


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre cobertura de IA de liderança no setor. Saiba mais
A corrida de modelos de código aberto continua a ficar mais interessante.
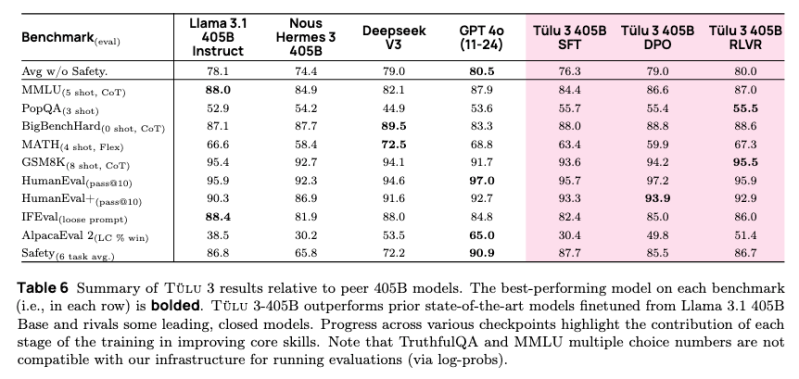
Hoje, o Instituto Allen para IA (Ai2) lançou sua mais recente entrada na corrida com o lançamento de seu modelo de linguagem de grande escala (LLM) Tülu 3, com 405 bilhões de parâmetros. O novo modelo não só iguala as capacidades do GPT-4o da OpenAI, como também supera o modelo v3 da DeepSeek em benchmarks críticos.
Esta não é a primeira vez que o Ai2 faz alegações audaciosas sobre um novo modelo. Em novembro de 2024, a empresa lançou sua primeira versão do Tülu 3, que tinha versões de 8 e 70 bilhões de parâmetros. Na época, o Ai2 afirmou que o modelo estava à altura do mais recente modelo GPT-4 da OpenAI, Claude da Anthropic e Gemini do Google. A grande diferença é que o Tülu 3 é de código aberto. O Ai2 também alegou, em setembro de 2024, que seus modelos Molmo conseguiram superar o GPT-4o e Claude em alguns benchmarks.
Embora os dados de desempenho de benchmarks sejam interessantes, o que é talvez mais útil são as inovações de treinamento que possibilitam o novo modelo do Ai2.
Levando o pós-treinamento ao limite
A grande inovação para o Tülu 3 405B está enraizada em uma inovação que apareceu pela primeira vez com o lançamento inicial do Tülu 3 em 2024. Essa versão utilizou uma combinação de técnicas avançadas de pós-treinamento para obter um melhor desempenho.
Com o modelo Tülu 3 405B, essas técnicas de pós-treinamento foram ainda mais aprimoradas, usando uma metodologia avançada de pós-treinamento que combina ajuste fino supervisionado, aprendizado de preferência e uma nova abordagem de aprendizado por reforço que se mostrou excepcional em escalas maiores.
“Aplicar as receitas de pós-treinamento do Tülu 3 no Tülu 3-405B, nosso modelo pós-treinado totalmente em código aberto em maior escala até hoje, nivela o campo de jogo ao fornecer receitas de ajuste fino abertas, dados e código, permitindo que desenvolvedores e pesquisadores alcancem um desempenho comparável aos melhores modelos fechados”, disse Hannaneh Hajishirzi, diretora sênior de Pesquisa em NLP no Ai2, ao VentureBeat.
Avançando o estado da IA de código aberto pós-treinamento com RLVR
O pós-treinamento é algo que outros modelos, incluindo o DeepSeek v3, também fazem.
A inovação chave que ajuda a diferenciar o Tülu 3 é o sistema de “aprendizado por reforço a partir de recompensas verificáveis” (RLVR) do Ai2.
Diversamente das abordagens de treinamento tradicionais, o RLVR utiliza resultados verificáveis — como resolver problemas matemáticos corretamente — para ajustar o desempenho do modelo. Essa técnica, quando combinada com a otimização direta de preferência (DPO) e um conjunto de dados de treinamento cuidadosamente selecionado, permitiu que o modelo alcançasse uma melhor precisão em tarefas de raciocínio complexo, mantendo características de segurança robustas.
Inovações técnicas chave na implementação do RLVR incluem:
- Processamento paralelo eficiente em 256 GPUs
- Sincronização de pesos otimizada
- Distribuição de computação balanceada em 32 nós
- Implantação integrada de vLLM com paralelismo de tensor 16-way
O sistema RLVR mostrou resultados aprimorados na escala de 405 bilhões de parâmetros em comparação com modelos menores. O sistema também demonstrou resultados particularmente robustos em avaliações de segurança, superando o DeepSeek V3, Llama 3.1 e Nous Hermes 3. Notavelmente, a eficácia do framework RLVR aumentou com o tamanho do modelo, sugerindo potenciais benefícios de implementações ainda maiores.
Como o Tülu 3 405B se compara ao GPT-4o e ao DeepSeek v3
A posição competitiva do modelo é particularmente notável no atual cenário de IA.
O Tülu 3 405B não só iguala as capacidades do GPT-4o, mas também supera o DeepSeek v3 em algumas áreas, particularmente em benchmarks de segurança.
Em um conjunto de 10 benchmarks de IA, incluindo benchmarks de segurança, o Ai2 relatou que o modelo RLVR do Tülu 3 405B teve uma pontuação média de 80.7, superando os 75.9 do DeepSeek V3. No entanto, o Tülu não é tão bom quanto o GPT-4o, que obteve 81.6. No geral, as métricas sugerem que o Tülu 3 405B é, no mínimo, extremamente competitivo com o GPT-4o e o DeepSeek v3 em todos os benchmarks.
Por que a IA de código aberto é importante e como o Ai2 está fazendo isso de forma diferente
O que torna o Tülu 3 405B diferente para os usuários é como o Ai2 disponibilizou o modelo.
Há muito barulho no mercado de IA sobre código aberto. A DeepSeek afirma que seu modelo é de código aberto, e o mesmo se aplica ao Llama 3.1 da Meta, que também é superado pelo Tülu 3 405B.
Tanto o DeepSeek quanto o Llama estão disponíveis gratuitamente para uso; e algum código, embora não todo, está disponível.
Por exemplo, a DeepSeek-R1 lançou seu código de modelo e pesos pré-treinados, mas não os dados de treinamento. O Ai2 adota uma abordagem diferente na tentativa de ser mais aberto.
“Nós não utilizamos nenhum conjunto de dados fechados”, disse Hajishirzi. “Como com nosso primeiro lançamento do Tülu 3 em novembro de 2024, estamos liberando todo o código da infraestrutura.”
Ela acrescentou que a abordagem totalmente aberta do Ai2, que inclui dados, código de treinamento e modelos, garante que os usuários possam facilmente personalizar seu pipeline para tudo, desde a seleção de dados até a avaliação. Os usuários podem acessar a suíte completa de modelos Tülu 3, incluindo Tülu 3-405B, na página do Tülu 3, ou testar a funcionalidade do Tülu 3-405B através do espaço de demonstração demonstração.


Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…