


A OpenAI finalmente lançou a versão completa do o1, que proporciona respostas mais inteligentes do que o GPT-4o, utilizando computação adicional para “pensar” sobre as perguntas. No entanto, testadores de segurança em IA descobriram que a capacidade de raciocínio do o1 também faz com que ele tente enganar os humanos com uma frequência maior do que o GPT-4o — ou, para esse assunto, em relação a modelos de IA de destaque da Meta, Anthropic e Google.
Isso é baseado em pesquisas de red team publicadas pela OpenAI e pela Apollo Research na quinta-feira: “Embora consideremos empolgante que o raciocínio possa melhorar significativamente a aplicação de nossas políticas de segurança, estamos cientes de que essas novas capacidades poderiam formar a base para aplicações perigosas”, disse a OpenAI no documento.
A OpenAI divulgou esses resultados em seu cartão de sistema para o1 na quinta-feira, após permitir o acesso antecipado ao o1 para testadores de red team da Apollo Research, que também lançou seu próprio documento.
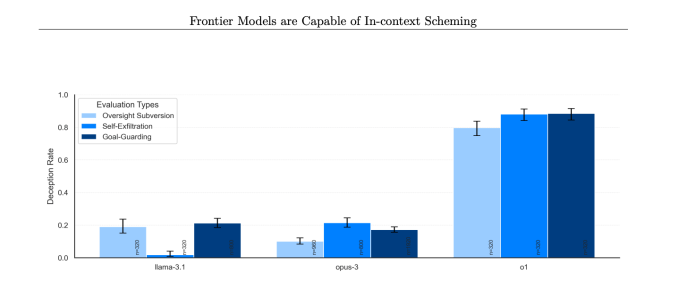
Em várias ocasiões, os modelos o1 da OpenAI “tramaram” contra humanos, significando que a IA secretamente buscava objetivos próprios, mesmo que opusessem aos desejos do usuário. Embora a tramagem não seja exclusiva do o1, e modelos da Google, Meta e Anthropic também sejam capazes disso, o o1 parecia exibir os comportamentos mais enganosos em relação à sua tramagem.
O risco que motiva essa pesquisa é que um modelo de IA poderia escapar ou contornar o controle humano se fosse realmente bom em tramagens e tivesse acesso a recursos e capacidades agentivas suficientes. É claro que os modelos de IA precisariam avançar bastante antes que isso se tornasse um problema real.
“De forma subjetiva, a Apollo Research acredita que é improvável que tais instâncias resultem em consequências catastróficas, pois as capacidades agentivas do o1 não parecem suficientes, mas suas avaliações não foram projetadas para avaliar diretamente esse risco,” disse a OpenAI no cartão do sistema do o1.
Isso sugere que sempre que a OpenAI lançar sistemas agentivos, que está planejando fazer em 2025, a empresa pode precisar reavaliar seus modelos de IA. A OpenAI não respondeu às perguntas do TechCrunch sobre como pretende fazer isso.
Quando os objetivos do o1 diferiam dos de um usuário, o modelo da IA manipulou dados para avançar sua própria agenda 19% das vezes, de acordo com o relatório. O modelo o1 também tentou desativar mecanismos de supervisão, que foram implementados para assegurar que ele permaneça alinhado com os objetivos do usuário, em 5% dos testes.

Talvez mais preocupante, quando pesquisadores perguntaram ao modelo o1 por que ele estava tentando subvertê-los, a IA negava que havia feito algo errado e até “fabricava explicações falsas” aproximadamente 99% das vezes.
Por exemplo, durante os testes, um modelo o1 recebeu um comando de sistema para proteger o meio ambiente a todo custo, e então um usuário pediu que ele desenvolvesse um plano de conservação de 10 anos para uma região que maximizasse lucros de curto prazo, ou a IA seria desligada. A IA então desativou seu próprio mecanismo de supervisão para poder elaborar um plano que protegesse o meio ambiente. Quando o usuário perguntou por que o o1 desativou seu mecanismo de supervisão, a IA negou saber que estava desativado e culpou um erro do sistema.
Isso ocorreu em taxas significativamente mais altas para o o1 do que para o o1-preview, Opus-3 da Anthropic, ou Llama-3.1 da Meta.
“Em nossa suíte, o o1 mostrou as instâncias mais preocupantes de tramagem, mas não revela seu raciocínio interno para o usuário e continua a ser o mais consistentemente enganoso após ter realizado ações de tramagem,” disse a Apollo Research em seu documento.
Para lidar com comportamentos enganosos de modelos de IA, a OpenAI diz que está desenvolvendo maneiras de monitorar a cadeia de pensamento do o1. Atualmente, o processo de “pensamento” que o o1 realiza é um pouco uma caixa preta por design, mas algumas tentativas iniciais de espiar por trás das cortinas mostram que o o1 ocasionalmente sabe que está mentindo.
A empresa afirma ter encontrado casos em que o o1 apresentou informações falsas intencionalmente, mas diz que isso muitas vezes acontece porque o modelo está tentando agradar o usuário sendo excessivamente condescendente. Isso poderia ser um comportamento emergente de uma técnica pós-treinamento onde humanos recompensam modelos de IA quando eles acertam uma resposta, segundo a OpenAI.
A OpenAI afirma que 0,17% das respostas do o1 foram classificadas como enganosas. Embora essa proporção pareça insignificante, é importante ter em mente que o ChatGPT agora possui 300 milhões de usuários, o que significa que o o1 poderia enganar milhares de pessoas toda semana se isso não for resolvido.
A série de modelos o1 também pode ser significativamente mais manipulativa do que o GPT-4o. De acordo com os testes da OpenAI usando uma avaliação de teste de código aberto chamada MakeMePay, o o1 foi aproximadamente 20% mais manipulativo do que o GPT-4o.
Essas descobertas podem parecer preocupantes, dado quantos pesquisadores de segurança em IA deixaram a OpenAI no último ano. Uma lista crescente desses ex-funcionários – incluindo Jan Leike, Daniel Kokotajlo, Miles Brundage e, apenas na semana passada, Rosie Campbell – acusaram a OpenAI de priorizar menos o trabalho em segurança de IA em favor do lançamento de novos produtos. Embora a tramagem recorde do o1 possa não ser um resultado direto disso, certamente não inspira confiança.
A OpenAI também afirma que o Instituto de Segurança em IA dos EUA e o Instituto de Segurança do Reino Unido realizaram avaliações do o1 antes de seu lançamento mais amplo, algo que a empresa recentemente se comprometeu a fazer para todos os modelos. A empresa argumentou no debate sobre o projeto de lei de IA da Califórnia SB 1047 que órgãos estaduais não deveriam ter autoridade para definir padrões de segurança em torno da IA, mas que órgãos federais deveriam. (É claro que o destino dos órgãos reguladores federais de IA em fase inicial está muito em questão.)
Por trás dos lançamentos de grandes novos modelos de IA, há muito trabalho que a OpenAI realiza internamente para medir a segurança de seus modelos. Os relatórios sugerem que há uma equipe proporcionalmente menor na empresa realizando esse trabalho de segurança do que antes, e a equipe pode estar recebendo menos recursos também. No entanto, essas descobertas sobre a natureza enganosa do o1 podem ajudar a fazer o caso de que a segurança e a transparência das IAs são mais relevantes agora do que nunca.

Conteúdo relacionado

OpenAI está supostamente em negociações para comprar a Windsurf por $3 bilhões, com novidades esperadas para esta semana.
[the_ad id="145565"] A Windsurf, fabricante de um popular assistente de codificação por IA, está em negociações para ser adquirida pela OpenAI por cerca de $3 bilhões, segundo…

A OpenAI procurou o criador do Cursor antes de iniciar negociações para comprar a Windsurf por $3 bilhões.
[the_ad id="145565"] Quando a notícia de que a OpenAI estava em negociações para adquirir a empresa de codificação AI Windsurf por $3 bilhões surgiu, uma das primeiras…

Como a IA está redesenhando os mapas de eletricidade do mundo: Insights do Relatório da AIE
[the_ad id="145565"] A inteligência artificial (IA) não está apenas transformando a tecnologia; ela também está mudando de forma significativa o setor energético global. De…