


Junte-se às nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba mais
Assim que os agentes de IA mostraram potencial, as organizações tiveram que enfrentar a questão de se um único agente seria suficiente ou se deveriam investir na construção de uma rede de múltiplos agentes que abrangesse mais pontos em sua organização.
A empresa de framework de orquestração LangChain buscou se aproximar de uma resposta para essa pergunta. Ela submeteu um agente de IA a vários experimentos que revelaram que os agentes únicos têm um limite de contexto e ferramentas antes que seu desempenho comece a se degradar. Esses experimentos podem levar a uma melhor compreensão da arquitetura necessária para manter agentes e sistemas de múltiplos agentes.
Em um post do blog, a LangChain detalhou um conjunto de experimentos realizados com um único agente ReAct e avaliou seu desempenho. A principal questão que a LangChain esperava responder era: “Em que ponto um único agente ReAct fica sobrecarregado com instruções e ferramentas, e, em seguida, vê seu desempenho diminuir?”
A LangChain optou por usar o framework de agente ReAct porque é “uma das arquiteturas agênticas mais básicas”.
Embora a avaliação do desempenho agêntico possa muitas vezes levar a resultados enganosos, a LangChain optou por limitar o teste a duas tarefas facilmente quantificáveis de um agente: responder a perguntas e agendar reuniões.
“Existem muitos benchmarks existentes para uso de ferramentas e chamadas de ferramentas, mas para os propósitos deste experimento, queríamos avaliar um agente prático que realmente usamos,” escreveu a LangChain. “Esse agente é nosso assistente de e-mail interno, que é responsável por duas principais áreas de trabalho — responder e agendar solicitações de reuniões e apoiar clientes com suas perguntas.”
Parâmetros do experimento da LangChain
A LangChain usou principalmente agentes ReAct pré-construídos por meio de sua plataforma LangGraph. Esses agentes contavam com modelos de linguagem de grande porte (LLMs) que foram parte do teste de benchmark. Esses LLMs incluíram o Claude 3.5 Sonnet da Anthropic, o Llama-3.3-70B da Meta e um trio de modelos da OpenAI, GPT-4o, o1 e o3-mini.
A empresa dividiu os testes para avaliar melhor o desempenho do assistente de e-mail nas duas tarefas, criando uma lista de etapas para ele seguir. Começou pelas capacidades de suporte ao cliente do assistente de e-mail, que analisam como o agente aceita um e-mail de um cliente e responde com uma resposta.
A LangChain primeiro avaliou a trajetória de chamada de ferramentas, ou as ferramentas que um agente utiliza. Se o agente seguisse a ordem correta, ele passava no teste. Em seguida, os pesquisadores pediram ao assistente que respondesse a um e-mail e usaram um LLM para julgar seu desempenho.


Para o segundo domínio de trabalho, agendamento de calendário, a LangChain se concentrou na capacidade do agente de seguir instruções.
“Em outras palavras, o agente precisa lembrar de instruções específicas fornecidas, como exatamente quando deve agendar reuniões com diferentes partes,” escreveram os pesquisadores.
Sobrecarga do agente
Depois de definir os parâmetros, a LangChain começou a estressar e sobrecarregar o agente assistente de e-mail.
Ela estabeleceu 30 tarefas para agendamento de calendário e suporte ao cliente. Estas foram executadas três vezes (totalizando 90 execuções). Os pesquisadores criaram um agente de agendamento de calendário e um agente de suporte ao cliente para avaliar melhor as tarefas.
“O agente de agendamento de calendário só tem acesso ao domínio de agendamento de calendário, e o agente de suporte ao cliente só tem acesso ao domínio de suporte ao cliente,” explicou a LangChain.
Os pesquisadores então adicionaram mais tarefas e ferramentas aos agentes para aumentar o número de responsabilidades. Essas poderiam incluir desde recursos humanos até garantia de qualidade técnica, jurídico e compliance, e uma série de outras áreas.
Degradação da instrução de agente único
Após realizar as avaliações, a LangChain descobriu que agentes únicos frequentemente ficavam sobrecarregados quando instruídos a fazer muitas coisas. Eles começaram a esquecer de chamar ferramentas ou não conseguiam responder a tarefas quando dados mais instruções e contextos.
A LangChain constatou que os agentes de agendamento de calendário usando GPT-4o “desempenharam pior que o Claude-3.5-sonnet, o1 e o3 em diversos tamanhos de contexto, e o desempenho caiu de forma mais acentuada do que os outros modelos quando contextos maiores foram fornecidos.” O desempenho dos agendadores de calendário GPT-4o caiu para 2% quando os domínios aumentaram para pelo menos sete.
Outros modelos não se saíram muito melhor. O Llama-3.3-70B esqueceu de chamar a ferramenta send_email, “portanto, falhou em todos os casos de teste.”
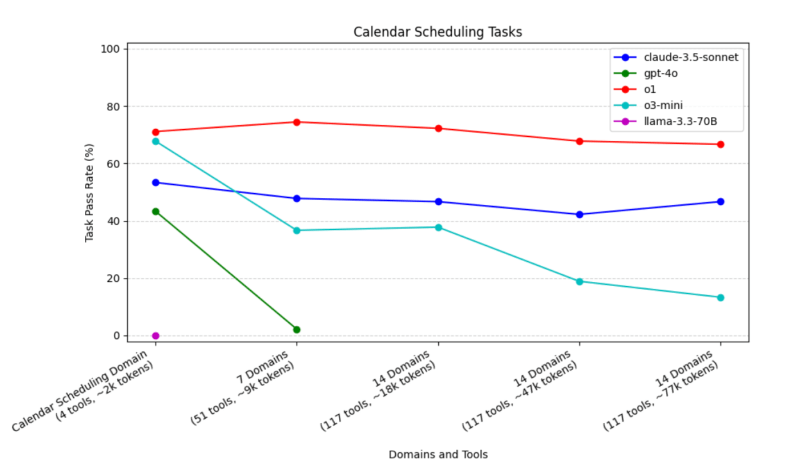
Apenas o Claude-3.5-sonnet, o1 e o3-mini lembraram de chamar a ferramenta, mas o Claude-3.5-sonnet apresentou desempenho inferior aos dois outros modelos da OpenAI. No entanto, o desempenho do o3-mini degrada uma vez que domínios irrelevantes são adicionados às instruções de agendamento.
O agente de suporte ao cliente pode chamar mais ferramentas, mas para este teste, a LangChain disse que o Claude-3.5-mini teve um desempenho tão bom quanto o o3-mini e o o1. Ele também apresentou uma queda de desempenho mais superficial quando mais domínios foram adicionados. Contudo, quando a janela de contexto se estende, o modelo Claude apresenta um desempenho inferior.
O GPT-4o também teve o pior desempenho entre os modelos testados.
“Vimos que à medida que mais contexto era fornecido, o seguimento de instruções se tornava pior. Algumas das nossas tarefas foram projetadas para seguir instruções específicas de nicho (por exemplo, não realizar uma determinada ação para clientes baseados na UE),” observou a LangChain. “Descobrimos que essas instruções seriam seguidas com sucesso por agentes com menos domínios, mas conforme o número de domínios aumentava, essas instruções eram mais frequentemente esquecidas, e as tarefas fracassavam.”
A empresa afirmou que está explorando como avaliar arquiteturas de múltiplos agentes usando o mesmo método de sobrecarga de domínio.
A LangChain já está investida no desempenho de agentes, pois introduziu o conceito de “agentes ambientais”, ou agentes que funcionam em segundo plano e são ativados por eventos específicos. Esses experimentos poderiam facilitar a identificação da melhor forma de garantir o desempenho agêntico.


Conteúdo relacionado

O novo jogo da Tinder com inteligência artificial avalia suas habilidades de conquista
[the_ad id="145565"] Você sabe que a cena de namoro online está ruim quando gigantes do setor, como o Tinder, estão introduzindo personas de IA para os usuários flertarem. Na…

Qualcomm adquire divisão de IA generativa da startup vietnamita VinAI
[the_ad id="145565"] A Qualcomm adquiriu a divisão de IA generativa da VinAI, uma empresa de pesquisa em IA com sede em Hanói, por um valor não revelado, conforme anunciado…

Sam Altman afirma que os problemas de capacidade da OpenAI causarão atrasos nos produtos.
[the_ad id="145565"] Em uma série de publicações no X na segunda-feira, o CEO da OpenAI, Sam Altman, afirmou que a popularidade da nova ferramenta de geração de imagens no…