


Até o momento, a Previsão de Atração Facial (FAP) tem sido estudada principalmente no contexto de pesquisas psicológicas, na indústria de beleza e cosméticos, e no contexto de cirurgia plástica. Este é um campo de estudo desafiador, pois os padrões de beleza tendem a ser nacionais em vez de globais.
Isso significa que nenhum conjunto de dados baseado em IA é eficaz, pois as médias obtidas a partir da amostragem de rostos/avaliações de todas as culturas seriam muito tendenciosas (onde nações mais populosas teriam mais influência), ou então aplicáveis a nenhuma cultura em absoluto (onde a média de múltiplas raças/avaliações equivaleria a nenhuma raça real).
Em vez disso, o desafio é desenvolver metodologias conceituais e fluxos de trabalho nos quais dados específicos de países ou culturas possam ser processados, para possibilitar o desenvolvimento de modelos FAP eficazes por região.
Os casos de uso para FAP em beleza e pesquisa psicológica são bastante marginais, ou específicos para a indústria; portanto, a maioria dos conjuntos de dados coletados até agora contém apenas dados limitados ou não foram publicados de forma alguma.
A fácil disponibilidade de preditores de atratividade online, principalmente voltados para o público ocidental, não necessariamente representa o estado-da-arte em FAP, que atualmente parece ser dominado pela pesquisa de países do leste asiático (principalmente a China) e pelos conjuntos de dados correspondentes do leste asiático.

Exemplos de conjuntos de dados do artigo de 2020 ‘Asian Female Facial Beauty Prediction Using Deep Neural Networks via Transfer Learning and Multi-Channel Feature Fusion’. Fonte: https://www.semanticscholar.org/paper/Asian-Female-Facial-Beauty-Prediction-Using-Deep-Zhai-Huang/59776a6fb0642de5338a3dd9bac112194906bf30
Usos comerciais mais amplos para a estimativa de beleza incluem aplicativos de namoro online e sistemas de IA generativa projetados para ‘aperfeiçoar’ imagens de avatares reais de pessoas (já que tais aplicações requerem um padrão quantizado de beleza como métrica de eficácia).
Desenhando Rostos
Indivíduos atraentes continuam a ser um ativo valioso em publicidade e construção de influência, tornando os incentivos financeiros nesses setores uma clara oportunidade para avançar conjuntos de dados e frameworks FAP de última geração.
Por exemplo, um modelo de IA treinado com dados do mundo real para avaliar e classificar a beleza facial poderia potencialmente identificar eventos ou indivíduos com alto potencial de impacto publicitário. Essa capacidade seria especialmente relevante em contextos de transmissão de vídeo ao vivo, onde métricas como ‘seguidores’ e ‘curtidas’ atualmente servem apenas como indicadores implícitos da capacidade de um indivíduo (ou mesmo de um tipo de rosto) de cativar uma audiência.
Este é um indicador superficial, é claro, e a voz, apresentação e ponto de vista também desempenham um papel significativo na atração do público. Portanto, a curadoria de conjuntos de dados FAP requer supervisão humana, bem como a capacidade de distinguir a atratividade facial da atratividade especiosa (sem o que influenciadores fora do domínio, como Alex Jones, poderiam acabar afetando a média curva FAP para uma coleção projetada unicamente para estimar a beleza facial).
LiveBeauty
Para abordar a escassez de conjuntos de dados FAP, pesquisadores da China estão oferecendo o primeiro conjunto de dados FAP em larga escala, contendo 100.000 imagens faciais, juntamente com 200.000 anotações humanas estimando a beleza facial.
Amostras do novo conjunto de dados LiveBeauty. Fonte: https://arxiv.org/pdf/2501.02509
Intitulado LiveBeauty, o conjunto de dados apresenta 10.000 identidades diferentes, todas capturadas de plataformas de transmissão ao vivo não especificadas em março de 2024.
Os autores também apresentam o FPEM, um novo método multi-modal de FAP. O FPEM integra conhecimento facial holístico e características estéticas multimodais por meio de um Módulo de Prioridade de Atração Personalizada (PAPM), um Módulo Codificador de Atração Multimodal (MAEM) e um Módulo de Fusão Transversal (CMFM).
O artigo alega que o FPEM alcança desempenho de ponta no novo conjunto de dados LiveBeauty, além de outros conjuntos de dados FAP. Os autores notam que a pesquisa tem aplicações potenciais para melhorar a qualidade de vídeo, recomendação de conteúdo e retoque facial em transmissões ao vivo.
Os autores também prometem disponibilizar o conjunto de dados ‘em breve’ – embora deva-se reconhecer que quaisquer restrições de licenciamento inerentes ao domínio de origem provavelmente serão transferidas para a maioria dos projetos aplicáveis que possam fazer uso do trabalho.
O novo artigo é intitulado Previsão de Atração Facial em Transmissões Ao Vivo: Um Novo Ponto de Referência e Método Multimodal, e é fruto do trabalho de dez pesquisadores do Alibaba Group e da Universidade Jiao Tong de Xangai.
Método e Dados
De cada transmissão de 10 horas nas plataformas de transmissão ao vivo, os pesquisadores coletaram uma imagem por hora durante as primeiras três horas. Transmissões com o maior número de visualizações foram selecionadas.
Os dados coletados passaram então por várias etapas de pré-processamento. A primeira delas é a medição do tamanho da região facial, que utiliza o modelo de detecção FaceBoxes de CPU de 2018 para gerar uma caixa delimitadora em torno das características faciais. O pipeline garante que o lado mais curto da caixa delimitadora exceda 90 pixels, evitando pequenas ou pouco claras regiões faciais.
A segunda etapa é a detecção de desfoque, que é aplicada à região facial usando a variância do operador Laplaciano no canal de altura (Y) do recorte facial. Essa variância deve ser maior que 10, o que ajuda a filtrar imagens desfocadas.
A terceira etapa é a estimação da pose facial, que utiliza o modelo de estimação de pose 3DDFA-V2 de 2021:

Exemplos do modelo de estimação 3DDFA-V2. Fonte: https://arxiv.org/pdf/2009.09960
Aqui o fluxo de trabalho garante que o ângulo de inclinação do rosto recortado não seja superior a 20 graus e que o ângulo de guinada não ultrapasse 15 graus, excluindo rostos com poses extremas.
A quarta etapa é a avaliação da proporção facial, que também utiliza as capacidades de segmentação do modelo 3DDFA-V2, garantindo que a proporção da região facial recortada seja superior a 60% da imagem, excluindo imagens onde o rosto não é proeminente, ou seja, pequenas em relação à imagem total.
Finalmente, a quinta etapa é a remoção de caracteres duplicados, que usa um modelo de reconhecimento facial de ponta (não atribuído), para casos onde a mesma identidade aparece em mais de uma das três imagens coletadas para um vídeo de 10 horas.
Avaliação e Anotação Humana
Vinte anotadores foram recrutados, consistindo em seis homens e 14 mulheres, refletindo a demografia da plataforma ao vivo utilizada*. Os rostos foram exibidos na tela de 6,7 polegadas de um iPhone 14 Pro Max, em condições laboratoriais consistentes.
A avaliação foi dividida em 200 sessões, cada uma usando 50 imagens. Os sujeitos foram solicitados a avaliar a atratividade facial das amostras em uma escala de 1 a 5, com uma pausa de cinco minutos imposta entre cada sessão, e todos os sujeitos participando de todas as sessões.
Dessa forma, a totalidade das 10.000 imagens foi avaliada por vinte sujeitos humanos, resultando em 200.000 anotações.
Análise e Pré-processamento
Primeiro, foi realizada uma triagem de sujeitos usando a razão de outliers e o Coeficiente de Correlação de Postagem de Spearman (SROCC). Os sujeitos cujas avaliações tinham um SROCC inferior a 0,75 ou uma razão de outliers superior a 2% foram considerados não confiáveis e foram removidos, resultando em 20 sujeitos finais.
Um Score de Opinião Média (MOS) foi então computado para cada imagem facial, ao calcular as médias das pontuações obtidas pelos sujeitos válidos. O MOS serve como o rótulo de atratividade da verdade fundamental para cada imagem, e a pontuação é calculada através da média de todas as pontuações individuais de cada sujeito válido.
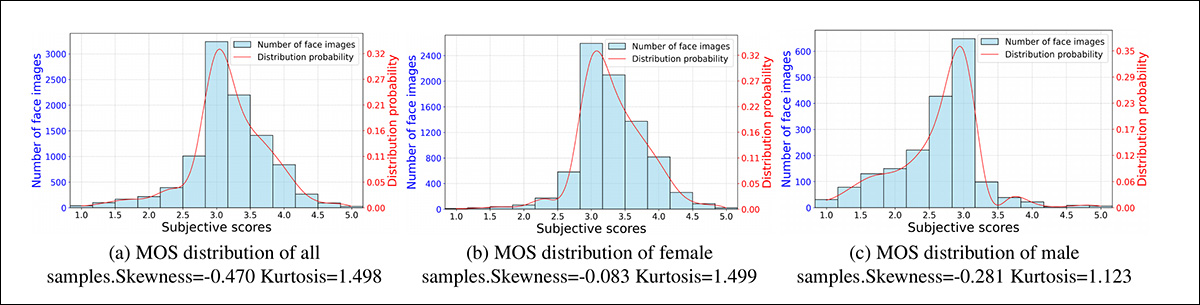
Finalmente, a análise das distribuições do MOS para todas as amostras, bem como para as amostras femininas e masculinas, indicou que apresentavam uma forma similar a Gauss, o que é consistente com as distribuições reais de atratividade facial:
Exemplos das distribuições MOS do LiveBeauty.
A maioria dos indivíduos tende a ter uma atratividade facial média, com menos indivíduos nas extremidades de atratividade muito baixa ou muito alta.
Além disso, a análise dos valores de assimetria e curtose mostrou que as distribuições foram caracterizadas por caudas finas e concentradas em torno da pontuação média, e que alta atratividade era mais prevalente entre as amostras femininas nos vídeos coletados da transmissão ao vivo.
Arquitetura
Uma estratégia de treinamento em duas etapas foi utilizada para o modelo Multi-modal Aprimorado de Prioridade Facial (FPEM) e a Fase de Fusão Híbrida no LiveBeauty, dividida em quatro módulos: um Módulo de Prioridade de Atração Personalizada (PAPM), um Módulo Codificador de Atração Multimodal (MAEM), um Módulo de Fusão Transversal (CMFM) e um Módulo de Fusão de Decisão (DFM).
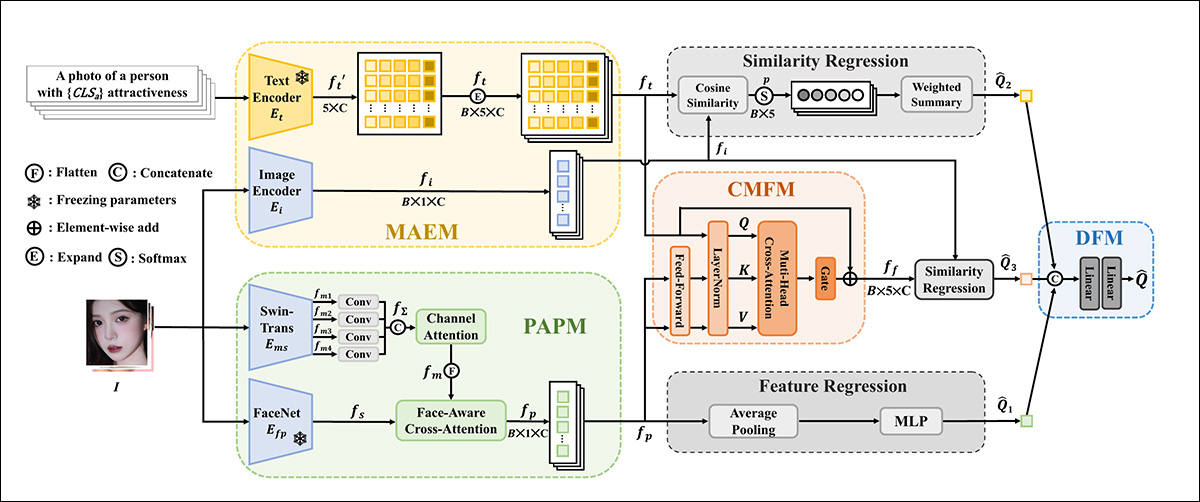
Esquema conceitual do pipeline de treinamento do LiveBeauty.
O módulo PAPM recebe uma imagem como entrada e extrai características visuais multiescala usando um Transformador Swin, além de extrair características sensíveis ao rosto utilizando um modelo FaceNet pré-treinado. Essas características são então combinadas usando um bloco de atenção cruzada para criar uma característica de ‘atratividade’ personalizada.
Também na Fase de Treinamento Preliminar, o MAEM utiliza uma imagem e descrições em texto de atratividade, aproveitando o CLIP para extrair características estéticas semânticas multimodais.
As descrições de texto formatadas estão na forma de ‘uma foto de uma pessoa com {a} atratividade’ (onde {a} pode ser má, pobre, justa, boa ou perfeita). O processo estima a similaridade coseno entre as incorporações textuais e visuais para chegar a uma probabilidade de nível de atratividade.
Na Fase de Fusão Híbrida, o CMFM refina as incorporações textuais usando a característica de atratividade personalizada gerada pelo PAPM, gerando assim incorporações textuais personalizadas. Em seguida, utiliza uma estratégia de regressão de similaridade para fazer uma previsão.
Por fim, o DFM combina as previsões individuais do PAPM, MAEM e CMFM para produzir uma única pontuação de atratividade final, com o objetivo de alcançar um consenso robusto.
Funções de Perda
Para métricas de perda, o PAPM é treinado usando uma perda L1, uma medida da diferença absoluta entre a pontuação de atratividade prevista e a pontuação de atratividade real (verdadeira).
O módulo MAEM utiliza uma função de perda mais complexa que combina uma perda de pontuação (LS) com uma perda de classificação mesclada (LR). A perda de classificação (LR) compreende uma perda de fidelidade (LR1) e uma perda de classificação bidirecional (LR2).
A LR1 compara a atratividade relativa de pares de imagens, enquanto a LR2 garante que a distribuição de probabilidade prevista dos níveis de atratividade tenha um pico único e diminua em ambas as direções. Essa abordagem combinada visa otimizar tanto a pontuação precisa quanto a correta classificação de imagens com base na atratividade.
O CMFM e o DFM são treinados usando uma simples perda L1.
Testes
Nos testes, os pesquisadores compararam o LiveBeauty com nove abordagens anteriores: ComboNet; 2D-FAP; REX-INCEP; CNN-ER (apresentado no REX-INCEP); MEBeauty; AVA-MLSP; TANet; Dele-Trans; e EAT.
Métodos de linha de base que seguem um protocolo de Avaliação Estética de Imagens (IAA) também foram testados. Estes foram ViT-B; ResNeXt-50; e Inception-V3.
Além do LiveBeauty, os outros conjuntos de dados testados foram SCUT-FBP5000 e MEBeauty. Abaixo, as distribuições de MOS desses conjuntos de dados são comparadas:
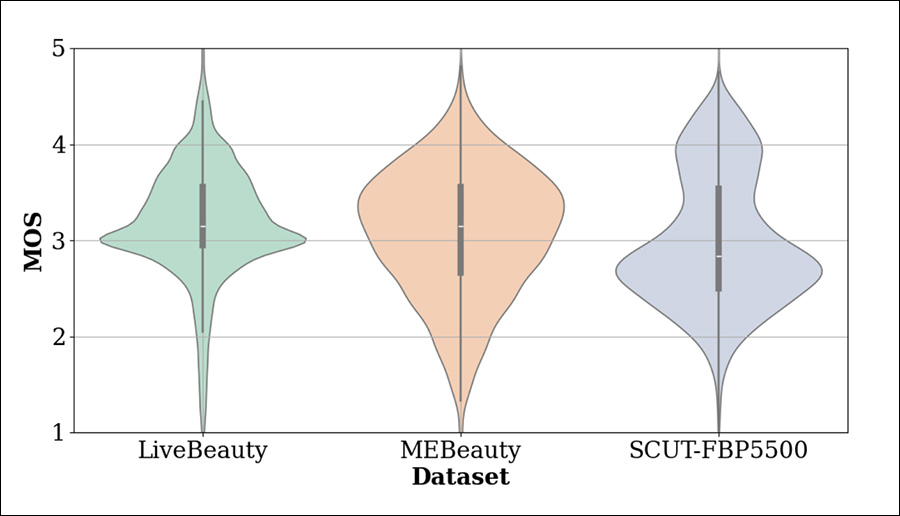
Distribuições de MOS dos conjuntos de dados de referência.
Respectivamente, esses conjuntos de dados convidados foram divididos 60%-40% e 80%-20% para treinamento e teste, separadamente, para manter a consistência com seus protocolos originais. O LiveBeauty foi dividido em uma base de 90%-10%.
Para a inicialização do modelo no MAEM, VT-B/16 e GPT-2 foram usados como os codificadores de imagem e texto, respectivamente, inicializados por configurações do CLIP. Para o PAPM, Swin-T foi usado como codificador de imagem treinável, de acordo com SwinFace.
O otimizador AdamW foi usado, e um agendador de taxa de aprendizado foi definido com aquecimento linear sob um esquema de aninhamento cosseno. As taxas de aprendizado diferiram nas fases de treinamento, mas cada uma teve um tamanho de lote de 32, durante 50 épocas.
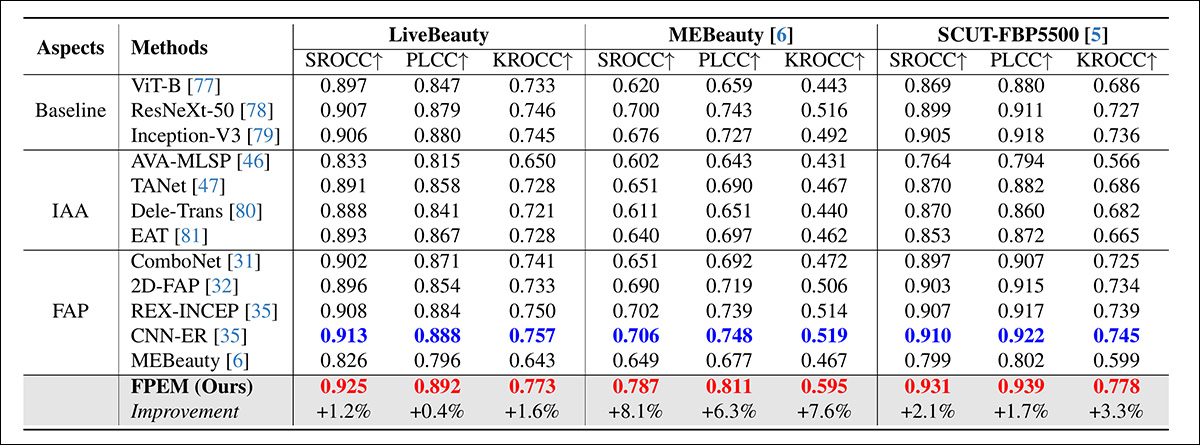
Resultados dos testes
Os resultados dos testes nos três conjuntos de dados FAP são mostrados acima. Desses resultados, o artigo afirma:
‘Nosso método proposto alcança o primeiro lugar e supera o segundo colocado em aproximadamente 0.012, 0.081, 0.021 em termos de valores SROCC no LiveBeauty, MEBeauty e SCUT-FBP5500, respectivamente, o que demonstra a superioridade do nosso método proposto.
‘[Os] métodos de IAA são inferiores aos métodos de FAP, o que manifesta que os métodos de avaliação estética genéricos ignoram as características faciais envolvidas na natureza subjetiva da atratividade facial, levando a um desempenho ruim nas tarefas de FAP.
‘[O] desempenho de todos os métodos cai significativamente no MEBeauty. Isso se deve ao fato de que as amostras de treinamento são limitadas e os rostos são etnicamente diversos no MEBeauty, indicando que há uma grande diversidade na atratividade facial.
‘Todos esses fatores tornam a previsão de atratividade facial no MEBeauty mais desafiadora.’
Considerações Éticas
A pesquisa sobre atratividade é uma busca potencialmente divisiva, pois ao estabelecer padrões supostamente empíricos de beleza, esses sistemas tendem a reforçar preconceitos em relação a idade, raça e muitas outras seções da pesquisa em visão computacional relacionada aos humanos.
Pode-se argumentar que um sistema FAP é inerentemente predisposto a reforçar e perpetuar perspectivas parciais e tendenciosas sobre atratividade. Esses julgamentos podem surgir de anotações lideradas por humanos – frequentemente realizadas em escalas demasiado limitadas para uma generalização eficaz do domínio – ou da análise de padrões de atenções em ambientes online como plataformas de streaming, que são, em certo sentido, longe de serem meritocráticas.
* O artigo refere-se ao(s) domínio(s) de origem não nomeados tanto no singular quanto no plural.
Publicada pela primeira vez na quarta-feira, 8 de janeiro de 2025.

Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…