


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder da indústria. Saiba Mais
À medida que as empresas continuam a adotar grandes modelos de linguagem (LLMs) em várias aplicações, um dos principais desafios que enfrentam é melhorar o conhecimento factual dos modelos e reduzir as alucinações. Em um novo artigo, pesquisadores da Meta AI propõem as “camadas de memória escaláveis,” que podem ser uma das várias soluções possíveis para esse problema.
As camadas de memória escaláveis adicionam mais parâmetros aos LLMs para aumentar sua capacidade de aprendizado sem exigir recursos computacionais adicionais. A arquitetura é útil para aplicações onde se pode dispor de memória extra para conhecimento factual, mas também se deseja a velocidade de inferência de modelos mais ágeis.
Camadas densas e de memória
Modelos de linguagem tradicionais utilizam “camadas densas” para codificar grandes quantidades de informação em seus parâmetros. Nas camadas densas, todos os parâmetros são usados em sua plena capacidade e geralmente são ativados ao mesmo tempo durante a inferência. As camadas densas podem aprender funções mais complexas à medida que crescem, mas aumentar seu tamanho exige recursos computacionais e energéticos adicionais.
Em contraste, para um conhecimento factual simples, camadas muito mais simples com arquiteturas de memória associativa semelhantes a tabelas de consulta seriam mais eficientes e interpretáveis. É isso que as camadas de memória fazem. Elas utilizam ativações esparsas simples e mecanismos de consulta chave-valor para codificar e recuperar conhecimento. As camadas esparsas ocupam mais memória do que as densas, mas usam apenas uma pequena parte dos parâmetros de cada vez, tornando-as muito mais eficientes em termos de computação.
As camadas de memória existem há vários anos, mas raramente são utilizadas em arquiteturas modernas de aprendizado profundo. Elas não são otimizadas para os aceleradores de hardware atuais.
Os LLMs de fronteira atuais costumam usar alguma forma de arquitetura “mistura de especialistas” (MoE), que utiliza um mecanismo vagamente semelhante às camadas de memória. Modelos MoE são compostos por muitos componentes especializados menores que se especializam em tarefas específicas. No momento da inferência, um mecanismo de roteamento determina qual especialista é ativado com base na sequência de entrada. O PEER, uma arquitetura desenvolvida recentemente pelo Google DeepMind, estende o MoE para milhões de especialistas, proporcionando um controle mais granular sobre os parâmetros que são ativados durante a inferência.
Atualizando as camadas de memória
As camadas de memória são leves em computação, mas pesadas em memória, o que apresenta desafios específicos para as atuais estruturas de hardware e software. Em seu artigo, os pesquisadores da Meta propõem várias modificações que solucionam esses desafios e tornam possível o uso delas em larga escala.
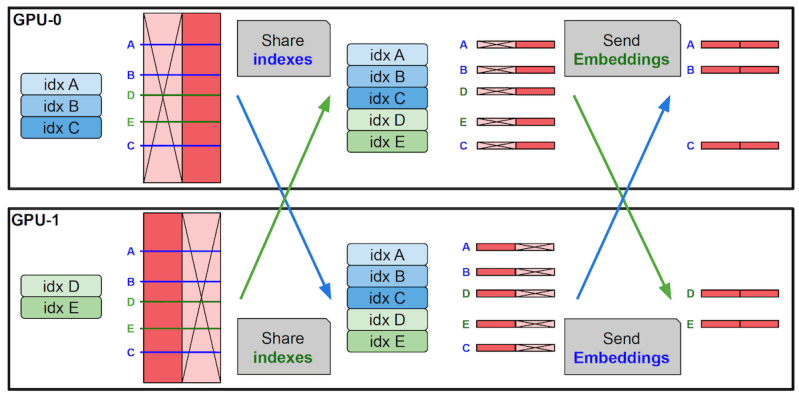
Primeiro, os pesquisadores configuraram as camadas de memória para paralelização, distribuindo-as entre vários GPUs para armazenar milhões de pares chave-valor sem alterar outras camadas no modelo. Eles também implementaram um kernel CUDA especial para lidar com operações de alta largura de banda de memória. E, desenvolveram um mecanismo de compartilhamento de parâmetros que suporta um único conjunto de parâmetros de memória em várias camadas de memória dentro de um modelo. Isso significa que as chaves e valores usados para consultas são compartilhados entre as camadas.
Essas modificações possibilitam a implementação de camadas de memória nos LLMs sem desacelerar o modelo.
“As camadas de memória com suas ativações esparsas complementam bem as redes densas, proporcionando maior capacidade de aquisição de conhecimento, enquanto são leves em computação,” escrevem os pesquisadores. “Elas podem ser escaladas de forma eficiente e oferecem aos praticantes uma nova direção atraente para equilibrar memória e computação.”
Para testar as camadas de memória, os pesquisadores modificaram os modelos Llama, substituindo uma ou mais camadas densas por uma camada de memória compartilhada. Eles compararam os modelos aprimorados pela memória contra os LLMs densos, assim como modelos MoE e PEER em várias tarefas, incluindo respostas a perguntas factuais, conhecimento científico e senso comum e programação.

Os resultados mostram que os modelos de memória melhoram significativamente em relação às linhas de base densas e competem com modelos que utilizam de 2 a 4 vezes mais computação. Eles também igualam o desempenho de modelos MoE que têm o mesmo orçamento de computação e contagem de parâmetros. O desempenho do modelo é especialmente notável em tarefas que requerem conhecimento factual. Por exemplo, em perguntas factuais, um modelo de memória com 1,3 bilhão de parâmetros se aproxima do desempenho do Llama-2-7B, que foi treinado em duas vezes mais tokens e 10X mais computação.
Além disso, os pesquisadores descobriram que os benefícios dos modelos de memória permanecem consistentes com o tamanho do modelo à medida que escalaram seus experimentos de 134 milhões a 8 bilhões de parâmetros.
“Diante desses achados, defendemos fortemente que as camadas de memória devem ser integradas em todas as próximas gerações de arquiteturas de IA,” escrevem os pesquisadores, acrescentando que ainda há muito espaço para melhorias. “Em particular, esperamos que novos métodos de aprendizado possam ser desenvolvidos para aumentar a eficácia dessas camadas ainda mais, possibilitando menos esquecimentos, menos alucinações e aprendizado contínuo.”


Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…