


Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura líder da indústria em IA. Saiba mais
O VP de IA generativa da Meta, Ahmad Al-Dahle, usou a rede social rival X hoje para anunciar o lançamento do Llama 3.3, o mais recente modelo de linguagem grande multilingue e open-source (LLM) da empresa-mãe do Facebook, Instagram, WhatsApp e Quest VR.
Conforme ele escreveu: “Llama 3.3 melhora o desempenho central a um custo significativamente mais baixo, tornando-o ainda mais acessível para toda a comunidade open-source.”
Com 70 bilhões de parâmetros — ou configurações que governam o comportamento do modelo — o Llama 3.3 entrega resultados comparáveis ao modelo de 405B parâmetros da Llama 3.1 do verão passado, mas a uma fração do custo e da sobrecarga computacional — por exemplo, a capacidade da GPU necessária para executar o modelo em uma inferência.
O modelo é projetado para oferecer desempenho de primeira linha e acessibilidade em um pacote menor do que os modelos fundamentais anteriores.
O Llama 3.3 da Meta é oferecido sob o Acordo de Licença da Comunidade Llama 3.3, que concede uma licença não exclusiva e isenta de royalties para uso, reprodução, distribuição e modificação do modelo e suas saídas. Os desenvolvedores que integrarem o Llama 3.3 em produtos ou serviços devem incluir atribuição apropriada, como “Construído com Llama”, e aderir a uma Política de Uso Aceitável que proíbe atividades como a geração de conteúdo nocivo, violação das leis ou a habilitação de ataques cibernéticos. Embora a licença seja geralmente gratuita, organizações com mais de 700 milhões de usuários ativos mensais devem obter uma licença comercial diretamente da Meta.
Uma declaração da equipe de IA da Meta sublinha essa visão: “Llama 3.3 proporciona desempenho e qualidade líderes em casos de uso baseados em texto a uma fração do custo de inferência.”
Quais economias estamos falando, na verdade? Um cálculo rápido:
O Llama 3.1-405B requer entre 243 GB e 1944 GB de memória GPU, de acordo com o blog Substratus (para o substrate cross cloud open source). Enquanto isso, o modelo mais antigo Llama 2-70B requer entre 42-168 GB de memória GPU, de acordo com o mesmo blog, embora alguns tenham afirmado que é tão baixo quanto 4 GB, ou como a Exo Labs demonstrou, alguns computadores Mac com chips M4 e sem GPUs discretas.
Portanto, se as economias de GPU para modelos de parâmetros mais baixos se mantiverem nesse caso, aqueles que buscam implantar os modelos Llama mais poderosos da Meta podem esperar economizar até quase 1940 GB de memória GPU, ou potencialmente, uma carga de GPU reduzida em 24 vezes para uma GPU Nvidia H100 de 80 GB.
Com um custo estimado de $25,000 por GPU H100, isso representa até $600,000 em economias de custo inicial em GPU, potencialmente — sem mencionar os custos contínuos de energia.
Um modelo altamente performático em um formato compacto
De acordo com Meta AI no X, o modelo Llama 3.3 superou com facilidade o Llama 3.1-70B de tamanho idêntico, bem como o novo modelo Nova Pro da Amazon em vários benchmarks, como diálogo multilíngue, raciocínio e outras tarefas avançadas de processamento de linguagem natural (NLP) (a Nova supera em tarefas de codificação HumanEval).
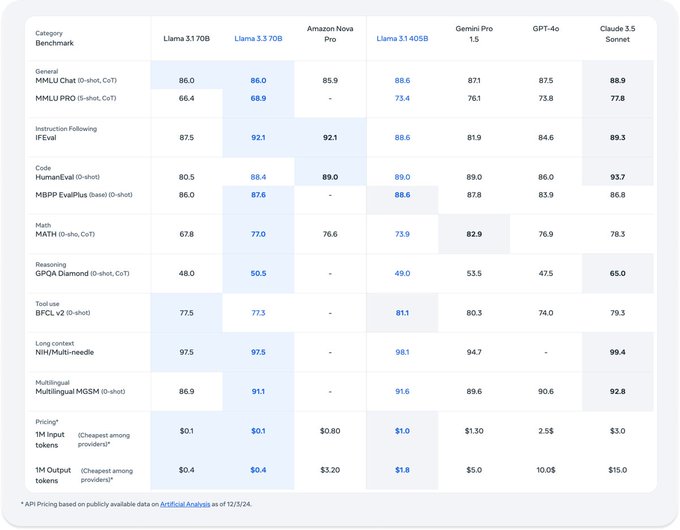
O Llama 3.3 foi pré-treinado em 15 trilhões de tokens a partir de dados “disponíveis publicamente” e ajustado em mais de 25 milhões de exemplos gerados sinteticamente, de acordo com as informações fornecidas pela Meta no “cartão do modelo” publicado em seu site.
Alavancando 39.3 milhões de horas de GPU em hardware H100-80GB, o desenvolvimento do modelo destaca o compromisso da Meta com a eficiência energética e a sustentabilidade.
O Llama 3.3 se destaca em tarefas de raciocínio multilíngues com uma taxa de precisão de 91.1% no MGSM, demonstrando sua eficácia em suportar idiomas como alemão, francês, italiano, hindi, português, espanhol e tailandês, além do inglês.
Econômico e ambientalmente consciente
O Llama 3.3 é especificamente otimizado para inferência econômica, com custos de geração de tokens tão baixos quanto $0.01 por milhão de tokens.
Isso torna o modelo altamente competitivo em relação a concorrentes da indústria, como GPT-4 e Claude 3.5, com maior acessibilidade para desenvolvedores que buscam implantar soluções sofisticadas de IA.
A Meta também enfatizou a responsabilidade ambiental deste lançamento. Apesar do intenso processo de treinamento, a empresa utilizou energia renovável para compensar as emissões de gases de efeito estufa, resultando em emissões líquidas zero para a fase de treinamento. As emissões baseadas em localização totalizaram 11,390 toneladas de CO2-equivalente, mas as iniciativas de energia renovável da Meta garantiram a sustentabilidade.
Recursos avançados e opções de implantação
O modelo introduz várias melhorias, incluindo uma janela de contexto mais longa de 128k tokens (comparável ao GPT-4o, cerca de 400 páginas de texto de livro), tornando-o adequado para geração de conteúdo de longa duração e outros casos de uso avançados.
Sua arquitetura incorpora Atenção por Consulta Agrupada (Grouped Query Attention – GQA), melhorando a escalabilidade e o desempenho durante a inferência.
Projetado para se alinhar com as preferências dos usuários por segurança e utilidade, o Llama 3.3 utiliza aprendizado por reforço com feedback humano (RLHF) e ajuste fino supervisionado (SFT). Este alinhamento garante recusas robustas a solicitações inadequadas e um comportamento semelhante ao de assistentes, otimizado para aplicações no mundo real.
O Llama 3.3 já está disponível para download através de Meta, Hugging Face, GitHub, e outras plataformas, com opções de integração para pesquisadores e desenvolvedores. A Meta também está oferecendo recursos como Llama Guard 3 e Prompt Guard para ajudar os usuários a implantar o modelo de forma segura e responsável.

Conteúdo relacionado

OpenAI está supostamente em negociações para comprar a Windsurf por $3 bilhões, com novidades esperadas para esta semana.
[the_ad id="145565"] A Windsurf, fabricante de um popular assistente de codificação por IA, está em negociações para ser adquirida pela OpenAI por cerca de $3 bilhões, segundo…

A OpenAI procurou o criador do Cursor antes de iniciar negociações para comprar a Windsurf por $3 bilhões.
[the_ad id="145565"] Quando a notícia de que a OpenAI estava em negociações para adquirir a empresa de codificação AI Windsurf por $3 bilhões surgiu, uma das primeiras…

Como a IA está redesenhando os mapas de eletricidade do mundo: Insights do Relatório da AIE
[the_ad id="145565"] A inteligência artificial (IA) não está apenas transformando a tecnologia; ela também está mudando de forma significativa o setor energético global. De…