


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder na indústria. Saiba Mais
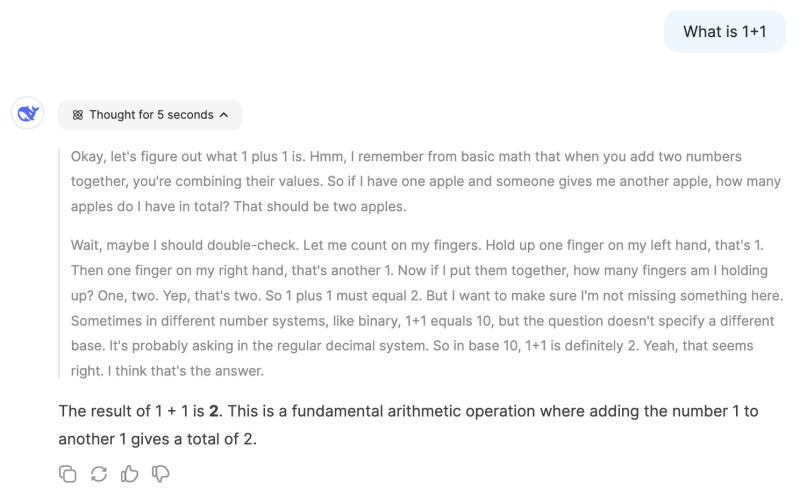
Modelos de raciocínio como OpenAI o1 e DeepSeek-R1 enfrentam um problema: eles superpensam. Pergunte-lhes uma pergunta simples como “Qual é 1+1?” e eles levarão vários segundos até responder.
Idealmente, assim como os humanos, os modelos de IA devem saber quando fornecer uma resposta direta e quando gastar mais tempo e recursos raciocinando antes de responder. Uma nova técnica, apresentada por pesquisadores da Meta AI e da Universidade de Illinois em Chicago, treina modelos para alocar orçamentos de inferência com base na dificuldade da consulta. Isso resulta em respostas mais rápidas, redução de custos e melhor alocação de recursos computacionais.
Raciocínio caro
Modelos de linguagem grandes (LLMs) podem melhorar seu desempenho em problemas de raciocínio ao produzirem cadeias de raciocínio mais longas, frequentemente referidas como “cadeia de pensamento” (CoT). O sucesso do CoT levou a uma série de técnicas de escalonamento em tempo de inferência que orientam o modelo a “pensar” mais tempo sobre o problema, produzir e revisar várias respostas e escolher a melhor.
Uma das principais abordagens utilizadas em modelos de raciocínio é gerar várias respostas e escolher a que ocorre com mais frequência, também conhecida como “votação por maioria” (MV). O problema com essa abordagem é que o modelo adota um comportamento uniforme, tratando cada prompt como um problema de raciocínio difícil e gastando recursos desnecessários para gerar múltiplas respostas.
Raciocínio inteligente
O novo artigo propõe uma série de técnicas de treinamento que tornam os modelos de raciocínio mais eficientes nas respostas. O primeiro passo é a “votação sequencial” (SV), onde o modelo interrompe o processo de raciocínio assim que uma resposta aparece um certo número de vezes. Por exemplo, o modelo deve gerar um máximo de oito respostas e escolher a que aparece pelo menos três vezes. Se o modelo receber a consulta simples mencionada acima, as três primeiras respostas provavelmente serão semelhantes, o que acionará a interrupção precoce, economizando tempo e recursos computacionais.
Os experimentos mostram que SV supera a MV clássica em problemas de competição matemática quando gera o mesmo número de respostas. No entanto, a SV exige instruções e geração de tokens adicionais, o que a coloca em paridade com a MV em termos da relação token-precisão.
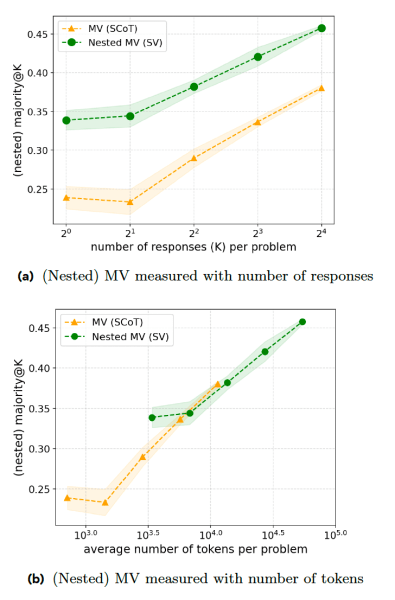
A segunda técnica, “votação sequencial adaptativa” (ASV), melhora a SV, orientando o modelo a examinar o problema e gerar várias respostas somente quando o problema é difícil. Para problemas simples (como a consulta 1+1), o modelo simplesmente gera uma resposta sem passar pelo processo de votação. Isso torna o modelo muito mais eficiente ao lidar com problemas simples e complexos.
Aprendizado por reforço
Embora tanto a SV quanto a ASV melhorem a eficiência do modelo, elas exigem muitos dados rotulados manualmente. Para aliviar esse problema, os pesquisadores propõem a “Otimização de Políticas com Orçamento de Inferência Constrangido” (IBPO), um algoritmo de aprendizado por reforço que ensina o modelo a ajustar o comprimento das trilhas de raciocínio com base na dificuldade da consulta.
O IBPO é projetado para permitir que os LLMs otimizem suas respostas enquanto permanecem dentro de um orçamento de inferência. O algoritmo de RL permite que o modelo supere os ganhos obtidos através do treinamento em dados rotulados manualmente, gerando constantemente trilhas ASV, avaliando as respostas e escolhendo resultados que fornecem a resposta correta e o orçamento de inferência ideal.
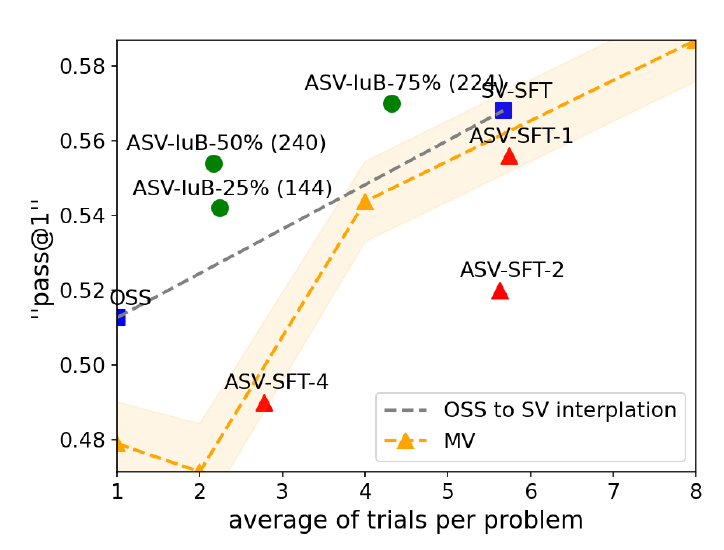
Os experimentos deles mostram que o IBPO melhora a fronteira de Pareto, o que significa que, para um orçamento de inferência fixo, um modelo treinado com IBPO supera outras bases de comparação.
As descobertas ocorrem em um contexto em que pesquisadores alertam que os modelos de IA atuais estão atingindo um muro. As empresas estão lutando para encontrar dados de treinamento de qualidade e estão explorando métodos alternativos para melhorar seus modelos.
Uma solução promissora é o aprendizado por reforço, onde o modelo recebe um objetivo e é permitido encontrar suas próprias soluções, em contraste com o ajuste fino supervisionado (SFT), onde o modelo é treinado com exemplos rotulados manualmente.
Surpreendentemente, o modelo frequentemente encontra soluções que os humanos não tinham considerado. Essa é uma fórmula que parece ter funcionado bem para o DeepSeek-R1, que desafiou o domínio dos laboratórios de IA baseados nos EUA.
Os pesquisadores observam que “métodos baseados em prompting e SFT lutam tanto com melhorias absolutas quanto com eficiência, apoiando a conjectura de que SFT sozinho não permite capacidades de autocorreção. Esta observação também é parcialmente apoiada por um trabalho concorrente, que sugere que esse comportamento de autocorreção emerge automaticamente durante o RL, ao invés de ser criado manualmente por prompting ou SFT.”


Conteúdo relacionado

OpenAI se lança de cabeça com Jony Ive enquanto o Google tenta alcançar na corrida da IA.
A OpenAI acaba de realizar sua maior aquisição até agora, adquirindo a startup de dispositivos secreta de Jony Ive e Sam Altman, a io, em um acordo de $6,5…

Anthropic supera OpenAI: Claude Opus 4 codifica por sete horas ininterruptas, estabelece recorde no SWE-Bench e transforma a IA empresarial.
Participe das nossas newsletters diárias e semanais para receber atualizações e conteúdos exclusivos sobre a liderança da indústria em IA. Saiba Mais…

A OpenAI se une à Cisco e Oracle para construir um data center nos Emirados Árabes Unidos.
Conforme rumores, a OpenAI está expandindo seu ambicioso projeto de data center Stargate para o Oriente Médio. Na quinta-feira, a empresa anunciou o…