


A recente liberação pública do modelo de IA generativa de vídeo Hunyuan intensificou as discussões em andamento sobre a possibilidade de que grandes modelos multimodais de visão-linguagem um dia criem filmes inteiros.
No entanto, como temos observado, essa é uma perspectiva bastante distante no momento, por diversas razões. Uma delas é a janela de atenção muito curta da maioria dos geradores de vídeo de IA, que têm dificuldades em manter a consistência mesmo em uma única tomada breve, quanto mais em uma série de tomadas.
Outra razão é que referências consistentes ao conteúdo de vídeo (como ambientes exploráveis, que não deveriam mudar aleatoriamente se você refizer seus passos através deles) podem ser alcançadas nos modelos de difusão por meio de técnicas de personalização, como a adaptação de baixa classificação (LoRA), que limita as capacidades prontas para uso dos modelos fundamentais.
Portanto, a evolução do vídeo gerado parece destinada a estagnar a menos que novas abordagens para a continuidade narrativa sejam desenvolvidas.
Receita para a Continuidade
Click para reproduzir. O projeto VideoAuteur sistematiza a análise de partes de um processo culinário, para produzir um novo conjunto de dados finamente legendados e um método de orquestração para a geração de vídeos de culinária. Consulte o site de origem para resolução superior. Fonte: https://videoauteur.github.io/
Tintulado VideoAuteur, o trabalho propõe um pipeline de duas etapas para gerar vídeos de culinária instrutivos utilizando estados coesos que combinam quadros-chave e legendas, alcançando resultados de ponta em um espaço notavelmente subdimensionado.
A página do projeto VideoAuteur também inclui vários vídeos bastante mais chamativos que usam a mesma técnica, como um trailer proposto para um crossover (inexistente) da Marvel/DC:
Click para reproduzir. Dois super-heróis de universos alternativos se encontram em um trailer falso do VideoAuteur. Consulte o site de origem para resolução superior.
A página também apresenta vídeos promocionais de estilo semelhante para uma série animal da Netflix igualmente inexistente e um anúncio de carro da Tesla.
Na elaboração do VideoAuteur, os autores experimentaram diversas funções de perda e outras abordagens novas. Para desenvolver um fluxo de trabalho de geração de receitas, eles também curaram o CookGen, o maior conjunto de dados focado no domínio da culinária, contendo 200.000 clipes de vídeo com uma duração média de 9,5 segundos.
Com uma média de 768,3 palavras por vídeo, o CookGen é de longe o conjunto de dados mais extensivamente anotado de seu tipo. Modelos de visão/língua diversos foram utilizados, entre outras abordagens, para garantir que as descrições fossem o mais detalhadas, relevantes e precisas possíveis.
Os vídeos de culinária foram escolhidos porque as instruções de culinária apresentam uma narrativa estruturada e inequívoca, tornando a anotação e a avaliação uma tarefa mais fácil. Exceto por vídeos pornográficos (que provavelmente entrarão nesse espaço particular em breve), é difícil pensar em outro gênero que seja tão ‘fórmula’ visual e narrativamente.
Os autores afirmam:
‘Nosso proposto pipeline auto-regressivo de duas etapas, que inclui um diretor narrativo longo e geração de vídeo condicionada visualmente, demonstra melhorias promissoras em consistência semântica e fidelidade visual em vídeos gerados de longas narrativas.
‘Através de experimentos em nosso conjunto de dados, observamos melhorias na coerência espacial e temporal entre as sequências de vídeo.
‘Esperamos que nosso trabalho possa facilitar novas pesquisas na geração de vídeos narrativos longos.’
O novo trabalho intitula-se VideoAuteur: Towards Long Narrative Video Generation, e é produto da colaboração de oito autores da Johns Hopkins University, ByteDance e ByteDance Seed.
Curadoria do Conjunto de Dados
Para desenvolver o CookGen, que alimenta um sistema gerativo de duas etapas para a produção de vídeos de culinária com IA, os autores utilizaram material das coleções YouCook e HowTo100M. Os autores comparam a escala do CookGen com conjuntos de dados anteriores focados no desenvolvimento narrativo em vídeo generativo, como o conjunto de dados Flintstones, o conjunto de dados de cartoon Pororo, StoryGen, o StoryStream da Tencent, e VIST.
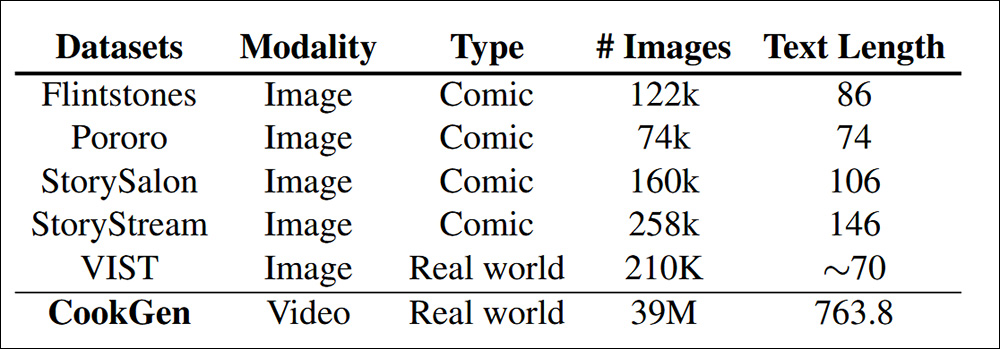
Comparação de imagens e comprimentos de texto entre CookGen e os conjuntos de dados semelhantes mais populosos. Fonte: https://arxiv.org/pdf/2501.06173
O CookGen foca em narrativas do mundo real, particularmente atividades processuais como a culinária, oferecendo histórias mais claras e fáceis de anotar em comparação com conjuntos de dados de quadrinhos baseados em imagens. Ele supera o maior conjunto de dados existente, StoryStream, com 150 vezes mais quadros e 5 vezes mais descrições textuais densas.
Os pesquisadores ajustaram um modelo de legenda utilizando a metodologia de LLaVA-NeXT como base. As pseudo-classes de reconhecimento automático de fala (ASR) obtidas para o HowTo100M foram usadas como ‘ações’ para cada vídeo e depois refinadas por grandes modelos de linguagem (LLMs).
Por exemplo, ChatGPT-4o foi utilizado para produzir um conjunto de dados de legendas, sendo solicitado a se concentrar em interações sujeito-objeto (como mãos manuseando utensílios e alimentos), atributos dos objetos e dinâmicas temporais.
Como os scripts de ASR provavelmente conterão imprecisões e serão geralmente ‘ruidosos’, a Interseção sobre a União (IoU) foi usada como uma métrica para medir quão de perto as legendas se conformavam à seção do vídeo que estavam abordando. Os autores observam que isso foi crucial para a criação de uma consistência narrativa.
Os clipes curados foram avaliados usando a Distância Fréchet de Vídeo (FVD), que mede a disparidade entre exemplos da verdade fundamental (mundo real) e exemplos gerados, tanto com quanto sem quadros-chave da verdade fundamental, resultando em um desempenho satisfatório:
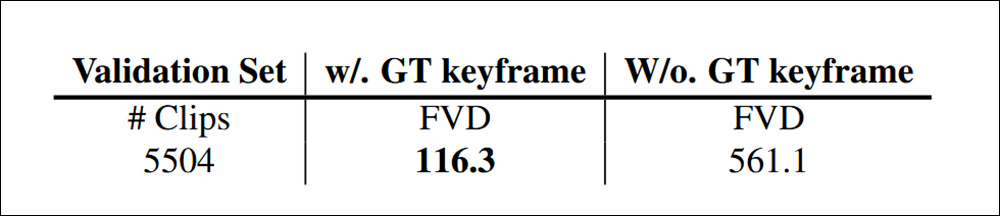
Usando FVD para avaliar a distância entre vídeos gerados com as novas legendas, tanto com quanto sem o uso de quadros-chave capturados dos vídeos amostrais.
Além disso, os clipes foram avaliados tanto por GPT-4o quanto por seis anotadores humanos, seguindo a definição de ‘alucinação’ do LLaVA-Hound (ou seja, a capacidade de um modelo de inventar conteúdo espúrio).
Os pesquisadores compararam a qualidade das legendas com a coleção Qwen2-VL-72B, obtendo uma pontuação ligeiramente melhorada.

Comparação de pontuações de FVD e avaliação humana entre Qwen2-VL-72B e a coleção dos autores.
Método
A fase generativa do VideoAuteur é dividida entre o Diretor Narrativo Longo (LND) e o modelo de geração de vídeo condicionado visualmente (VCVGM).
O LND gera uma sequência de embeddings visuais ou quadros-chave que caracterizam o fluxo narrativo, semelhante a ‘destaques essenciais’. O VCVGM gera clipes de vídeo com base nessas escolhas.
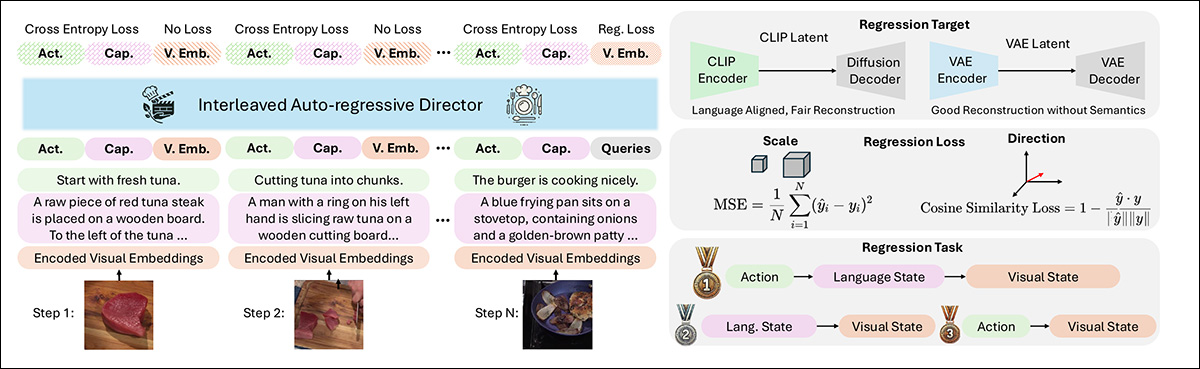
Esquema para o uso do processamento do VideoAuteur. O Diretor de Vídeo Narrativo Longo faz seleções apropriadas para alimentar o módulo gerativo alimentado por Seed-X.
Os autores discutem extensivamente os diferentes méritos de um diretor de imagem-texto intercalado e um diretor de quadros-chave centrado na linguagem, e concluem que o primeiro é a abordagem mais eficaz.
O diretor de imagem-texto intercalado gera uma sequência intercalando tokens de texto e embeddings visuais, usando um modelo auto-regressivo para prever o próximo token, com base no contexto combinado de texto e imagens. Isso garante um alinhamento estreito entre visuais e texto.
Em contraste, o diretor de quadro-chave centrado na linguagem sintetiza quadros-chave usando um modelo de difusão condicionado por texto, baseando-se apenas nas legendas, sem incorporar embeddings visuais no processo de geração.
Os pesquisadores descobriram que, embora o método centrado na linguagem gere quadros-chave visualmente atraentes, ele carece de consistência entre os quadros, argumentando que o método intercalado alcança pontuações mais altas em realismo e consistência visual. Eles também constataram que esse método foi melhor capaz de aprender um estilo visual realista através do treinamento, embora às vezes com alguns elementos repetitivos ou ruidosos.
Incomumente, em uma vertente de pesquisa dominada pela apropriação do Stable Diffusion e do Flux em fluxos de trabalho, os autores usaram o SEED-X, um modelo LLM multimodal de 7 bilhões de parâmetros da Tencent, para seu pipeline generativo (embora este modelo aproveite a liberação SDXL do Stable Diffusion para uma parte limitada de sua arquitetura).
Os autores afirmam:
‘Diferente do pipeline clássico de Imagem para Vídeo (I2V), que usa uma imagem como o quadro inicial, nossa abordagem aproveita [latentes visuais regressados] como condições contínuas ao longo da [sequência].
‘Além disso, melhoramos a robustez e a qualidade dos vídeos gerados adaptando o modelo para lidar com embeddings visuais ruidosos, uma vez que os latentes visuais regressados podem não ser perfeitos devido a erros de regressão.’
Embora os pipelines generativos condicionados visualmente típicos desse tipo frequentemente usem quadros-chave iniciais como ponto de partida para a orientação do modelo, o VideoAuteur expande esse paradigma gerando estados visuais multipartes em um espaço latente semanticamente coerente, evitando o potencial viés de basear a geração subsequente apenas em ‘quadros iniciais’.
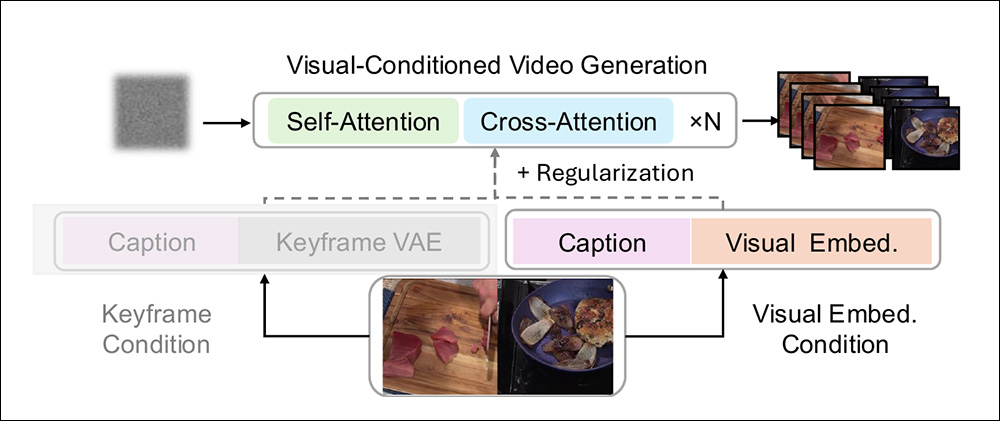
Esquema para o uso de embeddings de estados visuais como um método de condicionamento superior.
Testes
Em linha com os métodos de SeedStory, os pesquisadores usam SEED-X para aplicar ajuste fino LoRA em seu conjunto de dados narrativo, descrevendo enigmaticamente o resultado como um ‘modelo semelhante ao Sora’, pré-treinado em grandes acoplamentos de vídeo/texto e capaz de aceitar prompts e condições visuais e textuais.
32.000 vídeos narrativos foram utilizados para o desenvolvimento do modelo, com 1.000 reservados como amostras de validação. Os vídeos foram cortados para 448 pixels no lado mais curto e depois centralizados para 448x448px.
Para o treinamento, a geração narrativa foi avaliada principalmente no conjunto de validação YouCook2. O conjunto Howto100M foi utilizado para avaliação da qualidade dos dados e também para geração de imagem para vídeo.
Para a perda de condicionamento visual, os autores usaram perda de difusão do DiT e um trabalho de 2024 baseado no Stable Diffusion.
Para provar sua afirmação de que a interlevação é uma abordagem superior, os autores confrontaram o VideoAuteur com vários métodos que dependem exclusivamente de entrada baseadas em texto: EMU-2, SEED-X, SDXL e FLUX.1-schnell (FLUX.1-s).

Dado um prompt global, ‘Guia passo a passo para cozinhar mapo tofu’, o diretor intercalado gera ações, legendas e embeddings de imagens sequencialmente para narrar o processo. As duas primeiras linhas mostram quadros-chave decodificados dos espaços latentes EMU-2 e SEED-X. Essas imagens são realistas e consistentes, mas menos polidas do que as de modelos avançados como SDXL e FLUX.
Os autores afirmam:
‘A abordagem centrada na linguagem usando modelos texto-imagem produz quadros-chave visualmente atraentes, mas sofre com uma falta de consistência entre os quadros devido à informação mútua limitada. Em contraste, o método de geração intercalada aproveita latentes visuais alinhados à linguagem, alcançando um estilo visual realista através do treinamento.
‘No entanto, ocasionalmente gera imagens com elementos repetitivos ou ruidosos, já que o modelo auto-regressivo tem dificuldade em criar embeddings precisos em uma única passagem.’
A avaliação humana confirma ainda mais a afirmação dos autores sobre o desempenho melhorado da abordagem intercalada, com métodos intercalados alcançando as maiores pontuações em uma pesquisa.
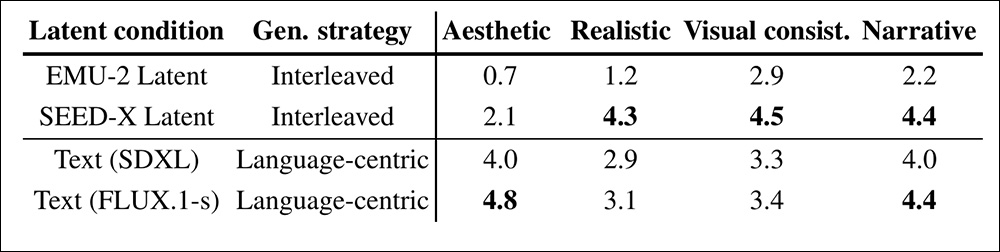
Comparação de abordagens a partir de um estudo humano conduzido para o artigo.
No entanto, observamos que as abordagens centradas na linguagem alcançam as melhores pontuações estéticas. Os autores contendem, no entanto, que essa não é a questão central na geração de vídeos narrativos longos.
Click para reproduzir. Segmentos gerados para um vídeo de construção de pizza, pelo VideoAuteur.
Conclusão
A corrente mais popular de pesquisa em relação a esse desafio, ou seja, a consistência narrativa na geração de vídeos de longa duração, está preocupada com imagens únicas. Projetos desse tipo incluem DreamStory, StoryDiffusion, TheaterGen e a ConsiStory da NVIDIA.
De certa forma, o VideoAuteur também se encaixa nessa categoria ‘estática’, uma vez que utiliza imagens-semente a partir das quais se geram seções de clipes. No entanto, a interlevação do vídeo e conteúdo semântico traz o processo um passo mais próximo de um pipeline prático.
Publicação original na quinta-feira, 16 de janeiro de 2025

Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…