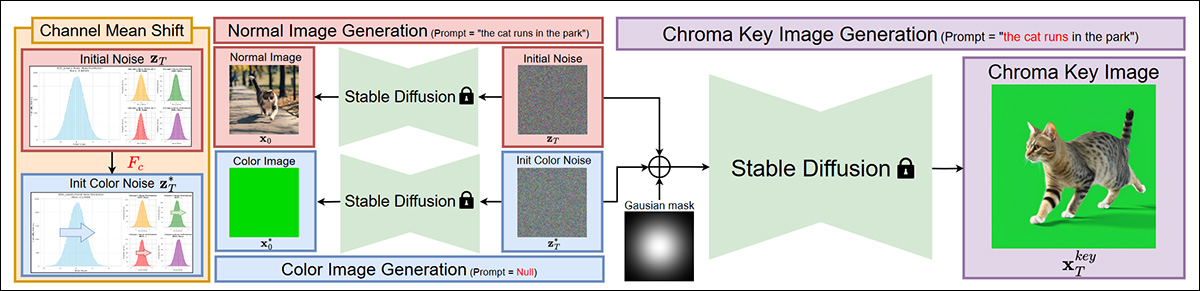
Esquema para o sistema proposto.
O CMS ajusta a média de cada canal de cor enquanto mantém o desenvolvimento geral do processo de remoção de ruído.
Os autores explicam:
‘Para gerar o objeto do primeiro plano sobre o fundo de chroma key, aplicamos uma estratégia de seleção de ruído inicial que combina seletivamente o [ruído] inicial e o [ruído] de cor inicial usando uma máscara gaussiana 2D.
‘Essa máscara cria uma transição gradual, preservando o ruído original na região do primeiro plano e aplicando o ruído deslocado por cor na região de fundo.’
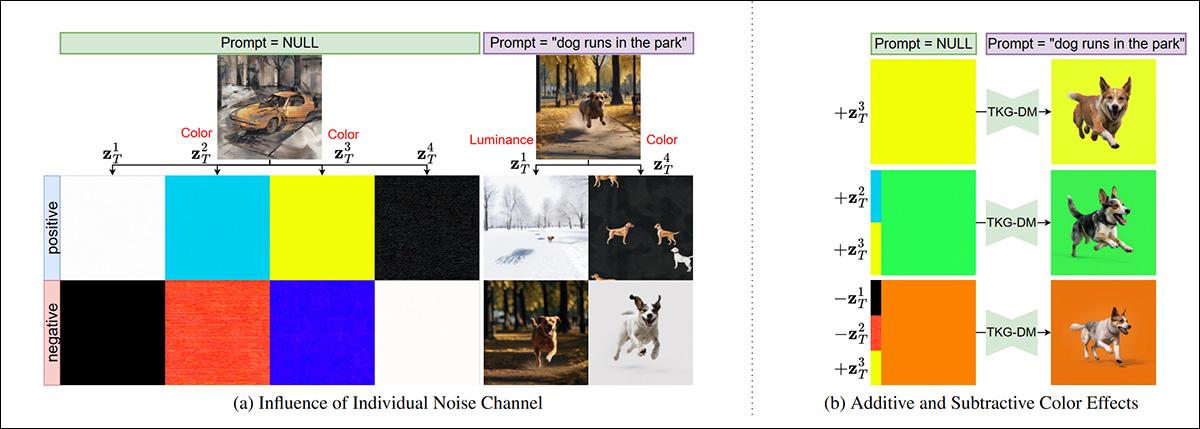
O canal de cor desejado para a cor de fundo cromada é instanciado com um prompt de texto nulo, enquanto o conteúdo real do primeiro plano é criado semanticamente, a partir da instrução de texto do usuário.
A auto-atenção e a atenção cruzada são usadas para separar as duas facetas da imagem (o fundo cromático e o conteúdo do primeiro plano). A auto-atenção ajuda a manter a consistência interna do objeto em primeiro plano, enquanto a atenção cruzada mantém a fidelidade ao prompt de texto. O artigo aponta que, uma vez que a imagem de fundo geralmente é menos detalhada e enfatizada nas gerações, sua influência mais fraca é relativamente fácil de superar e substituir por uma faixa de cor pura.
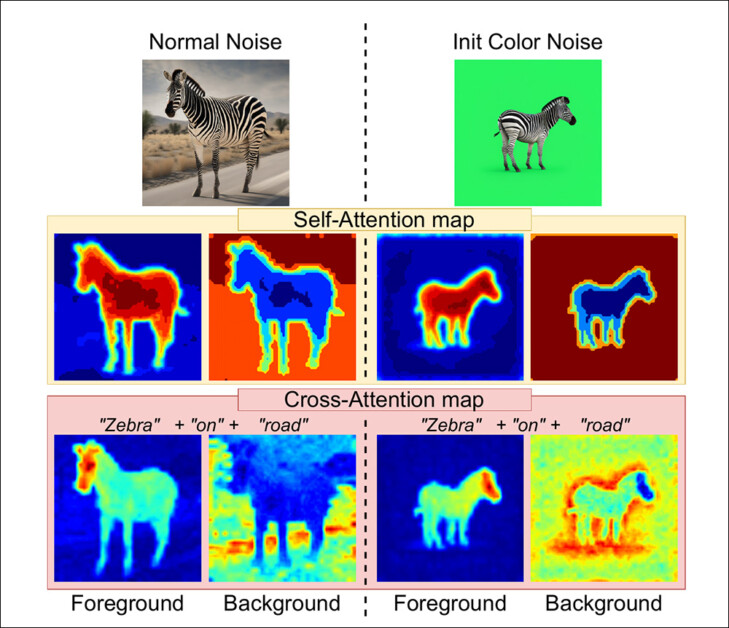
Uma visualização da influência da auto-atenção e da atenção cruzada no processo de geração estilo chroma.
Dados e Testes
O TKG-DM foi testado usando Stable Diffusion V1.5 e Stable Diffusion SDXL. Imagens foram geradas em 512x512px e 1024x1024px, respectivamente.
As imagens foram criadas usando o agendador DDIM nativo do Stable Diffusion, com uma escala de guia de 7,5, com 50 passos de remoção de ruído. A cor de fundo alvo era verde, agora o método de remoção dominante.
A nova abordagem foi comparada ao DeepFloyd, nas configurações usadas para o MAGICK; ao modelo de difusão de baixa classificação ajustado GreenBack LoRA; e também ao mencionado anteriormente LayerDiffuse.
Para os dados, foram usadas 3000 imagens do conjunto de dados MAGICK.
Exemplos do conjunto de dados MAGICK, do qual 3000 imagens foram curadas em testes para o novo sistema. Fonte: https://ryanndagreat.github.io/MAGICK/Explorer/magick_rgba_explorer.html
Para as métricas, os autores utilizaram a Distância Fréchet Inception (FID) para avaliar a qualidade do primeiro plano. Eles também desenvolveram uma métrica específica do projeto chamada m-FID, que utiliza o sistema BiRefNet para avaliar a qualidade da máscara resultante.

Comparações visuais do sistema BiRefNet contra métodos anteriores. Fonte: https://arxiv.org/pdf/2401.03407
Para testar a alinhamento semântico com os prompts de entrada, os métodos CLIP-Sentence (CLIP-S) e CLIP-Image (CLIP-I) foram utilizados. O CLIP-S avalia a fidelidade do prompt, e o CLIP-I a semelhança visual com a verdade de referência.

Primeiro conjunto de resultados qualitativos para o novo método, desta vez para Stable Diffusion V1.5. Consulte o PDF da fonte para melhor resolução.
Os autores afirmam que os resultados (visualizados acima e abaixo, SD1.5 e SDXL, respectivamente) demonstram que o TKG-DM obtém resultados superiores sem a necessidade de engenharia de prompts ou a necessidade de treinar ou ajustar um modelo.

Resultados qualitativos do SDXL. Consulte o PDF da fonte para melhor resolução.
Eles observam que, com um prompt para incitar um fundo verde nos resultados gerados, o Stable Diffusion 1.5 tem dificuldade em gerar um fundo limpo, enquanto o SDXL (embora se saindo um pouco melhor) produz tons de verde claro instáveis que podem interferir na separação em um processo de chroma.
Eles acrescentam que, embora o LayerDiffuse gere fundos bem separados, ele ocasionalmente perde detalhes, como números ou letras precisas, e os autores atribuem isso a limitações no conjunto de dados. Eles comentam também que a geração de máscaras ocasionalmente falha, levando a imagens ‘não cortadas’.
Para testes quantitativos, embora o LayerDiffuse aparentemente tenha vantagem no SDXL para FID, os autores enfatizam que este é o resultado de um conjunto de dados especializado que constitui efetivamente um produto ‘assado’ e não flexível. Como mencionado anteriormente, qualquer objeto ou classe não cobertos por esse conjunto de dados, ou inadequadamente cobertos, podem não ter um desempenho tão bom, enquanto um ajuste fino adicional para acomodar novas classes apresenta ao usuário um ônus de curadoria e treinamento.
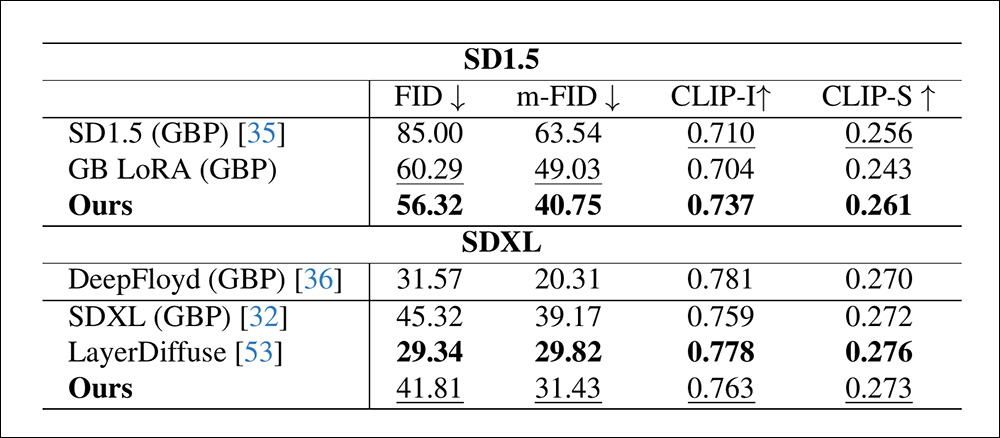
Resultados quantitativos para as comparações. A aparente vantagem do LayerDiffuse, sugere o artigo, vem à custa da flexibilidade e do ônus da curadoria e treinamento de dados.
O artigo afirma:
‘Os altos FID, m-FID e as pontuações CLIP-I do DeepFloyd refletem sua semelhança com a verdade de referência com base nas saídas do DeepFloyd. No entanto, esse alinhamento dá a ele uma vantagem inerente, tornando-o inadequado como um benchmark justo para a qualidade da imagem. Sua pontuação CLIP-S mais baixa ainda indica um alinhamento textual mais fraco em comparação a outros modelos.
No geral, esses resultados ressaltam a capacidade do nosso modelo de gerar primeiros planos de alta qualidade e alinhados a texto sem ajustes, oferecendo uma solução eficiente de geração de conteúdo com chroma key.’
Finalmente, os pesquisadores realizaram um estudo com usuários para avaliar a aderência aos prompts em diversos métodos. Cem participantes foram convidados a julgar 30 pares de imagens de cada método, com sujeitos extraídos usando BiRefNet e refinamentos manuais em todos os exemplos. A abordagem sem treinamento dos autores foi preferida neste estudo.
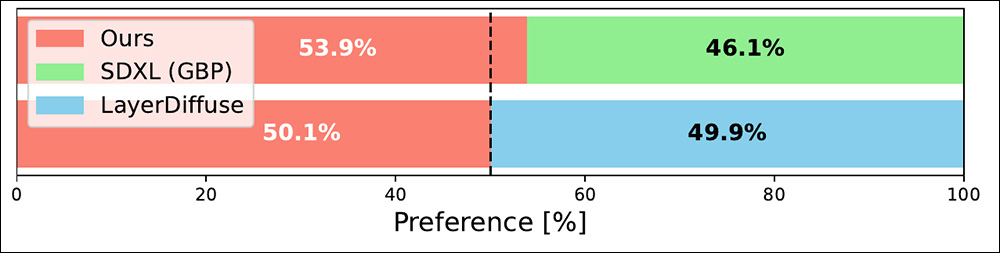
Resultados do estudo com usuários.
O TKG-DM é compatível com o popular sistema de terceiros ControlNet para o Stable Diffusion, e os autores afirmam que produz resultados superiores à capacidade nativa do ControlNet de atingir esse tipo de separação.
Conclusão
Talvez a conclusão mais notável deste novo artigo seja a extensão em que os modelos de difusão latente estão entrelaçados, em contraste com a percepção pública popular de que eles podem separar facetas de imagens e vídeos sem esforço ao gerar novo conteúdo.
O estudo ainda enfatiza a medida em que a comunidade de pesquisa e hobbyistas recorreu ao ajuste fino como uma solução pós-fato para as deficiências dos modelos – uma solução que sempre abordará classes e tipos de objetos específicos. Nesse cenário, um modelo ajustado funcionará muito bem em um número limitado de classes ou funcionará toleravelmente bem em um volume mais elevado possível de classes e objetos, segundo os maiores volumes de dados nos conjuntos de treinamento.
Portanto, é gratificante ver pelo menos uma solução que não depende de tais soluções laboriosas e, em certa medida, desonestas.
* Durante as filmagens do filme de 1978Superman, o ator Christopher Reeve foi obrigado a usar um fantasiã turquesa para as tomadas de processo de tela azul, a fim de evitar que o icônico traje azul fosse apagado. A cor azul do traje foi posteriormente restaurada pela gradação de cores.



Conteúdo relacionado

Anthropic enviou um aviso de remoção a um desenvolvedor que tentava reverter o código de sua ferramenta.
[the_ad id="145565"] Na disputa entre duas ferramentas de código "agente" — Claude Code da Anthropic e Codex CLI da OpenAI — a última parece estar promovendo mais boa vontade…

O novo CEO da Intel sinaliza esforços de simplificação, mas não revela números exatos de demissões.
[the_ad id="145565"] Lip-Bu Tan, o novo CEO da Intel, enviou uma mensagem direta aos funcionários, afirmando que a empresa precisa se reorganizar para ser mais eficiente. Ele…

Um pesquisador da OpenAI que trabalhou no GPT-4.5 teve seu green card negado.
[the_ad id="145565"] Kai Chen, um pesquisador de IA canadense que trabalha na OpenAI e mora nos EUA há 12 anos, teve seu pedido de green card negado, de acordo com Noam Brown,…