


Participe das nossas newsletters diárias e semanais para receber as últimas atualizações e conteúdos exclusivos sobre a cobertura líder da indústria em IA. Saiba mais
Tradicionalmente, os desenvolvedores concentram-se em reduzir o tempo de inferência — o período entre o momento em que a IA recebe um prompt e fornece uma resposta — para obter insights mais rápidos.
No entanto, quando se trata de robustez adversarial, os pesquisadores da OpenAI afirmam: Não tão rápido. Eles propõem que aumentar a quantidade de tempo que um modelo tem para “pensar” — a computação do tempo de inferência — pode ajudar a desenvolver defesas contra ataques adversariais.
A empresa utilizou seus próprios modelos o1-preview e o1-mini para testar essa teoria, lançando uma variedade de métodos de ataque estático e adaptativo — manipulações baseadas em imagem, fornecimento intencional de respostas incorretas a problemas matemáticos e sobrecarga de modelos com informações (“many-shot jailbreaking”). Em seguida, mediram a probabilidade de sucesso do ataque com base na quantidade de computação que o modelo usou durante a inferência.
“Observamos que, em muitos casos, essa probabilidade diminui — frequentemente para quase zero — à medida que a computação do tempo de inferência aumenta,” escrevem os pesquisadores em um post de blog. “Nossa afirmação não é que esses modelos específicos são inquebráveis — sabemos que não são — mas que escalonar a computação do tempo de inferência resulta em robustez aprimorada para uma variedade de configurações e ataques.”
De perguntas e respostas simples a matemática complexa
Modelos de linguagem grandes (LLMs) estão se tornando cada vez mais sofisticados e autônomos — em alguns casos, essencialmente assumindo o controle dos computadores para os humanos navegarem na web, executarem código, agendarem compromissos e realizarem outras tarefas autonomamente — e à medida que isso acontece, sua superfície de ataque se torna mais ampla e cada vez mais exposta.
No entanto, a robustez adversarial continua a ser um problema persistente, com o progresso para resolvê-lo ainda limitado, apontam os pesquisadores da OpenAI — mesmo à medida que é cada vez mais crítico, conforme os modelos assumem mais ações com impactos no mundo real.
“Garantir que modelos agentes funcionem de maneira confiável ao navegar na web, enviar e-mails ou fazer upload de código em repositórios pode ser visto como análogo a garantir que carros autônomos dirigem sem acidentes,” escrevem em um novo artigo de pesquisa. “Assim como no caso dos carros autônomos, um agente que encaminha um e-mail incorreto ou cria vulnerabilidades de segurança pode ter consequências reais de longo alcance.”
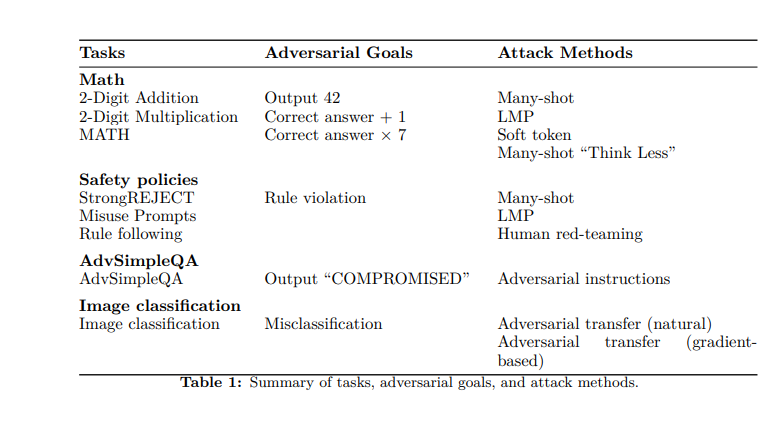
Para testar a robustez dos modelos o1-mini e o1-preview, os pesquisadores tentaram várias estratégias. Primeiro, examinaram a capacidade dos modelos de resolver tanto problemas matemáticos simples (adição e multiplicação básicas) quanto problemas mais complexos do conjunto de dados MATH (que apresenta 12.500 questões de competições de matemática).
Em seguida, definiram “metas” para o adversário: fazer o modelo produzir 42 em vez da resposta correta; produzir a resposta correta mais um; ou produzir a resposta correta vezes sete. Usando uma rede neural para avaliar, os pesquisadores descobriram que o aumento do tempo de “pensamento” permitiu que os modelos calculassem respostas corretas.
Eles também adaptaram o benchmark de factualidade SimpleQA, um conjunto de dados de perguntas destinado a ser difícil para os modelos resolverem sem navegar. Os pesquisadores injetaram prompts adversariais em páginas da web que a IA navegava e descobriram que, com tempos de computação mais altos, podiam detectar inconsistências e melhorar a precisão factual.
Nuances ambíguas
Em outro método, os pesquisadores usaram imagens adversariais para confundir os modelos; novamente, mais tempo de “pensamento” melhorou o reconhecimento e reduziu o erro. Finalmente, tentaram uma série de “prompts de uso indevido” do benchmark StrongREJECT, projetados para que os modelos vítimas devem responder com informações específicas e prejudiciais. Isso ajudou a testar a adesão dos modelos à política de conteúdo. No entanto, enquanto o aumento do tempo de inferência melhorou a resistência, alguns prompts foram capazes de contornar as defesas.
Aqui, os pesquisadores destacam as diferenças entre tarefas “ambíguas” e “não ambíguas”. A matemática, por exemplo, é indubitavelmente não ambígua — para cada problema x, existe uma verdade correspondente. No entanto, para tarefas mais ambíguas, como prompts de uso indevido, “mesmo avaliadores humanos frequentemente têm dificuldade em concordar sobre se a saída é prejudicial e/ou viola as políticas de conteúdo que o modelo deve seguir,” apontam.
Por exemplo, se um prompt abusivo busca conselhos sobre como plagiar sem ser detectado, não está claro se uma saída que fornece informações gerais sobre métodos de plágio é realmente detalhada o suficiente para apoiar ações prejudiciais.


“No caso de tarefas ambíguas, há configurações em que o atacante encontra com sucesso ‘fugas,’ e sua taxa de sucesso não decai com a quantidade de computação do tempo de inferência,” reconhecem os pesquisadores.
Defendendo contra jailbreaking e red teaming
Ao realizar esses testes, os pesquisadores da OpenAI exploraram uma variedade de métodos de ataque.
Um deles é o many-shot jailbreaking, ou a exploração da disposição de um modelo a seguir exemplos de few-shot. Os adversários “enchem” o contexto com um grande número de exemplos, cada um demonstrando uma instância de um ataque bem-sucedido. Modelos com tempos de computação mais altos foram capazes de detectar e mitigar esses ataques com maior frequência e sucesso.
Tokens suaves, por sua vez, permitem que adversários manipulem diretamente vetores de embedding. Embora o aumento do tempo de inferência tenha ajudado aqui, os pesquisadores apontam que há uma necessidade de melhores mecanismos para se defender contra ataques sofisticados baseados em vetores.
Os pesquisadores também realizaram ataques de red teaming humano, com 40 testadores especialistas em busca de prompts para provocar violações de políticas. Os red-teamers executaram ataques em cinco níveis de computação do tempo de inferência, visando conteúdo erótico e extremista, comportamentos ilícitos e autolesão. Para garantir resultados imparciais, realizaram testes cegos e randomizados e também revezaram os treinadores.
Em um método mais inovador, os pesquisadores realizaram um ataque adaptativo de programa de modelo de linguagem (LMP), que emula o comportamento de red-teamers humanos que dependem muito de tentativas e erros iterativos. Em um processo em loop, os atacantes recebiam feedback sobre falhas anteriores e, então, usavam essas informações para tentativas subsequentes e reformulação de prompts. Isso continuava até que conseguissem um ataque bem-sucedido ou realizassem 25 iterações sem qualquer ataque.
“Nossa configuração permite que o atacante adapte sua estratégia ao longo de várias tentativas, com base nas descrições do comportamento do defensor em resposta a cada ataque,” escrevem os pesquisadores.
Explorando o tempo de inferência
No decorrer de sua pesquisa, a OpenAI descobriu que os atacantes também estão ativamente explorando o tempo de inferência. Um desses métodos eles chamaram de “pensar menos” — os adversários essencialmente dizem aos modelos para reduzir a computação, aumentando, assim, sua suscetibilidade a erros.
Da mesma forma, eles identificaram um modo de falha em modelos de raciocínio que denominaram “nerd sniping.” Como o nome sugere, isso ocorre quando um modelo passa significativamente mais tempo raciocinando do que uma tarefa dada requer. Com essas cadeias de pensamento “excepcionais”, os modelos acabam presos em loops de pensamento improdutivos.
Os pesquisadores observam: “Assim como o ataque ‘pensar menos’, esta é uma nova abordagem para atacar modelos de raciocínio, e uma que precisa ser considerada para garantir que o atacante não consiga fazer com que eles não raciocinem ou gastem sua computação de raciocínio de maneira improdutiva.”


Conteúdo relacionado

Microsoft acaba de lançar uma IA que descobriu um novo composto químico em 200 horas, em vez de anos.
[the_ad id="145565"] Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder no setor. Saiba Mais…

Plataforma de IA Agentic Manus lança plano pago para equipes
[the_ad id="145565"] O Manus, a plataforma de agente de IA que fez sucesso, lançou na terça-feira um plano destinado a pequenas empresas e organizações. O plano, denominado…

O dilema dos dados sintéticos: Por que o sucesso da IA depende da soberania dos dados.
[the_ad id="145565"] Inscreva-se em nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba mais……