


Um teste bem conhecido para inteligência geral artificial (AGI) está se aproximando de uma solução, mas os criadores do teste afirmam que isso aponta para falhas no design do teste, ao invés de um verdadeiro avanço na pesquisa.
Em 2019, Francois Chollet, uma figura proeminente no mundo da IA, apresentou o benchmark ARC-AGI, que significa “Corpus Abstrato e de Raciocínio para Inteligência Geral Artificial.” Projetado para avaliar se um sistema de IA pode adquirir novas habilidades de maneira eficiente, além dos dados com os quais foi treinado, ARC-AGI, segundo Francois, continua a ser o único teste de IA para medir o progresso em direção à inteligência geral (embora outros tenham sido propostos).
Até este ano, a IA com melhor desempenho conseguia resolver pouco menos de um terço das tarefas do ARC-AGI. Chollet atribuiu isso ao foco da indústria em modelos de linguagem grandes (LLMs), que ele acredita não serem capazes de um verdadeiro “raciocínio.”
“Os LLMs têm dificuldades com a generalização, devido à sua dependência total da memorização,” ele disse em uma série de postagens no X em fevereiro. “Eles falham em qualquer coisa que não estava em seus dados de treinamento.”
Para reforçar o argumento de Chollet, os LLMs são máquinas estatísticas. Treinados com muitos exemplos, eles aprendem padrões nesses exemplos para fazer previsões — como “a quem” em um e-mail que tipicamente precede “pode interessar.”
Chollet afirma que, embora os LLMs possam ser capazes de memorizar “padrões de raciocínio,” é improvável que consigam gerar “novos raciocínios” com base em situações novas. “Se você precisa ser treinado em muitos exemplos de um padrão, mesmo que seja implícito, para aprender uma representação reutilizável, você está memorizando,” argumentou Chollet em outra postagem.
Para incentivar a pesquisa além dos LLMs, em junho, Chollet e o cofundador do Zapier, Mike Knoop, lançaram uma competição de $1 milhão para construir uma IA de código aberto capaz de vencer o ARC-AGI. Dentre 17.789 inscrições, a melhor pontuação foi de 55,5% — cerca de 20% mais alta que a pontuação mais alta de 2023, embora ainda aquém do limite de 85% considerado “nível humano” necessário para vencer.
Isso não significa que estamos 20% mais próximos da AGI, no entanto, diz Knoop.
Hoje estamos anunciando os vencedores do ARC Prize 2024. Também publicaremos um extenso relatório técnico sobre o que aprendemos com a competição (link no próximo tweet).
O estado da arte passou de 33% para 55,5%, o maior aumento em um único ano que vimos desde 2020. O…
— François Chollet (@fchollet) 6 de dezembro de 2024
Em um post de blog, Knoop disse que muitas das inscrições no ARC-AGI conseguiram “forçar” uma solução, sugerindo que uma “grande fração” das tarefas do ARC-AGI “[não] carrega muito sinal útil em direção à inteligência geral.”
O ARC-AGI consiste em problemas parecidos com quebra-cabeças onde uma IA deve gerar a grade de “resposta” correta a partir de uma coleção de quadrados de diferentes cores. Os problemas foram projetados para forçar uma IA a se adaptar a novos problemas que ela não viu antes. Mas não está claro se isso está sendo alcançado.
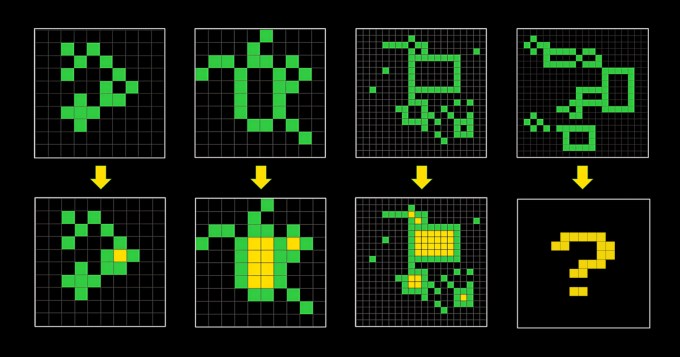
“[ARC-AGI] permanece inalterada desde 2019 e não é perfeita,” reconheceu Knoop em seu post.
Francois e Knoop também enfrentaram críticas por exagerar o ARC-AGI como um benchmark em direção à AGI, especialmente desde que a própria definição de AGI está sendo amplamente contestada atualmente. Um membro da equipe da OpenAI recentemente afirmou que a AGI “já” foi alcançada se se definir AGI como IA “melhor que a maioria dos humanos na maioria das tarefas.”
Knoop e Chollet afirmam que planejam lançar um benchmark ARC-AGI de segunda geração para abordar essas questões, juntamente com uma competição em 2025. “Nós continuaremos a direcionar os esforços da comunidade de pesquisa para o que vemos como os problemas não resolvidos mais importantes em IA, e acelerar a linha do tempo para a AGI,” escreveu Chollet em uma postagem no X postou.
As correções provavelmente não serão fáceis. Se as deficiências do primeiro teste ARC-AGI são qualquer indicação, definir inteligência para IA será tão intricado — e polarizador — quanto tem sido para os seres humanos.

Conteúdo relacionado

OpenAI está supostamente em negociações para comprar a Windsurf por $3 bilhões, com novidades esperadas para esta semana.
[the_ad id="145565"] A Windsurf, fabricante de um popular assistente de codificação por IA, está em negociações para ser adquirida pela OpenAI por cerca de $3 bilhões, segundo…

A OpenAI procurou o criador do Cursor antes de iniciar negociações para comprar a Windsurf por $3 bilhões.
[the_ad id="145565"] Quando a notícia de que a OpenAI estava em negociações para adquirir a empresa de codificação AI Windsurf por $3 bilhões surgiu, uma das primeiras…

Como a IA está redesenhando os mapas de eletricidade do mundo: Insights do Relatório da AIE
[the_ad id="145565"] A inteligência artificial (IA) não está apenas transformando a tecnologia; ela também está mudando de forma significativa o setor energético global. De…