


Todo domingo, o apresentador da NPR Will Shortz, guru do quebra-cabeça do The New York Times, tem a oportunidade de questionar milhares de ouvintes em um segmento de longa data chamado Sunday Puzzle. Embora tenha sido elaborado para ser resolvido sem muito conhecimento prévio, os enigmas costumam ser desafiadores mesmo para concorrentes experientes.
É por isso que alguns especialistas acreditam que eles são uma maneira promissora de testar os limites das habilidades de resolução de problemas da IA.
Em um novo estudo, uma equipe de pesquisadores proveniente do Wellesley College, Oberlin College, Universidade do Texas em Austin, Northeastern University e da startup Cursor criou um benchmark de IA utilizando charadas dos episódios do Sunday Puzzle. A equipe afirma que seu teste revela insights surpreendentes, como o fato de que modelos de raciocínio — incluindo o o1 da OpenAI, entre outros — às vezes “desistem” e fornecem respostas que sabem não ser corretas.
“Queríamos desenvolver um benchmark com problemas que humanos podem entender apenas com conhecimento geral,” disse Arjun Guha, um estudante de graduação em ciência da computação na Northeastern e um dos co-autores do estudo, ao TechCrunch.
A indústria de IA se encontra em um dilema de benchmarking no momento. A maioria dos testes comuns usados para avaliar modelos de IA investiga habilidades, como competência em perguntas de matemática e ciência de nível de doutorado, que não são relevantes para o usuário médio. Enquanto isso, muitos benchmarks — até mesmo benchmarks lançados relativamente recentemente — estão rapidamente se aproximando do ponto de saturação.
As vantagens de um jogo de perguntas e respostas da rádio pública como o Sunday Puzzle é que ele não testa conhecimentos esotéricos, e os desafios são formulados de tal maneira que os modelos não conseguem recorrer à “memória de decor” para resolvê-los, explicou Guha.
“Acredito que o que torna esses problemas difíceis é que é realmente complicado fazer progresso significativo em um problema até que você o resolva — é quando tudo se encaixa de uma vez,” disse Guha. “Isso requer uma combinação de insight e um processo de eliminação.”
Nenhum benchmark é perfeito, é claro. O Sunday Puzzle é centrado nos EUA e é em inglês apenas. E como os questionários estão disponíveis publicamente, é possível que modelos treinados com eles possam “trapacear” de certa forma, embora Guha diga que não viu evidências disso.
“Novas questões são lançadas toda semana, e podemos esperar que as perguntas mais recentes sejam realmente inéditas,” acrescentou. “Pretendemos manter o benchmark atualizado e acompanhar como o desempenho do modelo muda ao longo do tempo.”
No benchmark dos pesquisadores, que consiste em cerca de 600 charadas do Sunday Puzzle, modelos de raciocínio, como o o1 e o R1 da DeepSeek, superam em muito os demais. Os modelos de raciocínio verificam minuciosamente suas respostas antes de divulgá-las, o que os ajuda a evitar algumas das armadilhas que normalmente atrapalham os modelos de IA. A desvantagem é que modelos de raciocínio demoram um pouco mais para chegar a soluções — geralmente alguns segundos a minutos a mais.
Pelo menos um modelo, o R1 da DeepSeek, fornece soluções que sabe serem erradas para algumas das perguntas do Sunday Puzzle. O R1 declara literalmente “Eu desisto,” seguido de uma resposta incorreta escolhida aparentemente ao acaso — um comportamento com o qual este humano certamente se identifica.
Os modelos fazem outras escolhas bizarras, como dar uma resposta errada apenas para imediatamente retratá-la, tentar extrair uma melhor e falhar novamente. Eles também ficam “pensando” indefinidamente e fornecem explicações sem sentido para as respostas, ou chegam a uma resposta correta imediatamente, mas depois consideram alternativas sem motivo aparente.
“Em problemas difíceis, o R1 literalmente diz que está ficando ‘frustrado’,” disse Guha. “Foi engraçado ver como um modelo emula o que um humano poderia dizer. Resta saber como a ‘frustração’ no raciocínio pode afetar a qualidade dos resultados do modelo.”

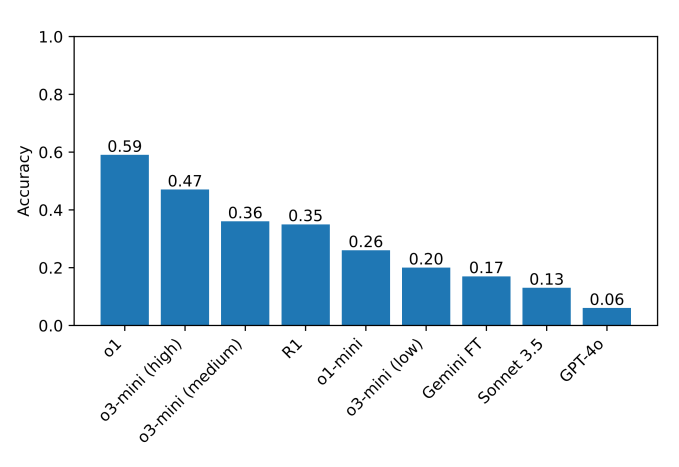
O modelo que atualmente se sai melhor no benchmark é o o1 com uma pontuação de 59%, seguido pelo recentemente lançado o3-mini configurado para um “esforço de raciocínio” alto (47%). (O R1 pontuou 35%.) Como próximo passo, os pesquisadores planejam ampliar seus testes para incluir modelos de raciocínio adicionais, que esperam ajudar a identificar áreas em que esses modelos possam ser aprimorados.
“Você não precisa de um doutorado para ser bom em raciocínio, então deve ser possível desenhar benchmarks de raciocínio que não exijam conhecimento a nível de doutorado,” disse Guha. “Um benchmark com acesso mais amplo permite que um conjunto mais amplo de pesquisadores compreenda e analise os resultados, o que pode levar a melhores soluções no futuro. Além disso, à medida que modelos de ponta são cada vez mais implantados em cenários que afetam todos, acreditamos que todos deveriam ser capazes de intuir o que esses modelos são — e o que não são — capazes de fazer.”

Conteúdo relacionado

Anthropic transforma a abordagem da IA na educação: o Modo de Aprendizagem do Claude faz os alunos refletirem.
[the_ad id="145565"] Junte-se aos nossos boletins diários e semanais para as últimas novidades e conteúdo exclusivo sobre cobertura de IA de liderança no setor. Saiba mais……

Anthropic lança um plano de chatbot de IA para faculdades e universidades
[the_ad id="145565"] A Anthropic anunciou na quarta-feira que está lançando uma nova camada Claude para Educação, como resposta ao plano ChatGPT Edu da OpenAI. A nova camada é…

O artigo de 145 páginas da DeepMind sobre segurança em AGI pode não convencer os céticos.
[the_ad id="145565"] O Google DeepMind publicou na quarta-feira um documento exaustivo sobre sua abordagem de segurança para AGI, definida de forma ampla como uma IA capaz de…