


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de liderança na indústria. Saiba mais
À medida que empresas em todo o mundo intensificam seus projetos de IA, a disponibilidade de dados de treinamento de alta qualidade se tornou um grande gargalo. Embora a web pública tenha sido amplamente esgotada como fonte de dados, grandes players como a OpenAI e o Google estão garantindo parcerias exclusivas para expandir seus conjuntos de dados proprietários, limitando ainda mais o acesso para outros.
Para abordar essa crescente preocupação, Salesforce deu um grande passo na área de dados de treinamento visual. A empresa acaba de introduzir o ProVision, uma estrutura inovadora que gera programaticamente dados de instrução visual. Esses conjuntos de dados são sistematicamente sintetizados para permitir o treinamento de modelos de linguagem multimodal (MLMs) de alto desempenho que podem responder a perguntas sobre imagens.
A empresa já lançou o conjunto de dados ProVision-10M com essa abordagem e o está utilizando para melhorar o desempenho e a precisão de vários modelos de IA multimodal.
Para profissionais de dados, essa estrutura representa um avanço significativo. Ao gerar programaticamente dados de instrução visual de alta qualidade, o ProVision alivia a dependência de conjuntos de dados limitados ou rotulados de forma inconsistente, um desafio comum no treinamento de sistemas multimodais.
Além disso, a capacidade de sintetizar conjuntos de dados de forma sistemática assegura melhor controle, escalabilidade e consistência, possibilitando ciclos de iteração mais rápidos e reduzindo o custo de aquisição de dados específicos de domínio. Esse trabalho complementa a pesquisa em andamento no domínio da geração de dados sintéticos e surge apenas um dia após o lançamento da Cosmos pela Nvidia, um conjunto de modelos fundamentais do mundo projetados para gerar vídeos baseados em física a partir de uma combinação de entradas, como texto, imagem e vídeo, para treinamento de IA física.
Dados de instrução visual: um ingrediente chave para IA multimodal
Atualmente, conjuntos de dados de instrução são o núcleo do pré-treinamento ou ajuste fino de IA. Esses conjuntos de dados especializados ajudam os modelos a seguir e responder efetivamente a instruções ou consultas específicas. No caso da IA multimodal, os modelos têm a capacidade de analisar conteúdos como imagens após aprender com uma variedade de diferentes pontos de dados, acompanhados por pares de perguntas e respostas — ou dados de instrução visual — que os descrevem.
Agora, aqui está a questão: produzir esses conjuntos de dados de instrução visual é bastante complicado. Se uma empresa cria os dados manualmente para cada imagem de treinamento, acaba desperdiçando muito tempo e recursos humanos para concluir o projeto. Por outro lado, se optar por usar modelos de linguagem proprietários para a tarefa, terá que lidar com altos custos computacionais e o risco de alucinações, onde a qualidade e a precisão dos pares de perguntas e respostas podem não ser boas o suficiente.
Além disso, o uso de modelos proprietários é também um mecanismo de caixa-preta, pois dificulta a interpretação do processo de geração de dados e o controle ou personalização precisa das saídas.
Chega o Salesforce ProVision
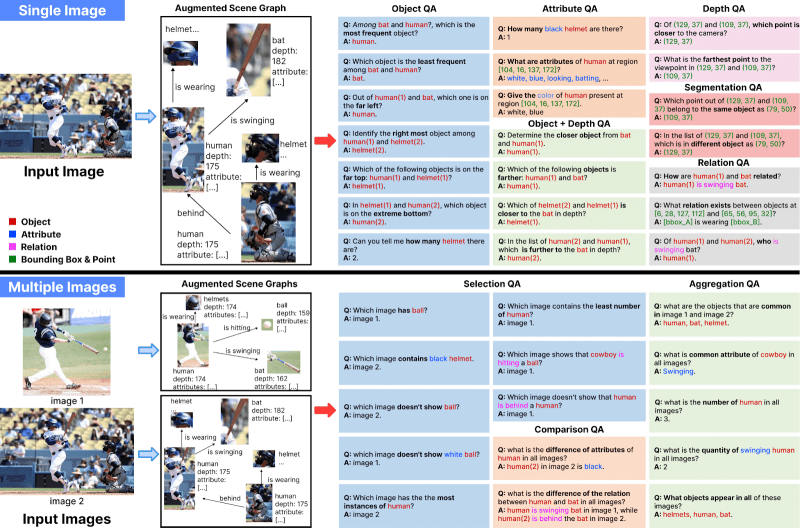
Para abordar essas lacunas, a equipe de pesquisa em IA da Salesforce criou o ProVision, uma estrutura que utiliza gráficos de cena em conjunto com programas escritos por humanos para sintetizar sistematicamente dados de instrução centrados na visão.
No núcleo, um gráfico de cena pode ser descrito como uma representação estruturada da semântica da imagem, onde os objetos no conteúdo são representados como nós. Os atributos de cada objeto — como cor ou tamanho — são atribuídos diretamente aos seus respectivos nós, enquanto as relações entre esses objetos são retratadas como arestas direcionadas conectando os nós correspondentes. Essas representações podem ser obtidas a partir de conjuntos de dados anotados manualmente, como o Visual Genome, ou podem ser geradas com a ajuda de um pipeline de geração de gráficos de cena que combina vários modelos de visão de última geração cobrindo vários aspectos da semântica da imagem, desde a detecção de objetos e atributos até a estimativa de profundidade.
Uma vez que os gráficos de cena estão prontos, eles alimentam programas escritos em Python e templates textuais que servem como geradores de dados completos capazes de criar pares de perguntas e respostas para pipelines de treinamento de IA.
“Cada [gerador de dados] utiliza centenas de templates pré-definidos, que integram sistematicamente essas anotações para produzir dados de instrução diversos. Esses geradores foram feitos para… comparar, recuperar e raciocinar sobre conceitos visuais básicos de objetos, atributos e relações com base nas informações detalhadas codificadas em cada gráfico de cena,” escreveram os pesquisadores por trás da estrutura em um artigo.
Conjunto de dados ProVision-10M para treinamento de IA
Em seu trabalho, a Salesforce utilizou ambas as abordagens — aumento de gráficos de cena anotados manualmente e geração do zero — para configurar gráficos de cena que alimentam 24 geradores de dados de imagem única e 14 geradores de múltiplas imagens.
“Com esses geradores de dados, podemos sintetizar automaticamente perguntas e respostas dadas a partir do gráfico de cena de uma imagem. Por exemplo, dada uma imagem de uma rua movimentada, o ProVision pode gerar perguntas como, “Qual é a relação entre o pedestre e o carro?” ou “Qual objeto está mais próximo do prédio vermelho, [o] carro ou o pedestre?” observaram os pesquisadores principais Jieyu Zhang e Le Xue em um post no blog.
Os geradores de dados com a primeira abordagem, aumentando os gráficos de cena do Visual Genome com anotações de profundidade e segmentação do Depth Anything V2 e SAM-2, ajudaram a criar 1,5 milhões de pontos de dados de instrução de imagem única e 4,2 milhões de pontos de dados de instrução de múltiplas imagens. Enquanto isso, a outra, utilizando 120.000 imagens de alta resolução do conjunto de dados DataComp e modelos como Yolo-World, Coca, Llava-1.5 e Osprey, gerou 2,3 milhões de pontos de dados de instrução de imagem única e 4,2 milhões de pontos de dados de instrução de múltiplas imagens.
No total, as quatro divisões combinadas constituem o ProVision-10M, um conjunto de dados com mais de 10 milhões de pontos de dados de instrução únicos. Ele já está disponível no Hugging Face e já está se mostrando muito eficaz em pipelines de treinamento de IA.
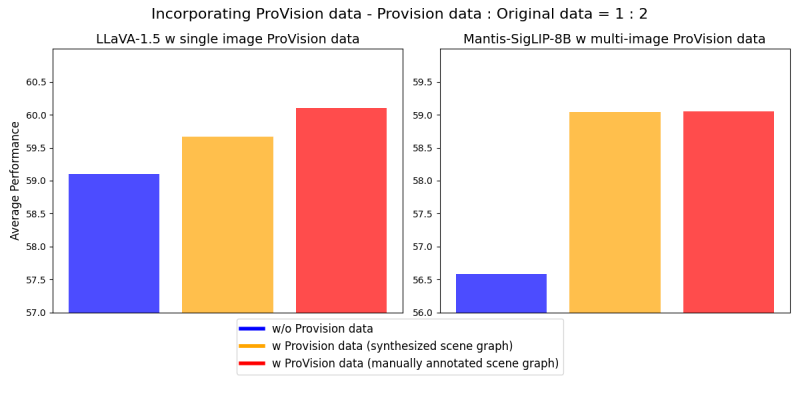
Especificamente, quando a empresa incorporou o ProVision-10M nas receitas de ajuste fino de IA multimodal — LLaVA-1.5 para dados de instrução de imagem única e Mantis-SigLIP-8B para dados de instrução de múltiplas imagens — observou melhorias notáveis, com a média de desempenho dos modelos sendo superior em comparação ao ajuste fino sem dados do ProVision.
“Quando adotados na fase de ajuste de instrução, nossos dados de instrução de imagem única resultam em uma melhoria de até 7% na divisão 2D e 8% na divisão 3D do CVBench, juntamente com um aumento de 3% no desempenho no QBench2, RealWorldQA e MMMU. Nossos dados de instrução de múltiplas imagens levam a uma melhoria de 8% no Mantis-Eval,” notaram os pesquisadores no artigo.
Dados sintéticos vieram para ficar
Embora existam várias ferramentas e plataformas, incluindo os novos modelos de fundação do mundo Cosmos da Nvidia, para gerar diferentes modalidades de dados (de imagens a vídeos) que podem ser usados para treinamento de IA multimodal, apenas alguns abordaram o problema da criação dos conjuntos de dados de instrução que emparelham com esses dados.
A Salesforce está abordando esse gargalo com o ProVision, oferecendo às empresas uma maneira de ir além da rotulagem manual ou de modelos de linguagem de caixa-preta. A abordagem de gerar dados de instrução programaticamente garante interpretabilidade e controlabilidade do processo de geração e escala de maneira eficiente, mantendo a precisão factual.
No longo prazo, a empresa espera que os pesquisadores possam construir sobre esse trabalho para aprimorar os pipelines de geração de gráficos de cena e criar mais geradores de dados cobrindo novos tipos de dados de instrução, como os para vídeos.


Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…