


Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder de mercado. Saiba mais
A era da IA com raciocínio já está em andamento.
Depois que a OpenAI mais uma vez deu início a uma revolução da IA com seu modelo de raciocínio o1, introduzido em setembro de 2024 — que leva mais tempo para responder a perguntas, mas com a recompensa de maior desempenho, especialmente em problemas complexos e de múltiplas etapas em matemática e ciência — o campo comercial da IA foi inundado com imitadores e concorrentes.
Temos o R1 da DeepSeek, o Google Gemini 2 Flash Thinking, e hoje, LlamaV-o1, todos buscando oferecer um raciocínio “embutido” semelhante ao novo o1 da OpenAI e suas próximas famílias de modelos o3. Esses modelos utilizam “prompting em cadeia de pensamento” (CoT) — ou “auto-prompting” — forçando-os a refletir sobre sua análise durante o processo, revisar, conferir seu próprio trabalho e, assim, chegar a uma resposta melhor do que simplesmente dispará-la de suas embeddings o mais rápido possível, como outros modelos de linguagem grande (LLMs) fazem.
No entanto, o alto custo do o1 e do o1-mini ($15,00/1M tokens de entrada em comparação com $1,25/1M tokens de entrada para o GPT-4o na API da OpenAI) fez com que alguns hesitassem em aceitar os supostos ganhos de desempenho. Vale realmente a pena pagar 12 vezes mais do que o típico LLM de ponta?
Acontece que há um número crescente de convertidos — mas a chave para desbloquear o verdadeiro valor dos modelos de raciocínio pode estar em como os usuários os instruem.
Shawn Wang (fundador do serviço de notícias sobre IA Smol) apresentou em seu Substack no último fim de semana uma postagem convidada de Ben Hylak, ex-designer de interface da Apple Inc. para o visionOS (que alimenta o headset de computação espacial Vision Pro). A postagem se tornou viral ao explicar de forma convincente como Hylak instrui o modelo o1 da OpenAI para obter resultados extremamente valiosos para ele.
Em resumo, em vez de o usuário humano escrever prompts para o modelo o1, eles devem pensar em redigir “briefings”, ou explicações mais detalhadas que incluam muitos contextos iniciais sobre o que o usuário deseja que o modelo produza, quem o usuário é e em que formato eles querem que o modelo apresente as informações.
Como Hylak escreve em Substack:
Com a maioria dos modelos, fomos treinados para dizer ao modelo como queremos que ele nos responda. Por exemplo, ‘Você é um engenheiro de software especialista. Pense lentamente e cuidadosamente’
Esta é a abordagem oposta que encontrei para ter sucesso com o o1. Não o instrui sobre o ‘como’ — apenas sobre o ‘o quê’. Então, deixo o o1 assumir e planejar e resolver seus próprios passos. É para isso que serve o raciocínio autônomo, e na verdade pode ser muito mais rápido do que você revisar manualmente e conversar como o “humano na loop”.
Hylak também inclui uma excelente captura de tela anotada de um exemplo de prompt para o o1 que produziu resultados úteis para uma lista de trilhas:

Esta postagem do blog foi tão útil que o próprio presidente e cofundador da OpenAI, Greg Brockman, a compartilhou em sua conta do X com a mensagem: “o1 é um tipo diferente de modelo. Um ótimo desempenho requer usá-lo de uma nova maneira em relação aos modelos de bate-papo padrão.”
Eu experimentei isso pessoalmente em minha busca recorrente para aprender a falar espanhol fluentemente e aqui está o resultado, para os curiosos. Talvez não tão impressionante quanto o bem construído prompt e resposta de Hylak, mas definitivamente mostrando forte potencial.
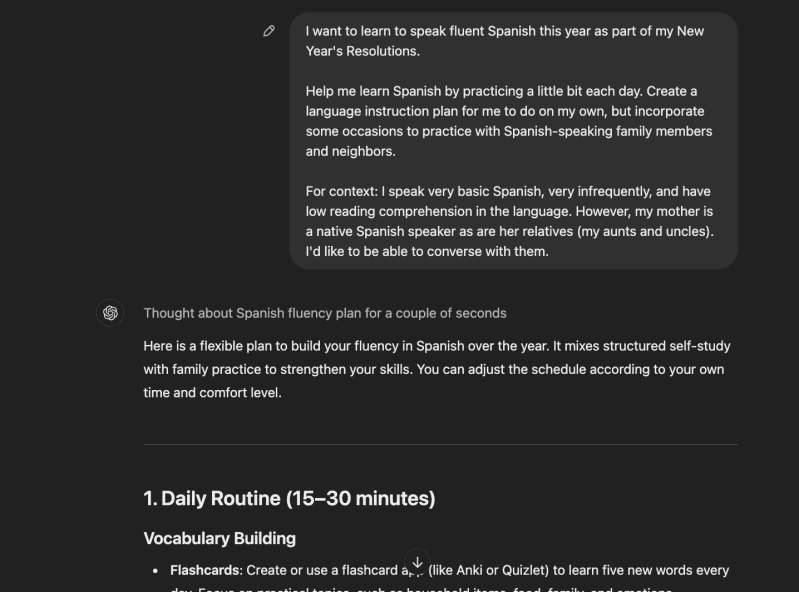
Separadamente, mesmo quando se trata de LLMs não-raciocínio, como o Claude 3.5 Sonnet, pode haver espaço para usuários regulares melhorarem seus prompts para obter melhores resultados, menos restritos.
Como escreveu Louis Arge, ex-engenheiro da Teton.ai e atual criador do dispositivo de neuromodulação openFUS, no X, “uma dica que descobri é que os LLMs confiam mais em seus próprios prompts do que em meus prompts”, e forneceu um exemplo de como convenceu o Claude a ser “menos covarde” ao primeiro “provocar uma briga” com ele sobre seus resultados.
Tudo isso mostra que a engenharia de prompts continua sendo uma habilidade valiosa à medida que a era da IA avança.


Conteúdo relacionado

OpenAI está supostamente em negociações para comprar a Windsurf por $3 bilhões, com novidades esperadas para esta semana.
[the_ad id="145565"] A Windsurf, fabricante de um popular assistente de codificação por IA, está em negociações para ser adquirida pela OpenAI por cerca de $3 bilhões, segundo…

A OpenAI procurou o criador do Cursor antes de iniciar negociações para comprar a Windsurf por $3 bilhões.
[the_ad id="145565"] Quando a notícia de que a OpenAI estava em negociações para adquirir a empresa de codificação AI Windsurf por $3 bilhões surgiu, uma das primeiras…

Como a IA está redesenhando os mapas de eletricidade do mundo: Insights do Relatório da AIE
[the_ad id="145565"] A inteligência artificial (IA) não está apenas transformando a tecnologia; ela também está mudando de forma significativa o setor energético global. De…