


Participe de nossas newsletters diárias e semanais para atualizações mais recentes e conteúdo exclusivo sobre a cobertura líder de mercado em IA. Saiba Mais
Estatísticas podem ser tudo no basquete — mas para a Pacers Sports and Entertainment (PS&E), dados sobre fãs são igualmente valiosos.
No entanto, enquanto a empresa-mãe do Indiana Pacers (NBA), do Indiana Fever (WNBA) e do Indiana Mad Ants (NBA G League) investia enormes quantidades em uma plataforma de aprendizado de máquina (ML) de $100,000 por ano para gerar modelos preditivos em fatores como preços e demanda por ingressos, os insights não estavam vindo rápido o suficiente.
Jared Chavez, gerente de engenharia de dados e estratégia, saiu para mudar isso, fazendo a transição para o Databricks no Salesforce há um ano e meio.
Agora? Sua equipe está realizando a mesma gama de projetos preditivos com configurações de computação cuidadosas para obter insights críticos sobre o comportamento dos fãs — por apenas $8 por ano. É uma diminuição surpreendente e aparentemente impensável que Chavez credita em grande parte à capacidade de sua equipe de reduzir a computação em ML a quantidades quase insignificantes.
“Somos muito bons em otimizar nossa computação e descobrir exatamente até onde podemos reduzir o limite para que nossos modelos funcionem”, disse ele ao VentureBeat. “É isso que realmente nos destacou com o Databricks.”
Reduzindo OpEx em 98%
Além de seus três times de basquete, a PS&E com sede em Indianápolis hospeda jogos da March Madness e administra um movimentado negócio de eventos que dura mais de 300 dias por ano no Gainbridge Fieldhouse (shows, comédia, rodeios, outros eventos esportivos). Além disso, a empresa anunciou no mês passado planos para construir um Centro de Desempenho Esportivo da Indiana Fever de $78 milhões, que será conectado por uma passarela ao arena e um estacionamento (esperado para ser inaugurado em 2027).
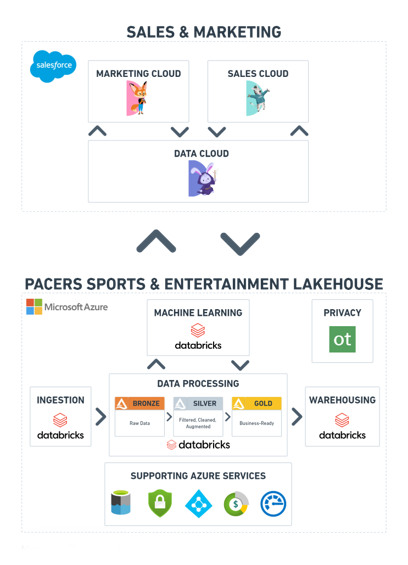
Tudo isso gera uma quantidade impressionante de dados — e uma dispersão de dados. Do ponto de vista da infraestrutura de dados, Chavez apontou que, até dois anos atrás, a organização hospedava dois armazéns totalmente independentes construídos na Microsoft Azure Synapse Analytics. Diferentes equipes pelo negócio usavam sua própria forma de análises, e as ferramentas e habilidades variavam enormemente.
Enquanto o Azure Synapse fazia um excelente trabalho conectando-se a plataformas externas, era financeiramente proibitivo para uma organização do tamanho da PS&E, explicou. Além disso, a integração da plataforma de ML da empresa com Microsoft Azure Data Studio levou à fragmentação.
Para resolver esses problemas, Chavez fez a transição para o Databricks AutoML e o Databricks Machine Learning Workspace em agosto de 2023. O foco inicial era configurar, treinar e implantar modelos relacionados a preços de ingressos e demanda por jogos.
Tanto usuários técnicos quanto não técnicos rapidamente acharam as plataformas úteis, destacou Chavez, e aumentaram rapidamente a velocidade do processo de ML (e reduziram drasticamente os custos).
“Isso melhora dramaticamente os tempos de resposta para minha equipe de marketing, porque eles não precisam saber como programar”, disse Chavez. “Para eles, são apenas botões, e todos esses dados retornam para o Databricks como registros unificados.”
Além disso, sua equipe organizou os mais de 60 sistemas da empresa no Salesforce Data Cloud. Agora, ele relata que possuem 440X mais dados em armazenamento e 8X mais fontes de dados em produção.
A PS&E atualmente opera com menos de 2% de seus custos anuais anteriores de OPEX. “Economizamos centenas de milhares por ano apenas em operações”, disse Chavez. “Reinvestimos em enriquecimento de dados dos clientes. Reinvestimos em melhores ferramentas não apenas para minha equipe, mas para as unidades de análise em toda a empresa.”
Refinamento contínuo, profunda compreensão dos dados
Como sua equipe conseguiu reduzir tanto os custos de computação? Databricks continuamente refinou as configurações de cluster, melhorou as opções de conectividade para esquemas e integrou saídas de modelos de volta às tabelas de dados da PS&E, explicou Chavez. O poderoso motor de ML está “continuamente enriquecendo, refinando, mesclando e prevendo” os registros de clientes da PS&E em todos os sistemas e fluxos de receita.
Isso leva a previsões mais bem informadas a cada iteração — e de fato, o ocasional modelo AutoML às vezes vai direto para produção sem nenhum outro ajuste de sua equipe, relatou Chavez.
“Na verdade, é apenas saber o tamanho dos dados que estão entrando, mas também mais ou menos quanto tempo vai levar para treinar,” disse Chavez. Ele acrescentou: “É no menor tamanho de cluster que você poderia executar, pode ser apenas um cluster otimizado para memória, mas é saber o Apache Spark razoavelmente bem e conhecer o melhor modo de armazenar e ler os dados de maneira otimizada.”
Quem é mais provável de comprar ingressos de temporada?
Uma forma que a equipe de Chavez está utilizando dados, IA e ML é na pontuação de propensão para pacotes de ingressos de temporada. Como ele disse: “Vendemos uma quantidade incrível deles.”
O objetivo é determinar quais características dos clientes influenciam onde eles escolhem sentar. Chavez explicou que sua equipe está geolocalizando os endereços que possuem registrados para fazer correlações entre demografia, níveis de renda e distâncias de viagem. Eles também estão analisando os históricos de compras dos usuários em varejo, alimentação e bebidas, engajamento em aplicativos móveis e outros eventos que possam ocorrer no campus da PS&E.
Além disso, eles estão coletando dados do Stubhub, Seat Geek e outros fornecedores fora do Ticketmaster para avaliar pontos de preço e determinar como os inventários estão se movendo. Isso pode ser combinado com tudo que sabem sobre um determinado cliente para descobrir onde eles provavelmente escolherão se sentar, explicou Chavez.
Armados com esses dados, eles podem, por exemplo, oferecer um upsell de um cliente da Seção 201 para a Seção 101. “Agora somos capazes de não apenas revender o assento dele na parte superior, mas também vender outro pacote menor nos mesmos assentos que ele comprou no meio da temporada, usando as mesmas características para outra pessoa”, disse Chavez.
De forma semelhante, os dados podem ser usados para aprimorar patrocínios, que são críticos para qualquer franquia esportiva.
“Claro que eles querem se alinhar com organizações que se sobreponham às suas,” disse Chavez. “Então, podemos enriquecer melhor? Podemos prever melhor? Podemos fazer segmentação personalizada?”
Idealmente, o objetivo é ter uma interface onde qualquer usuário possa fazer perguntas como: ‘Dê-me uma seção da base de fãs dos Pacers na casa dos 20 anos com renda disponível.’ Indo ainda mais longe: ‘Procure aqueles que ganham mais de $100K por ano e têm interesse em veículos de luxo.’ A interface poderia então trazer de volta uma porcentagem que se sobreponha aos dados dos patrocinadores.
“Quando nossas equipes de parcerias estão tentando fechar esses negócios, eles podem, sob demanda, apenas puxar informações sem ter que depender de uma equipe de análise para fazer isso por eles,” disse Chavez.
Para apoiar ainda mais esse objetivo, sua equipe está procurando construir uma sala limpa de dados, ou um ambiente seguro que permita o compartilhamento de dados sensíveis. Isso pode ser particularmente útil com patrocinadores, bem como colaborações com outras equipes e a NCAA (que está sediada em Indianápolis).
“O nome do jogo para nós agora é tempo de resposta, seja para o cliente ou internamente,” disse Chavez. “Podemos reduzir drasticamente o conhecimento necessário para separar informações e filtrá-las usando IA?”
Coleta de dados e IA para entender padrões de tráfego, melhorar sinalização
Outra área de foco da equipe de Chavez é examinar onde as pessoas estão a qualquer momento no campus da PS&E (que compreende uma arena de três níveis com uma praça externa). Chavez explicou que as capacidades de captura de dados estão em vigor ao longo de toda a rede da infraestrutura via pontos de acesso WiFi.
“Quando você entra na arena, está se comunicando com todos eles, mesmo se não se conectar a eles, porque seu telefone está verificando WiFi,” disse ele. “Posso ver para onde você está se movendo. Não sei quem você é, mas posso ver para onde você está se movendo.”
Isso pode eventualmente ajudar a guiar as pessoas ao redor da arena — digamos, se alguém quiser comprar um pretzel e estiver procurando por um quiosque de alimentos — e ajudar sua equipe a determinar onde posicionar quiosques de alimentos e mercadorias.
De forma semelhante, os dados de localização podem ajudar a determinar os melhores locais para sinalização, explicou Chavez. Uma maneira interessante de identificar contagens de impressões de sinalização é colocando gradientes de visão em locais equivalentes à altura média dos fãs.
“Então, vamos calcular quão bem alguém teria visto isso ao passar por lá com o número de pessoas ao redor deles,” disse Chavez. “Assim, posso informar ao meu patrocinador que você teve 5.000 impressões nessa, e 1.200 delas foram boas.”
De forma semelhante, quando os fãs estão em seus assentos, estão cercados por placas e displays digitais. Os dados de localização podem ajudar a determinar a qualidade (e a quantidade) de impressões com base no ângulo em que estão sentados. Como observou Chavez: “Se esse anúncio ficou apenas na tela por 10 segundos no terceiro quarto, quem o veria?”
Uma vez que a PS&E tenha dados de localização suficientes para ajudar a responder a esses tipos de perguntas, sua equipe planeja trabalhar com o laboratório de VR da Universidade de Indiana para modelar todo o campus. “Então, vamos ter um terreno muito divertido para explorar e responder todas essas perguntas em espaço 3D que me incomodam há dois anos,” disse Chavez.


Conteúdo relacionado

Anthropic transforma a abordagem da IA na educação: o Modo de Aprendizagem do Claude faz os alunos refletirem.
[the_ad id="145565"] Junte-se aos nossos boletins diários e semanais para as últimas novidades e conteúdo exclusivo sobre cobertura de IA de liderança no setor. Saiba mais……

Anthropic lança um plano de chatbot de IA para faculdades e universidades
[the_ad id="145565"] A Anthropic anunciou na quarta-feira que está lançando uma nova camada Claude para Educação, como resposta ao plano ChatGPT Edu da OpenAI. A nova camada é…

O artigo de 145 páginas da DeepMind sobre segurança em AGI pode não convencer os céticos.
[the_ad id="145565"] O Google DeepMind publicou na quarta-feira um documento exaustivo sobre sua abordagem de segurança para AGI, definida de forma ampla como uma IA capaz de…