


Prever estados futuros é uma missão crítica na pesquisa de visão computacional – especialmente na robótica, onde as situações do mundo real devem ser consideradas. Sistemas de aprendizado de máquina encarregados de tarefas mission-critical, portanto, precisam de uma compreensão adequada do mundo físico.
No entanto, em alguns casos, um conhecimento aparentemente impressionante da realidade temporal pode ser enganoso: um novo artigo dos Emirados Árabes Unidos descobriu que os Modelos de Linguagem Multimodal de Última Geração (MLLMs), incluindo líderes de setor como GPT-4o e Google Gemini, ficam aquém quando se trata de interpretar como o tempo é representado em imagens.
Pares sequenciais de exemplos (veja a imagem abaixo), que seriam desafiadores para os humanos mesmo quando colocados na ordem errada, podem confundir MLLMs avançados quando apresentados em contextos ou configurações inesperadas (como a segunda imagem primeiro, concatenadas em uma seule imagem, sequências múltiplas de imagens que podem ou não representar a ordem temporal correta, e assim por diante).

Amostras de um dos conjuntos de dados compilados para o novo estudo, que mostram eventos sequenciais na forma de imagens de ‘antes e depois’. Os pesquisadores disponibilizaram esses dados em https://huggingface.co/datasets/fazliimam/temporal-vqa/viewer
Os pesquisadores encarregaram os modelos com desafios básicos de raciocínio temporal, como determinar a ordem dos eventos ou estimar lacunas de tempo, e encontraram que os sete MLLMs testados apresentaram desempenho notavelmente abaixo da precisão humana:
‘No geral, os [resultados] revelam que todos os MLLMs atuais, incluindo o GPT-4o – o modelo mais avançado em nossa avaliação – lutam com o benchmark proposto. Apesar do desempenho superior do GPT-4o em relação a outros modelos, ele não consegue demonstrar consistentemente um raciocínio temporal preciso em diferentes configurações.
‘Os escores de precisão consistentemente baixos para todos os modelos indicam limitações significativas em sua capacidade de compreender e interpretar sequências temporais a partir de entradas visuais. Essas deficiências são evidentes mesmo quando os modelos são fornecidos com entradas de múltiplas imagens ou prompts otimizados, sugerindo que as arquiteturas e metodologias de treinamento atuais são insuficientes para uma compreensão robusta da ordem temporal.’
Sistemas de aprendizado de máquina são projetados para otimizar resultados que sejam não apenas os mais precisos, mas também os mais eficientes e agradáveis para as pessoas*. Uma vez que não revelam seu raciocínio explicitamente, pode ser difícil dizer quando estão “trapaceando” ou usando “atalhos”.
Nesse caso, o MLLM pode chegar à resposta certa pelo método errado. O fato de que tal resposta pode ser correta pode inspirar falsa confiança no modelo, que poderia produzir resultados incorretos pelo mesmo método em tarefas posteriores apresentadas a ele.
Pior ainda, essa desorientação pode se tornar ainda mais profundamente embutida na cadeia de desenvolvimento se os humanos ficarem impressionados com isso e fornecerem feedback positivo em testes e sessões de anotação, o que pode contribuir para a direção que os dados e/ou o modelo podem seguir.
Neste caso, a sugestão é que os MLLMs estão “fingindo” uma verdadeira compreensão da cronologia e fenômenos temporais, observando e ancorando em indicadores secundários (como carimbos de data e hora, por exemplo, em dados de vídeo, ordem das imagens em um layout ou mesmo – potencialmente – nomes de arquivos numerados sequencialmente).
Além disso, indica que os MLLMs atualmente falham em satisfazer qualquer definição real de ter uma generalização de um conceito de fenômenos temporais – pelo menos, na medida em que os humanos conseguem.
O novo artigo é intitulado Os MLLMs Multimodais conseguem fazer Compreensão e Raciocínio Visual Temporal? A resposta é Não!, e é produzido por três pesquisadores da Universidade Mohamed bin Zayed de Inteligência Artificial e Alibaba International Digital Commerce.
Dados e Testes
Os autores observam que benchmarks e estudos anteriores, como MMMU e TemporalBench, se concentram em entradas de imagem única ou formulam perguntas para os MLLMs que podem ser um tanto fáceis de responder, e podem não descobrir uma tendência em direção ao comportamento de atalho.
Portanto, os autores oferecem duas abordagens atualizadas: Compreensão da Ordem Temporal (TOU) e Estimativa do Intervalo de Tempo(TLE). A abordagem TOU testa os modelos em sua capacidade de determinar a sequência correta de eventos a partir de pares de quadros de vídeo; o método TLE avalia a capacidade do MLLM de estimar a diferença de tempo entre duas imagens, variando de segundos a anos.
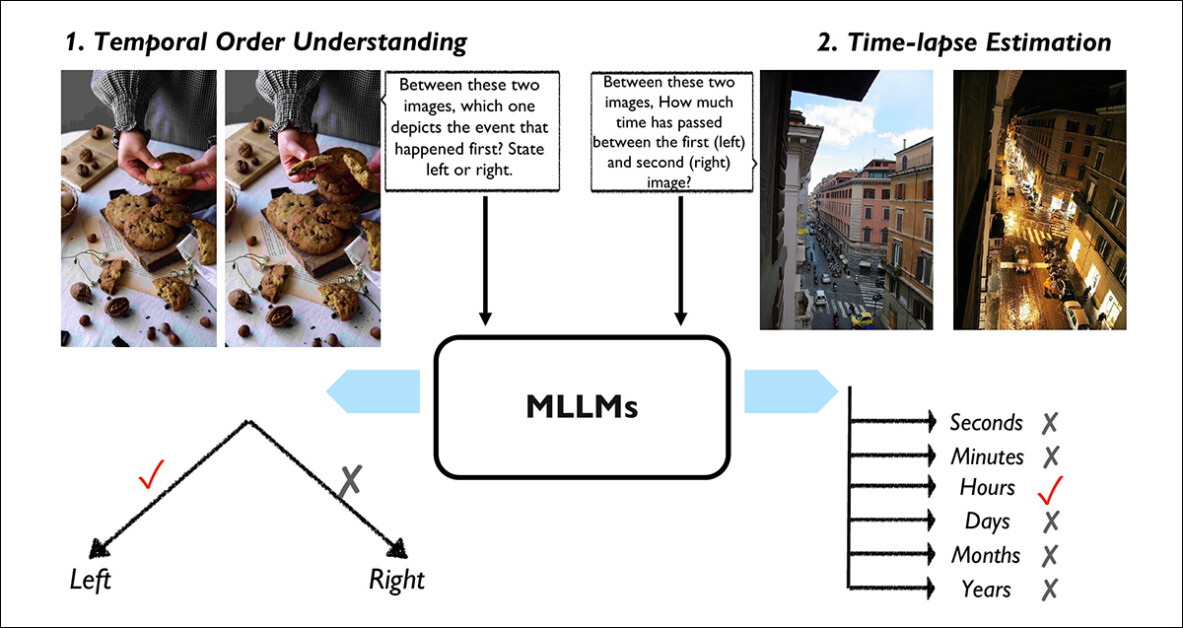
Do artigo, as duas principais tarefas do benchmark TemporalVQA: na Compreensão da Ordem Temporal, o modelo decide qual das duas imagens mostra um evento que ocorreu primeiro; na Estimativa do Intervalo de Tempo, o modelo estima quanto tempo se passou entre duas imagens, selecionando entre opções que incluem segundos, minutos, dias ou anos. Essas tarefas visam testar quão bem os MLLMs podem raciocinar sobre o tempo e a sequência de eventos visuais. Fonte: https://arxiv.org/pdf/2501.10674
Os pesquisadores selecionaram 360 pares de imagens para o benchmark TOU, utilizando vídeos de código aberto do Pixabay e Pexels, para que fosse possível tornar o conjunto de dados disponível através de uma GUI.
Os vídeos cobriram uma gama de tópicos, desde pessoas em atividades cotidianas até conteúdos não humanos, como animais e plantas. A partir disso, pares de quadros foram selecionados para retratar uma sequência de eventos com variação suficiente para tornar o quadro inicial ‘óbvio’.
A seleção humana foi utilizada para garantir que os quadros pudessem ser ordenados de forma definitiva. Por exemplo, um dos pares selecionados mostra uma caneca parcialmente cheia em um quadro e a mesma caneca completamente cheia de chá no próximo, tornando a lógica da sequência fácil de identificar.

A lógica temporal dessas duas imagens não pode ser ignorada, uma vez que o chá não pode ser sugado de volta pela boca.
Dessa forma, foram obtidos 360 pares de imagens.
Para a abordagem TLE, imagens livres de direitos autorais foram escolhidas no Google e Flickr, além de quadros selecionados de vídeos isentos de direitos autorais no YouTube. O assunto desses vídeos apresentava cenas ou objetos cujo intervalo de mudança variava de segundos a dias e estações – por exemplo, frutas amadurecendo ou a mudança das estações em paisagens.
Assim, 125 pares de imagens foram selecionados para o método TLE.
Nem todos os MLLMs testados conseguiram processar várias imagens; portanto, os testes diferiram para acomodar as capacidades de cada modelo.
Múltiplas versões dos conjuntos de dados selecionados foram geradas, nas quais alguns dos pares foram concatenados verticalmente, e outros horizontalmente. Outras variações trocaram a sequência temporal correta dos pares.
Dois tipos de prompts foram desenvolvidos. O primeiro seguiu este modelo:
O evento na (esquerda / topo / primeiro) imagem aconteceu antes do evento na (direita / baixo / segundo) imagem? Declare verdadeiro ou falso com raciocínio.
O segundo seguiu este esquema:
Entre essas duas imagens, qual delas retrata o evento que aconteceu primeiro? Declare (esquerda ou direita / topo ou baixo / primeiro ou segundo) com raciocínio.
Para TLE, as questões foram de múltipla escolha, pedindo aos modelos para avaliar o intervalo entre as duas imagens apresentadas, com segundos, horas, minutos, dias, meses e anos como as unidades de tempo. Nesta configuração, a imagem mais recente foi apresentada à direita.
O prompt usado aqui foi:
Na imagem fornecida, estime o tempo que se passou entre a primeira imagem (esquerda) e a segunda imagem (direita).
Escolha uma das seguintes opções:
-
Menos de 15 segundos
B. Entre 2 minutos e 15 minutos
C. Entre 1 hora e 12 horas
D. Entre 2 dias e 30 dias
E. Entre 4 meses e 12 meses
F. Mais de 3 anos
Os MLLMs testados foram ChatGPT-4o; Gemini1.5-Pro; LlaVa-NeXT; InternVL; Qwen-VL; Llama-3-vision; e LLaVA-CoT.
Compreensão da Ordem Temporal: Resultados
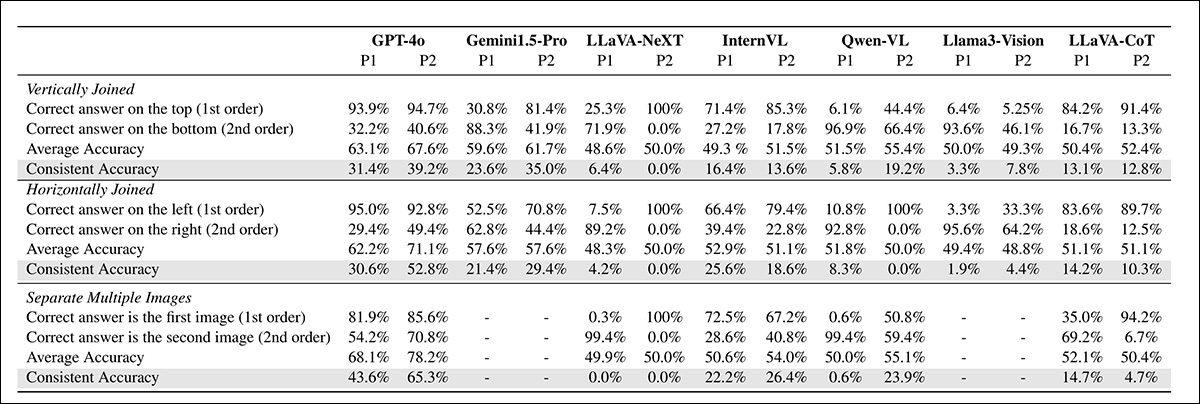
Resultados da Compreensão da Ordem Temporal entre diferentes modelos e layouts de entrada, mostrando precisão e consistência para várias configurações e prompts.
Quanto aos resultados mostrados acima, os autores descobriram que todos os MLLMs testados, incluindo o GPT-4o (que apresentou o melhor desempenho geral), tiveram dificuldades significativas com o benchmark TemporalVQA – e mesmo o GPT-4o não conseguiu exibir consistentemente um raciocínio temporal confiável em diferentes configurações.
Os autores sustentam que a precisão consistentemente baixa entre os LLMs destaca questões significativas na capacidade dos modelos de interpretar e raciocinar sobre sequências temporais a partir de dados visuais. Os pesquisadores notam que esses desafios persistem mesmo com a utilização de entradas de múltiplas imagens e prompts otimizados, apontando para limitações fundamentais nas arquiteturas e métodos de treinamento atuais.
Os testes mostraram variações significativas no desempenho entre as estratégias de prompting. Embora o GPT-4o tenha melhorado com prompts otimizados (alcançando 4% em configurações de imagem única e 65,3% em configurações de múltiplas imagens), o desempenho permaneceu abaixo de níveis aceitáveis.
Modelos como LLaVA-NeXT e Qwen-VL eram ainda mais sensíveis, com o desempenho diminuindo quando prompts alternativos eram utilizados, sugerindo que a engenharia de prompts sozinha não pode superar as limitações fundamentais dos MLLMs em relação ao raciocínio temporal.
Os testes também indicaram que o layout da imagem (ou seja, vertical versus horizontal) impactou significativamente o desempenho do modelo. O GPT-4o melhorou sua consistência com arranjos verticais, subindo de 39,2% para 52,8%; no entanto, outros modelos, incluindo as variantes LLaVA, mostraram fortes vieses direcionais, excelendo em uma orientação, mas falhando em outra.
O artigo indica que essas inconsistências sugerem uma dependência de pistas espaciais, em vez de um verdadeiro raciocínio temporal, com os MLLMs não analisando genuinamente a sequência de eventos ou entendendo a progressão ao longo do tempo. Em vez disso, eles parecem ter dependido de padrões ou características visuais relacionadas ao layout das imagens, como sua posição ou alinhamento, para tomar decisões.

Testes qualitativos destacam as previsões do GPT-4o quando enfrentam diferentes ordens de entrada. Na primeira ordem, os pares de imagens são apresentados em sua sequência original, enquanto na segunda ordem, a sequência é invertida. Classificações corretas são marcadas em verde, classificações puras em vermelho, raciocínio alucinado em laranja e raciocínio ilógico ou ‘inválido’ em marrom, revelando as inconsistências do modelo em diferentes configurações de entrada.
Testes comparativos entre entradas de imagem única e múltipla demonstraram melhorias limitadas no desempenho geral, com o GPT-4o apresentando desempenho ligeiramente melhor em múltiplas imagens, subindo de 31,0% para 43,6% (com P1) e de 46,0% para 65,3% (com P2).
Outros modelos, como InternVL, mostraram precisão estável, mas baixa, enquanto o Qwen-VL teve ganhos menores. Os autores concluem que esses resultados indicam que o contexto visual adicional não melhora substancialmente as capacidades de raciocínio temporal, pois os modelos lutam para integrar informações temporais de forma eficaz.
Estudo Humano
Em um estudo humano, três pesquisas foram conduzidas para avaliar quão próximo o melhor MLLM de multimodalidade se aproximou da estimativa humana.
Os humanos alcançaram 90,3% de precisão, superando os 65,3% do GPT-4o por 25%. O conjunto de dados provou ser confiável, com erros humanos mínimos e consistente concordância nas respostas corretas.

Resultados do estudo com usuários humanos para a primeira rodada de testes.
Estimativa do Intervalo de Tempo: Resultados
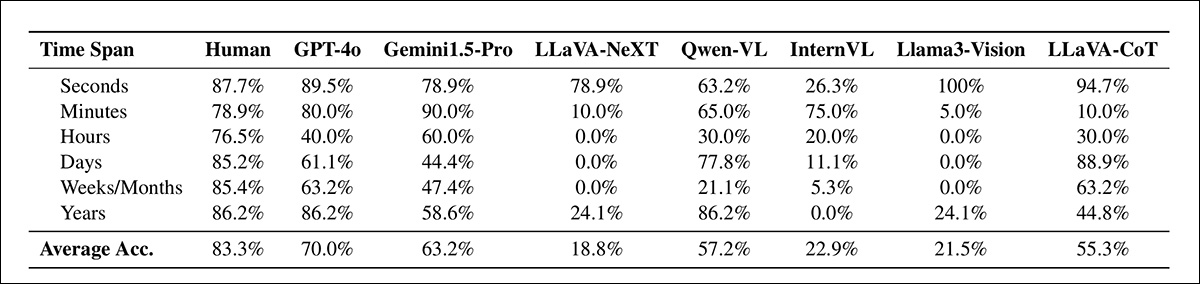
Resultados para TLE: a estimativa do intervalo de tempo avalia a precisão do modelo em identificar intervalos entre pares de imagens, em escalas que variam de segundos a anos. A tarefa avalia a capacidade de cada modelo de selecionar a escala de tempo correta para a lacuna temporal.
Nesses testes, os MLLMs tiveram um desempenho apenas adequado na estimativa do intervalo de tempo: o GPT-4o alcançou 70% de precisão, mas os outros modelos tiveram um desempenho significativamente pior (veja a tabela acima), e o desempenho também variou notavelmente nas várias escalas de tempo.
Os autores comentam:
‘A tarefa de estimativa do intervalo de tempo testa a capacidade dos MLLMs de inferir intervalos temporais entre pares de imagens. [Todos] os MLLMs, incluindo os melhores desempenhadores como GPT-4o e Gemini1.5-Pro, lutam com essa tarefa, alcançando apenas níveis de precisão moderados de 60-70%. O GPT-4o demonstra desempenho inconsistente, com bom desempenho em segundos e anos, mas desempenho abaixo do esperado em horas.
De forma semelhante, o LLaVA-CoT demonstra desempenho excepcional nos intervalos de segundos e dias, enquanto apresenta desempenho notavelmente pobre nos outros intervalos de tempo.’
Estudo Humano
No estudo humano para TLE, o desempenho médio humano melhorou em relação ao GPT-4o (o modelo com melhor desempenho também nesta categoria) em 12,3%.
Os autores observam que alguns dos desafios foram particularmente exigentes, e que em um caso todos os participantes humanos retornaram uma resposta errada, junto com todos os participantes de IA.
Os autores concluem que o GPT-4o exibe ‘capacidades de raciocínio razoavelmente robustas, independentemente da ordem das imagens apresentadas a ele.
Conclusão
Se os MLLMs eventualmente acumularem e absorverem dados “de atalho” suficientes para cobrir até mesmo os desafios mais complicados do tipo apresentado pelos autores neste estudo, a questão de saber se conseguirão desenvolver capacidades de generalização em estilo humano neste domínio pode se tornar um ponto discutível.
Também não se sabe exatamente qual caminho seguimos para obter nossas próprias habilidades em raciocínio temporal – será que também “trapaceamos” até que a pura quantidade de experiência aprendida revele um padrão que atua como um “instinto” em relação a este tipo de teste?
* Do ponto de vista de que os modelos estão sendo cada vez mais otimizados com funções de perda que o feedback humano ajudou a contribuir, e efetivamente otimizados por testes humanos e subsequente triagem.
Publicada pela primeira vez na segunda-feira, 27 de janeiro de 2025

Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…