


Modelos de linguagem de grande escala (LLMs) evoluíram significativamente. O que começou como simples ferramentas de geração de texto e tradução agora está sendo utilizado em pesquisa, tomada de decisões e resolução de problemas complexos. Um fator chave nessa mudança é a crescente capacidade dos LLMs de pensar de maneira mais sistemática, quebrando problemas, avaliando múltiplas possibilidades e refinando suas respostas de forma dinâmica. Em vez de apenas prever a próxima palavra em uma sequência, esses modelos agora podem realizar raciocínio estruturado, tornando-os mais eficazes no manuseio de tarefas complexas. Modelos líderes como o O3 da OpenAI, Gemini do Google e o R1 da DeepSeek integram essas capacidades para melhorar sua habilidade de processar e analisar informações de forma mais eficaz.
Entendendo o Pensamento Simulado
Os humanos naturalmente analisam diferentes opções antes de tomar decisões. Seja planejando uma viagem ou resolvendo um problema, frequentemente simulamos diferentes planos em nossa mente para avaliar múltiplos fatores, pesar prós e contras e ajustar nossas escolhas conforme necessário. Pesquisadores estão integrando essa capacidade nos LLMs para melhorar suas habilidades de raciocínio. Aqui, o pensamento simulado refere-se essencialmente à capacidade dos LLMs de realizar raciocínio sistemático antes de gerar uma resposta. Isso contrasta com simplesmente recuperar uma resposta de dados armazenados. Uma analogia útil é resolver um problema de matemática:
- Um AI básico pode reconhecer um padrão e gerar rapidamente uma resposta sem verificá-la.
- Um AI usando raciocínio simulado trabalharia através das etapas, checando erros e confirmando sua lógica antes de responder.
Chain-of-Thought: Ensinando AI a Pensar em Etapas
Se os LLMs precisam executar pensamento simulado como os humanos, eles devem ser capazes de dividir problemas complexos em etapas menores e sequenciais. É aqui que a técnica Chain-of-Thought (CoT) desempenha um papel crucial.
CoT é uma abordagem de prompting que orienta os LLMs a trabalharem através de problemas de forma metódica. Em vez de saltar para conclusões, esse processo de raciocínio estruturado permite que os LLMs dividam problemas complexos em etapas mais simples e gerenciáveis e os resolvam passo a passo.
Por exemplo, ao resolver um problema verbal em matemática:
- Um AI básico pode tentar combinar o problema com um exemplo previamente visto e fornecer uma resposta.
- Um AI usando raciocínio Chain-of-Thought esboçaria cada passo, trabalhando logicamente através de cálculos antes de chegar a uma solução final.
Essa abordagem é eficiente em áreas que requerem deduções lógicas, resolução de problemas em múltiplas etapas e compreensão contextual. Enquanto modelos anteriores exigiam cadeias de raciocínio fornecidas por humanos, LLMs avançados como o O3 da OpenAI e o R1 da DeepSeek podem aprender e aplicar raciocínio CoT de forma adaptativa.
Como LLMs Líderes Implementam o Pensamento Simulado
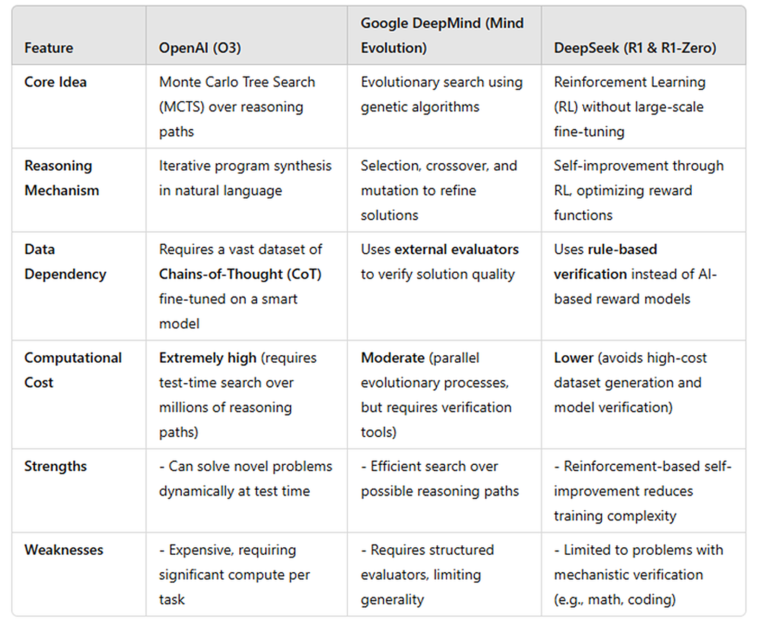
Diferentes LLMs estão empregando pensamento simulado de maneiras distintas. Abaixo está uma visão geral de como o O3 da OpenAI, os modelos da Google DeepMind e o DeepSeek-R1 estão executando pensamento simulado, junto com suas respectivas forças e limitações.
OpenAI O3: Pensando à Frente como um Jogador de Xadrez
Embora os detalhes exatos sobre o modelo O3 da OpenAI permaneçam não divulgados, pesquisadores acreditam que ele utiliza uma técnica semelhante à Pesquisa em Árvore de Monte Carlo (MCTS), uma estratégia usada em jogos impulsionados por AI como AlphaGo. Assim como um jogador de xadrez analisando múltiplos movimentos antes de decidir, o O3 explora diferentes soluções, avalia sua qualidade e seleciona a mais promissora.
Diferente de modelos anteriores que dependem do reconhecimento de padrões, o O3 gera e refina ativamente caminhos de raciocínio usando técnicas CoT. Durante a inferência, ele realiza etapas computacionais adicionais para construir múltiplas cadeias de raciocínio. Estas são então avaliadas por um modelo avaliador—provavelmente um modelo de recompensa treinado para garantir coerência lógica e correção. A resposta final é selecionada com base em um mecanismo de pontuação para fornecer uma saída bem-raciocionada.
O O3 segue um processo estruturado em várias etapas. Inicialmente, ele é ajustado em um vasto conjunto de dados de cadeias de raciocínio humanas, internalizando padrões de pensamento lógico. No momento da inferência, ele gera múltiplas soluções para um dado problema, classifica-as com base em correção e coerência, e refina a melhor, se necessário. Embora esse método permita que o O3 se autocorrija antes de responder e melhore a precisão, a desvantagem é o custo computacional—explorar múltiplas possibilidades requer poder de processamento significativo, tornando-o mais lento e intensivo em recursos. No entanto, o O3 se destaca na análise dinâmica e na resolução de problemas, posicionando-o entre os modelos de AI mais avançados hoje.
Google DeepMind: Refinando Respostas como um Editor
A DeepMind desenvolveu uma nova abordagem chamada “evolução da mente,” que trata o raciocínio como um processo de refinamento iterativo. Em vez de analisar múltiplos cenários futuros, este modelo atua mais como um editor refinando diversos rascunhos de um ensaio. O modelo gera várias respostas possíveis, avalia sua qualidade e refina a melhor.
Inspirado por algoritmos genéticos, esse processo garante respostas de alta qualidade por meio da iteração. É particularmente eficaz em tarefas estruturadas, como quebra-cabeças lógicos e desafios de programação, onde critérios claros determinam a melhor resposta.
No entanto, esse método possui limitações. Como ele depende de um sistema de pontuação externo para avaliar a qualidade da resposta, pode ter dificuldades com raciocínios abstratos sem uma resposta clara. Ao contrário do O3, que raciocina dinamicamente em tempo real, o modelo da DeepMind foca no refinamento de respostas existentes, tornando-o menos flexível para perguntas abertas.
DeepSeek-R1: Aprendendo a Raciocinar como um Estudante
O DeepSeek-R1 emprega uma abordagem baseada em aprendizado por reforço que permite desenvolver suas capacidades de raciocínio ao longo do tempo, em vez de avaliar múltiplas respostas em tempo real. Ao invés de depender de dados de raciocínio pré-gerados, o DeepSeek-R1 aprende resolvendo problemas, recebendo feedback e melhorando iterativamente—semelhante a como os alunos refinam suas habilidades de resolução de problemas com prática.
O modelo segue um ciclo de aprendizado por reforço estruturado. Ele começa com um modelo base, como o DeepSeek-V3, e é incentivado a resolver problemas matemáticos passo a passo. Cada resposta é verificada através da execução direta do código, pulando a necessidade de um modelo adicional para validar a correção. Se a solução estiver correta, o modelo recebe uma recompensa; se estiver incorreta, é penalizado. Esse processo é repetido extensivamente, permitindo que o DeepSeek-R1 refine suas habilidades de raciocínio lógico e priorize problemas mais complexos ao longo do tempo.
Uma vantagem chave dessa abordagem é a eficiência. Ao contrário do O3, que realiza um extenso raciocínio no momento da inferência, o DeepSeek-R1 incorpora capacidades de raciocínio durante o treinamento, tornando-o mais rápido e econômico. É altamente escalável, pois não requer um conjunto de dados rotulados massivos ou um modelo de verificação caro.
No entanto, essa abordagem baseada em aprendizado por reforço tem suas desvantagens. Como se baseia em tarefas com resultados verificáveis, ela se destaca em matemática e codificação. Porém, pode ter dificuldades com raciocínio abstrato em áreas como direito, ética ou resolução criativa de problemas. Embora o raciocínio matemático possa se transferir para outros domínios, sua aplicabilidade mais ampla permanece incerta.
Tabela: Comparação entre O3 da OpenAI, Evolução da Mente da DeepMind e R1 da DeepSeek
O Futuro do Raciocínio em AI
O raciocínio simulado é um passo significativo rumo a tornar a IA mais confiável e inteligente. À medida que esses modelos evoluem, o foco se deslocará de simplesmente gerar texto para desenvolver habilidades robustas de resolução de problemas que se assemelham ao pensamento humano. Avanços futuros provavelmente se concentrarão em capacitar modelos de IA a identificar e corrigir erros, integrá-los com ferramentas externas para verificar respostas e reconhecer incertezas quando confrontados com informações ambíguas. No entanto, um desafio fundamental é equilibrar a profundidade do raciocínio com a eficiência computacional. O objetivo final é desenvolver sistemas de IA que considerem cuidadosamente suas respostas, garantindo precisão e confiabilidade, semelhante a um especialista humano avaliando cada decisão antes de agir.

Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…