


Uma nova colaboração de pesquisa entre Israel e Japão afirma que os sistemas de detecção de pedestres têm fraquezas inerentes, permitindo que indivíduos bem-informados evitem sistemas de reconhecimento facial ao navegar por rotas cuidadosamente planejadas em áreas onde as redes de vigilância são menos eficazes.
Com a ajuda de imagens públicas de Tóquio, Nova Iorque e São Francisco, os pesquisadores desenvolveram um método automatizado para calcular tais rotas, com base nos sistemas de reconhecimento de objetos mais populares que provavelmente estão em uso nas redes públicas.

As três travessias utilizadas no estudo: Shibuya Crossing em Tóquio, Japão; Broadway, Nova Iorque; e Castro District, São Francisco. Fonte: https://arxiv.org/pdf/2501.15653
Por este método, é possível gerar mapas de calor de confiança que demarcam áreas dentro do feed da câmera onde é menos provável que os pedestres forneçam uma identificação positiva de reconhecimento facial:

À direita, vemos o mapa de calor de confiança gerado pelo método dos pesquisadores. As áreas vermelhas indicam baixa confiança e uma configuração de postura, ângulo da câmera e outros fatores que provavelmente dificultam o reconhecimento facial.
Teoricamente, tal método poderia ser instrumentalizado em um aplicativo baseado em localização, ou algum outro tipo de plataforma para disseminar os caminhos menos ‘amigáveis ao reconhecimento’ de A a B em qualquer local calculado.
O novo artigo propõe tal metodologia, intitulada Técnica de Melhoria de Privacidade Baseada em Localização (L-PET); também propõe uma contramedida intitulada Limite Adaptativo Baseado em Localização (L-BAT), que essencialmente executa exatamente as mesmas rotinas, mas utiliza as informações para reforçar e melhorar as medidas de vigilância, em vez de criar maneiras de evitar o reconhecimento; e em muitos casos, tais melhorias não seriam possíveis sem um investimento adicional na infraestrutura de vigilância.
Portanto, o artigo estabelece uma potencial guerra tecnológica de escalonamento entre aqueles que buscam otimizar suas rotas para evitar a detecção e a capacidade dos sistemas de vigilância de fazer pleno uso das tecnologias de reconhecimento facial.
Métodos anteriores de frustrar a detecção são menos elegantes do que este e se concentram em abordagens adversariais, como TnT Attacks, e o uso de padrões impressos para confundir o algoritmo de detecção.

O trabalho de 2019 ‘Fooling automated surveillance cameras: adversarial patches to attack person detection’ demonstrou um padrão impresso adversarial capaz de convencer um sistema de reconhecimento de que nenhuma pessoa é detectada, permitindo uma espécie de ‘invisibilidade. Fonte: https://arxiv.org/pdf/1904.08653
Os pesquisadores por trás do novo artigo observam que sua abordagem requer menos preparação, sem necessidade de criar itens vestíveis adversariais (veja a imagem acima).
O artigo tem o título Uma Técnica de Melhoria de Privacidade para Evitar Detecção por Câmeras de Vídeo de Rua sem Usar Acessórios Adversariais, e é fruto da colaboração de cinco pesquisadores da Universidade Ben-Gurion do Negev e da Fujitsu Limited.
Método e Testes
De acordo com trabalhos anteriores, como Adversarial Mask, AdvHat, patches adversariais, e várias outras pesquisas semelhantes, os pesquisadores assumem que o ‘atacante’ pedestre sabe qual sistema de detecção de objetos está sendo usado na rede de vigilância. Esta é de fato uma suposição razoável, devido à ampla adoção de sistemas de código aberto de última geração como o YOLO em sistemas de vigilância de empresas como a Cisco e a Ultralytics (atualmente a força central no desenvolvimento do YOLO).
O artigo também assume que o pedestre tem acesso a um stream ao vivo na internet fixado nas localizações a serem calculadas, o que, novamente, é uma suposição razoável na maioria dos lugares que provavelmente tenham uma intensidade de cobertura.
Sites como 511ny.org oferecem acesso a muitas câmeras de vigilância na área de NYC. Fonte: https://511ny.or
Além disso, o pedestre precisa de acesso ao método proposto e ao próprio cenário (ou seja, as travessias e as rotas em que uma rota ‘segura’ deve ser estabelecida).
Para desenvolver o L-PET, os autores avaliaram o efeito do ângulo do pedestre em relação à câmera; o efeito da altura da câmera; o efeito da distância; e o efeito do horário do dia. Para obter a verdade de campo, eles fotografaram uma pessoa em ângulos de 0°, 45°, 90°, 135°, 180°, 225°, 270° e 315°.

Observações da verdade de campo realizadas pelos pesquisadores.
Eles repetiram essas variações em três alturas de câmera diferentes (0,6m, 1,8m, 2,4m) e em variadas condições de iluminação (manhã, tarde, noite e condições de ‘laboratório’).
Alimentando essas filmagens para os detectores de objetos Faster R-CNN e YOLOv3, eles descobriram que a confiança do objeto depende da agudeza do ângulo do pedestre, da distância do pedestre, da altura da câmera e das condições climáticas/iluminação*.
Os autores então testaram uma gama mais ampla de detectores de objetos no mesmo cenário: Faster R-CNN; YOLOv3; SSD; DiffusionDet; e RTMDet.
Os autores afirmam:
‘Descobrimos que todas as cinco arquiteturas de detecção de objetos são afetadas pela posição do pedestre e pela luz ambiente. Além disso, descobrimos que para três dos cinco modelos (YOLOv3, SSD e RTMDet), o efeito persiste através de todos os níveis de luz ambiente.’
Para ampliar o escopo, os pesquisadores utilizaram filmagens retiradas de câmeras de tráfego públicas em três locais: Shibuya Crossing em Tóquio, Broadway em Nova Iorque e Castro District em São Francisco.
Cada local forneceu entre cinco e seis gravações, com aproximadamente quatro horas de filmagem por gravação. Para analisar o desempenho da detecção, um quadro foi extraído a cada dois segundos e processado usando um detector de objetos Faster R-CNN. Para cada pixel nos quadros obtidos, o método estimou a média da confiança das caixas delimitadoras de detecção de ‘pessoa’ presentes naquele pixel.
‘Descobrimos que em todos os três locais, a confiança do detector de objetos variou dependendo da localização das pessoas no quadro. Por exemplo, nas filmagens de Shibuya Crossing, existem grandes áreas de baixa confiança mais longe da câmera, assim como mais perto da câmera, onde um poste obstrui parcialmente os pedestres que passam.’
O método L-PET é essencialmente esse procedimento, talvez ‘armazenado’ para obter um caminho através de uma área urbana que é menos provável que resulte no reconhecimento bem-sucedido do pedestre.
Em contraste, o L-BAT segue o mesmo procedimento, com a diferença de que atualiza as pontuações no sistema de detecção, criando um ciclo de feedback projetado para evitar a abordagem L-PET e tornar as ‘áreas cegas’ do sistema mais eficazes.
(Em termos práticos, no entanto, melhorar a cobertura com base nos mapas de calor obtidos exigiria mais do que apenas uma atualização da câmera na posição esperada; com base nos critérios de teste, incluindo localização, exigiria a instalação de câmeras adicionais para cobrir as áreas negligenciadas – portanto, poderia-se argumentar que o método L-PET eleva essa ‘guerra fria’ em um cenário muito caro de fato).
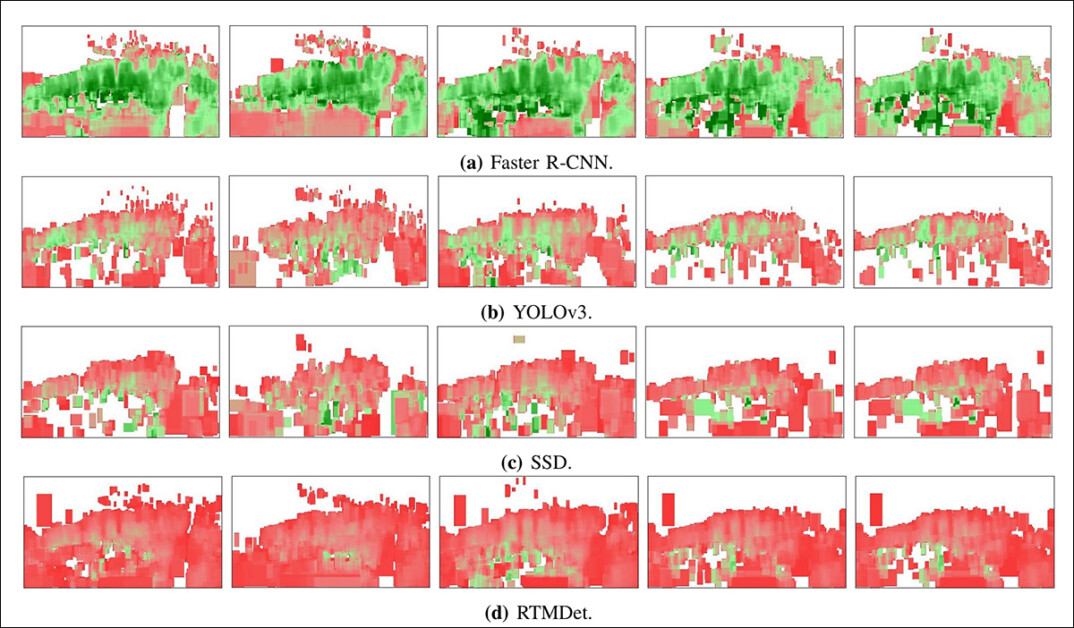
A confiança média da detecção de pedestres para cada pixel, em diversas estruturas de detectores, na área observada da Castro Street, analisada em cinco vídeos. Cada vídeo foi gravado sob diferentes condições de iluminação: nascer do sol, durante o dia, pôr do sol e duas configurações noturnas distintas. Os resultados são apresentados separadamente para cada cenário de iluminação.
Tendo convertido a representação matricial baseada em pixels em uma representação gráfica adequada para a tarefa, os pesquisadores adaptaram o algoritmo de Dijkstra para calcular caminhos ideais para que os pedestres naveguem por áreas com detecção reduzida de vigilância.
Em vez de encontrar o caminho mais curto, o algoritmo foi modificado para minimizar a confiança na detecção, tratando regiões de alta confiança como áreas de maior ‘custo’. Essa adaptação permitiu que o algoritmo identificasse rotas que passavam por pontos cegos ou zonas de baixa detecção, orientando efetivamente os pedestres ao longo de caminhos com menor visibilidade para os sistemas de vigilância.
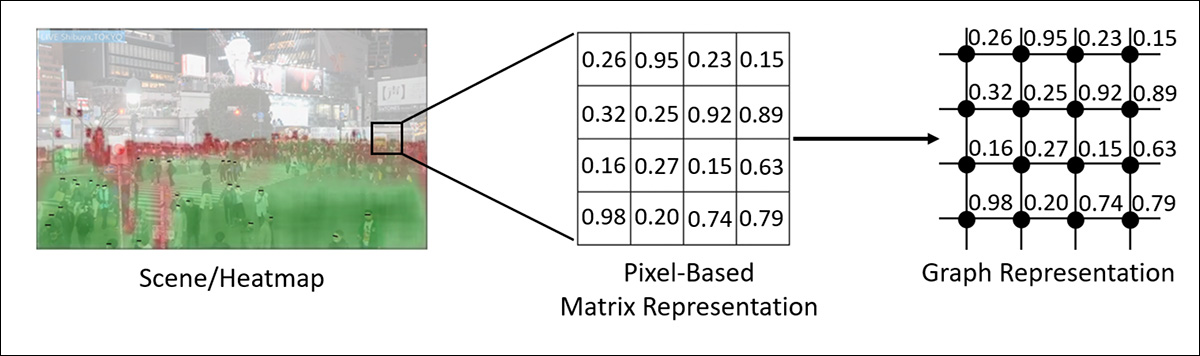
Uma visualização que representa a transformação do mapa de calor da cena de uma matriz baseada em pixels para uma representação gráfica.
Os pesquisadores avaliaram o impacto do sistema L-BAT na detecção de pedestres com um conjunto de dados construído a partir das gravações de quatro horas do tráfego pedonal público mencionado. Para compor a coleção, um quadro foi processado a cada dois segundos utilizando um detector de objetos SSD.
De cada quadro, uma caixa delimitadora foi selecionada contendo uma pessoa detectada como amostra positiva, e outra área aleatória sem pessoas detectadas foi utilizada como amostra negativa. Essas amostras gêmeas formaram um conjunto de dados para a avaliação de dois modelos do Faster R-CNN – um com o L-BAT aplicado e outro sem.
O desempenho dos modelos foi avaliado verificando quão precisamente identificaram as amostras positivas e negativas: uma caixa delimitadora sobrepondo uma amostra positiva foi considerada um verdadeiro positivo, enquanto uma caixa delimitadora sobrepondo uma amostra negativa foi rotulada como falso positivo.
Os métricas usadas para determinar a confiabilidade da detecção do L-BAT foram Área Sob a Curva (AUC); taxa de verdadeiro positivo (TPR); taxa de falso positivo (FPR); e a média da confiança do verdadeiro positivo. Os pesquisadores afirmam que o uso do L-BAT melhorou a confiança da detecção enquanto mantinha uma alta taxa de verdadeiros positivos (embora com um leve aumento nos falsos positivos).
Por fim, os autores observam que a abordagem possui algumas limitações. Uma delas é que os mapas de calor gerados pelo método são específicos para um determinado horário do dia. Embora não tenham se aprofundado nisso, isso indicaria que uma abordagem maior e em múltiplas camadas seria necessária para levar em conta o horário do dia em uma implementação mais flexível.
Eles também observam que os mapas de calor não se transferem para diferentes arquiteturas de modelos e estão vinculados a um modelo específico de detector de objetos. Como o trabalho proposto é essencialmente uma prova de conceito, arquiteturas mais sutis poderiam, presumivelmente, também ser desenvolvidas para remediar essa dívida técnica.
Conclusão
Qualquer novo método de ataque para o qual a solução seja ‘pagar por novas câmeras de vigilância’ tem alguma vantagem, uma vez que expandir redes de câmeras civis em áreas altamente vigiadas pode ser politicamente desafiador, assim como representar uma despesa cívica notável que geralmente exigirá um mandato dos votantes.
Talvez a maior questão levantada pelo trabalho seja ‘Sistemas de vigilância de código fechado utilizam frameworks de código aberto SOTA, como o YOLO?’. Isso, claro, é impossível de saber, já que os fabricantes dos sistemas proprietários que alimentam muitas redes de câmeras estatais e cívicas (pelo menos nos EUA) argumentariam que divulgar tal uso poderia expô-los a ataques.
No entanto, a migração da TI do governo e de códigos proprietários internos para códigos globais e de código aberto sugeriria que qualquer um que teste a afirmação dos autores com (por exemplo) YOLO poderia bem acertar na loteria imediatamente.
* Normalmente, eu incluiria resultados de tabelas relacionadas quando fornecidos no artigo, mas neste caso a complexidade das tabelas do artigo torna-as pouco iluminadoras para o leitor casual, e portanto um resumo é mais útil.
Primeira publicação na terça-feira, 28 de janeiro de 2025

Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…