


Desde minha cobertura recente sobre o crescimento dos Hunyuan Video LoRAs para hobbyistas (arquivos pequenos e treinados que podem injetar personalidades personalizadas em modelos de fundação de texto para vídeo e imagem para vídeo com bilhões de parâmetros), o número de LoRAs relacionados disponíveis na comunidade Civit aumentou em 185%.
Apesar de não haver maneiras particularmente fáceis ou de baixo esforço para criar um Hunyuan Video LoRA, o catálogo de LoRAs de celebridades e temas na Civit está crescendo diariamente. Fonte: https://civitai.com/
A mesma comunidade que está correndo para aprender a produzir essas ‘personalidades adicionais’ para o Hunyuan Video (HV) está também aguardando ansiosamente o prometido lançamento de uma funcionalidade de imagem para vídeo (I2V) no Hunyuan Video.
Em relação à síntese de imagens humanas de código aberto, isso é um grande negócio; combinado com o crescimento dos Hunyuan LoRAs, pode permitir que os usuários transformem fotos de pessoas em vídeos de uma maneira que não degrade sua identidade à medida que o vídeo se desenvolve – o que atualmente ocorre em todos os geradores de imagem para vídeo de última geração, incluindo Kling, Kaiber e o muito celebrado RunwayML:
Clique para reproduzir. Uma geração de imagem para vídeo do modelo de ponta Gen 3 Turbo da RunwayML. No entanto, assim como todos os modelos rivais parecidos, ele não pode manter uma identidade consistente quando o sujeito se vira para longe da câmera, e as características distintas da imagem inicial se tornam uma ‘mulher de difusão genérica’. Fonte: https://app.runwayml.com/
Ao desenvolver um LoRA personalizado para a personalidade em questão, um poderia, em um fluxo de trabalho HV I2V, usar uma foto real como ponto de partida. Isso é um ‘seed’ muito melhor do que enviar um número aleatório para o espaço latente do modelo e se contentar com o que quer que a situação semântica resulte. Em seguida, poderia usar o LoRA, ou múltiplos LoRAs, para manter a consistência da identidade, penteados, roupas e outros aspectos fundamentais de uma geração.
Potencialmente, a disponibilidade de tal combinação poderia representar uma das mudanças mais significativas em IA generativa desde o lançamento do Stable Diffusion, com um poder generativo formidável transferido para entusiastas de código aberto, sem a regulamentação (ou ‘filtragem’, se preferir) fornecida pelos censores de conteúdo nos sistemas de vídeo generativos populares atuais.
Enquanto escrevo, a funcionalidade de imagem para vídeo do Hunyuan é uma tarefa não marcada no repositório GitHub do Hunyuan Video, com a comunidade de hobbyistas relatando (anecdoticamente) um comentário no Discord de um desenvolvedor do Hunyuan, que aparentemente afirmou que o lançamento dessa funcionalidade foi adiado para algum momento mais tarde no primeiro trimestre devido ao modelo estar ‘muito descensurado’.

A lista oficial de verificação do lançamento de recursos para o Hunyuan Video. Fonte: https://github.com/Tencent/HunyuanVideo?tab=readme-ov-file#-open-source-plan
Precisa ou não, os desenvolvedores do repositório entregaram substancialmente o resto da lista de tarefas do Hunyuan, e, portanto, o I2V do Hunyuan parece prestes a chegar eventualmente, seja censurado, não censurado ou de alguma forma ‘desbloqueável’.
Mas, como podemos ver na lista acima, o lançamento do I2V é aparentemente um modelo completamente separado – o que torna bastante improvável que qualquer um dos atuais e crescentes lotes de HV LoRAs na Civit e em outros locais funcione com ele.
Nessa (por agora) situação previsível, estruturas de treinamento LoRA como Musubi Tuner e OneTrainer serão reavaliadas ou redefinidas em relação ao suporte para o novo modelo. Enquanto isso, uma ou duas das figuras mais experientes em tecnologia (e empreendedoras) do YouTube sobre IA irão oferecer suas soluções via Patreon até que a cena se desenvolva.
Cansaço com as Atualizações
Uma vez que esses modelos novos e melhorados terão, no mínimo, diferentes viés e pesos, e mais comumente terão uma escala e/ou arquitetura diferente, isso significa que a comunidade de fine-tuning terá que retirar seus conjuntos de dados novamente e repetir o árduo processo de treinamento para a nova versão.
Por essa razão, uma multiplicidade de tipos de versões de LoRA de Stable Diffusion estão disponíveis na Civit:
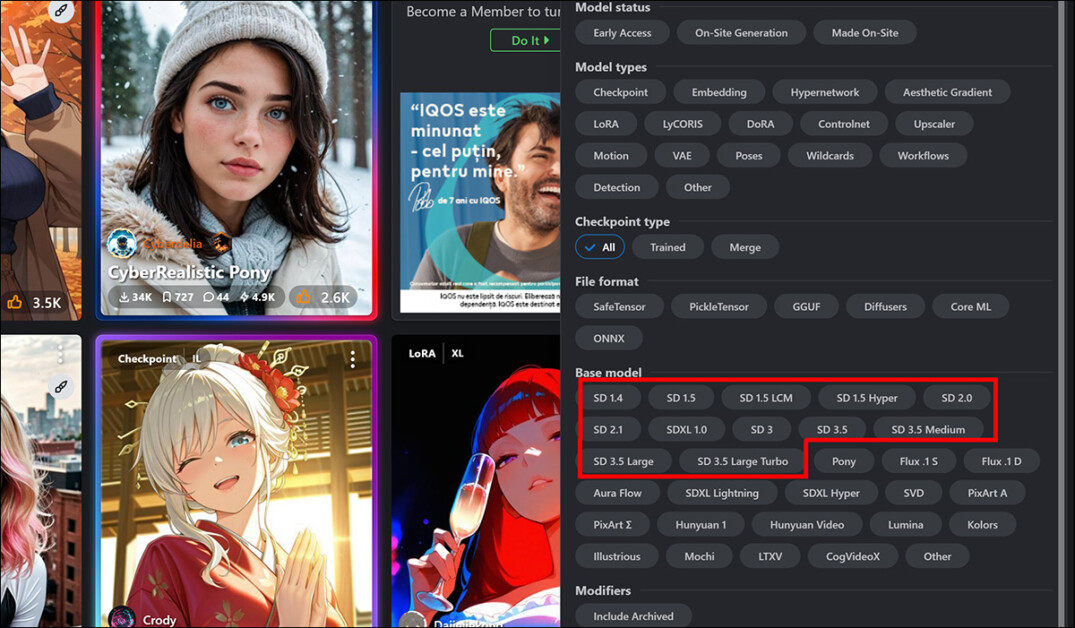
A trilha das atualizações, visualizada nas opções de filtro de pesquisa em civit.ai
Como nenhum desses modelos leves de LoRA são interoperáveis com versões de modelos superiores ou inferiores, e como muitos deles têm dependências de combinações e fine-tunes de grande escala populares que se enquadram em um modelo mais antigo, uma parte significativa da comunidade tende a ficar com uma versão ‘legada’, da mesma forma que a lealdade dos clientes ao Windows XP persistiu anos após o término do suporte oficial.
Adaptando-se à Mudança
Este assunto vem à mente por causa de um novo artigo da Qualcomm AI Research que afirma ter desenvolvido um método pelo qual os LoRAs existentes podem ser ‘atualizados’ para uma nova versão do modelo liberado.
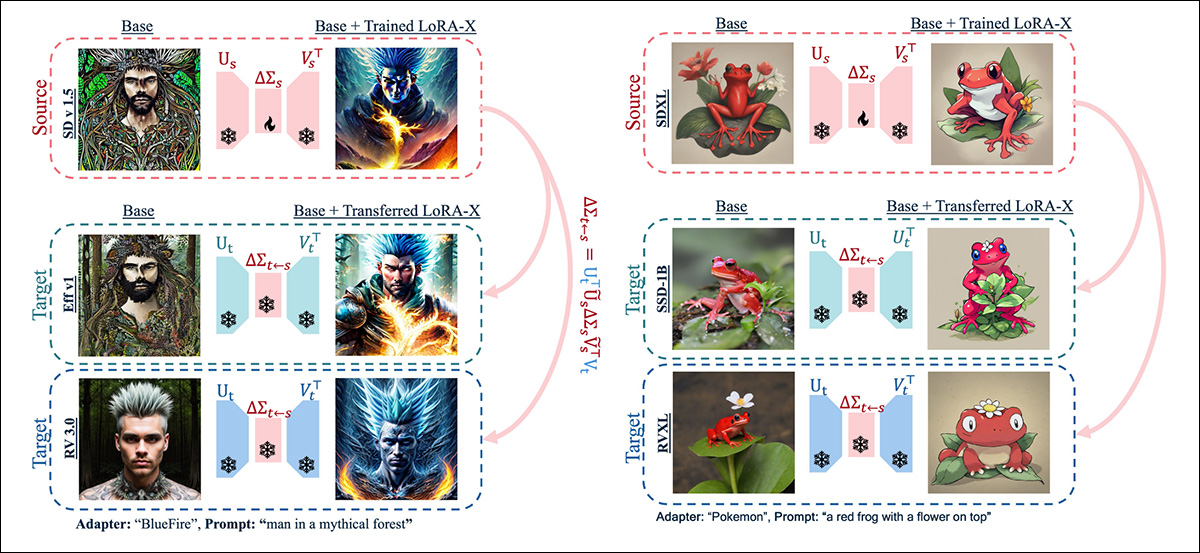
Exemplo de conversão de LoRAs entre versões de modelos. Fonte: https://arxiv.org/pdf/2501.16559
Isso não significa que a nova abordagem, intitulada LoRA-X, pode traduzir livremente entre todos os modelos do mesmo tipo (ou seja, modelos de texto para imagem ou Modelos de Linguagem Grande [LLMs]); mas os autores demonstraram uma transliteração eficaz de um LoRA do Stable Diffusion v1.5 para SDXL, e uma conversão de um LoRA para o modelo TinyLlama 3T baseado em texto para TinyLlama 2.5T.
O LoRA-X transfere parâmetros de LoRA entre diferentes modelos base, preservando o adaptador dentro do subespaço do modelo de origem; mas apenas em partes do modelo que são adequadamente semelhantes entre as versões do modelo.
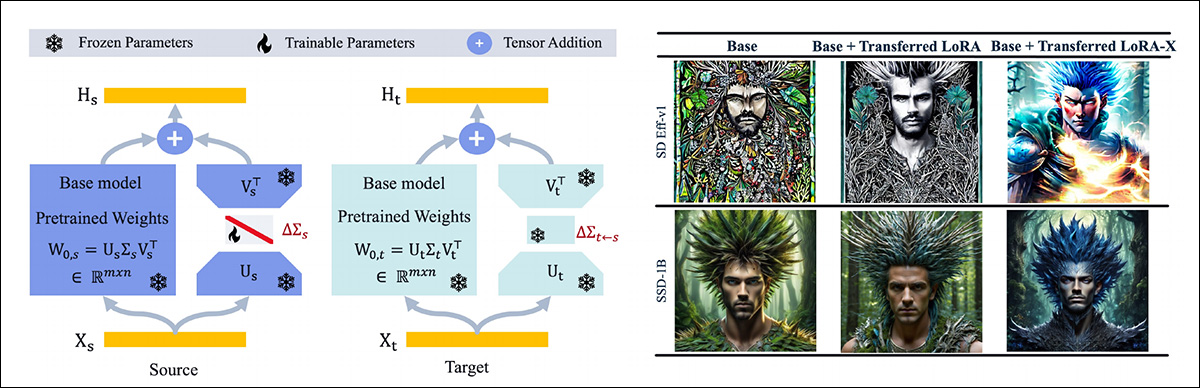
À esquerda, um esquema de como o modelo fonte LoRA-X ajusta um adaptador, que é então ajustado para se adequar ao modelo de destino. À direita, imagens geradas pelos modelos de destino SD Eff-v1.0 e SSD-1B, após a aplicação de adaptadores transferidos de SD-v1.5 e SDXL sem treinamento adicional.
Enquanto isso oferece uma solução prática para cenários onde o re-treinamento é indesejável ou impossível (como uma mudança de licença nos dados de treinamento originais), o método é restrito a arquiteturas de modelo semelhantes, entre outras limitações.
Embora essa seja uma incursão rara em um campo pouco estudado, não examinaremos este artigo em profundidade devido às inúmeras deficiências do LoRA-X, evidenciadas pelos comentários de seus críticos e conselheiros na Open Review.
A dependência do método de similaridade de subespaço restringe sua aplicação a modelos intimamente relacionados, e os autores concederam no fórum de revisão que o LoRA-X não pode ser facilmente transferido entre arquiteturas significativamente diferentes.
Outras Abordagens de PEFT
A possibilidade de tornar os LoRAs mais portáteis entre versões é um pequeno, mas interessante, fio de estudo na literatura, e a principal contribuição que o LoRA-X faz a essa busca é a sua afirmação de que não requer treinamento. Isso não é estritamente verdade, se ler o artigo, mas ele requer o menor treinamento de todos os métodos anteriores.
O LoRA-X é outra entrada no cânone de Aprimoramento Eficiente de Parâmetros (PEFT), que aborda o desafio de adaptar grandes modelos pré-treinados a tarefas específicas sem re-treinamento extensivo. Essa abordagem conceitual visa modificar um número mínimo de parâmetros enquanto mantém o desempenho.
Notáveis entre eles estão:
X-Adapter
O framework X-Adapter transfere adaptadores ajustados entre modelos com uma certa quantidade de re-treinamento. O sistema visa permitir módulos pré-treinados plug-and-play (como ControlNet e LoRA) de um modelo de difusão base (ou seja, Stable Diffusion v1.5) para trabalhar diretamente com um modelo de difusão atualizado, como SDXL, sem re-treinamento – atuando efetivamente como um ‘atualizador universal’ para plugins.
O sistema alcança isso treinando uma rede adicional que controla o modelo atualizado, usando uma cópia congelada do modelo base para preservar os conectores de plugin:
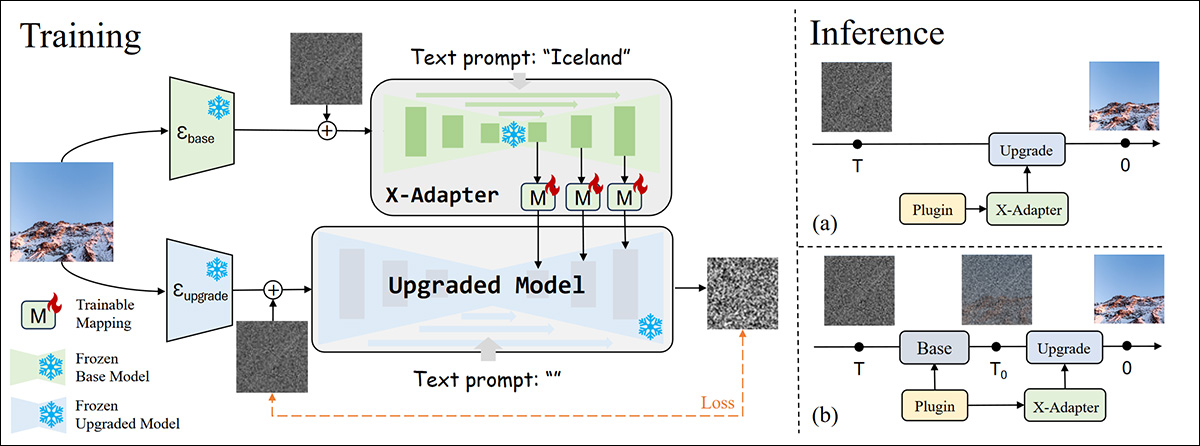
Esquema para X-Adapter. Fonte: https://arxiv.org/pdf/2312.02238
X-Adapter foi originalmente desenvolvido e testado para transferir adaptadores de SD1.5 para SDXL, enquanto LoRA-X oferece uma variedade mais ampla de transliterações.
DoRA (Adaptação de Baixa Classificação Decomprimida por Pesos)
DoRA é um método de fine-tuning aprimorado que melhora o LoRA usando uma estratégia de decomposição de peso que se assemelha mais ao fine-tuning completo:
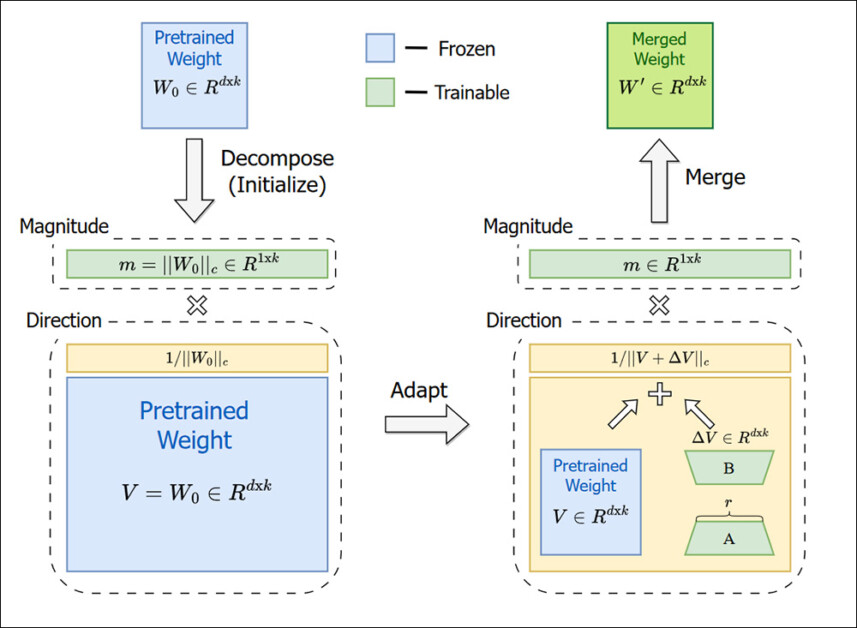
DORA não tenta apenas copiar um adaptador em um ambiente congelado, como faz o LoRA-X, mas sim muda fundamentalmente os parâmetros dos pesos, como magnitude e direção. Fonte: https://arxiv.org/pdf/2402.09353
DoRA foca em melhorar o próprio processo de fine-tuning, decompondo os pesos do modelo em magnitude e direção (veja a imagem acima). Em vez disso, o LoRA-X se concentra na possibilidade da transferência de parâmetros previamente ajustados entre diferentes modelos base.
No entanto, a abordagem LoRA-X adapta as técnicas de projeção desenvolvidas para a DORA e, em testes contra esse sistema mais antigo, reivindica uma pontuação DINO melhorada.
FouRA (Adaptação de Baixa Frequência de Fourier)
Publicada em junho de 2024, a método FouRA, assim como o LoRA-X, vem da Qualcomm AI Research e até compartilha alguns dos prompts de teste e temas.

Exemplos de colapso de distribuição no LoRA, do artigo de 2024 FouRA, usando o modelo Realistic Vision 3.0 treinado com LoRA e FouRA para adaptadores de estilo ‘Blue Fire’ e ‘Origami’, usando quatro seeds. As imagens LoRA exibem colapso de distribuição e diversidade reduzida, enquanto o FouRA gera saídas mais variadas. Fonte: https://arxiv.org/pdf/2406.08798
O FouRA foca em melhorar a diversidade e qualidade das imagens geradas, adaptando o LoRA no domínio da frequência, usando uma abordagem de transformada de Fourier.
Aqui, novamente, o LoRA-X foi capaz de alcançar melhores resultados do que a abordagem baseada em Fourier do FouRA.
Embora ambos os frameworks se enquadrem na categoria PEFT, eles têm casos de uso e abordagens muito diferentes; neste caso, o FouRA é, inegavelmente, ‘fazendo número’ para uma rodada de testes com rivais limitados e similares para que os novos autores do artigo se envolvam.
SVDiff
O SVDiff também possui objetivos diferentes do LoRA-X, mas é fortemente utilizado no novo artigo. O SVDiff é projetado para melhorar a eficiência do fine-tuning de modelos de difusão e modifica diretamente os valores dentro das matrizes de peso do modelo, enquanto mantém os vetores singulares inalterados. O SVDiff utiliza SVD truncado, modificando apenas os maiores valores, para ajustar os pesos do modelo.
Essa abordagem utiliza uma técnica de aumento de dados chamada Cut-Mix-Unmix:
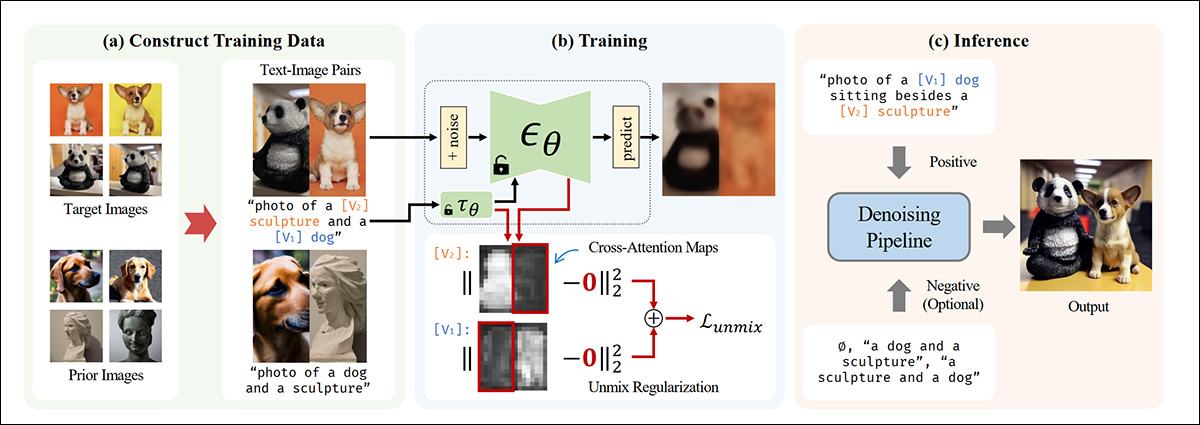
A geração de múltiplos sujeitos opera como um sistema de isolamento de conceito no SVDiff. Fonte: https://arxiv.org/pdf/2303.11305
Cut-Mix-Unmix é projetado para ajudar o modelo de difusão a aprender múltiplos conceitos distintos sem intermingle-los. A ideia central é pegar imagens de diferentes sujeitos e concatená-las em uma única imagem. Em seguida, o modelo é treinado com prompts que descrevem explicitamente os diferentes elementos na imagem. Isso força o modelo a reconhecer e preservar conceitos distintos ao invés de uni-los.
Durante o treinamento, um termo de regularização adicional ajuda a prevenir a interferência entre sujeitos. A teoria dos autores sustenta que isso facilita uma melhor geração multi-sujeitos, onde cada elemento permanece visualmente distinto, em vez de ser fundido.
O SVDiff, excluído da rodada de testes do LoRA-X, visa criar um espaço de parâmetros compacto. O LoRA-X, por outro lado, se concentra na transferibilidade dos parâmetros LoRA entre diferentes modelos base, operando dentro do subespaço do modelo original.
Conclusão
Os métodos discutidos aqui não são os únicos habitantes do PEFT. Outros incluem QLoRA e QA-LoRA; Tuning de Prefixo; Tuning de Prompt; e tuning de adaptador, entre outros.
A ‘LoRA atualizável’ é, talvez, uma busca alquímica; certamente, não há nada imediatamente à vista que impeça os modeladores de LoRA de terem que retirar seus velhos conjuntos de dados novamente para a mais recente e melhor versão de pesos. Se houver algum possível padrão de protótipo para revisão de pesos, capaz de sobreviver a mudanças na arquitetura e aumento de parâmetros entre versões de modelos, isso ainda não emergiu na literatura e precisará continuar a ser extraído dos dados em uma base por modelo.
Publicado pela primeira vez na quinta-feira, 30 de janeiro de 2025

Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…