


Participe das nossas newsletters diárias e semanais para receber as atualizações mais recentes e conteúdo exclusivo sobre a cobertura líder da indústria em IA. Saiba Mais
Modelos de linguagem podem generalizar melhor quando são deixados para criar suas próprias soluções, segundo um novo estudo da Universidade de Hong Kong e da Universidade da Califórnia, Berkeley. As descobertas, que se aplicam tanto a grandes modelos de linguagem (LLMs) quanto a modelos de linguagem visual (VLMs), desafiam uma das principais crenças da comunidade de LLMs — que os modelos precisam de exemplos de treinamento rotulados manualmente. De fato, os pesquisadores mostram que treinar modelos com muitos exemplos elaborados manualmente pode ter efeitos adversos na capacidade do modelo de generalizar para dados não vistos.
SFT vs RL no treinamento de modelos
Por um longo tempo, o ajuste fino supervisionado (SFT) tem sido o padrão de ouro para treinar LLMs e VLMs. Uma vez que um modelo é pré-treinado em dados brutos de texto e imagem, empresas e laboratórios de IA geralmente o pós-treinam em um grande conjunto de dados de exemplos elaborados manualmente em formato de pergunta/resposta ou solicitação/resposta. Após o SFT, o modelo pode passar por estágios adicionais de treinamento, como aprendizado por reforço com feedback humano (RLHF), onde o modelo tenta aprender preferências humanas implícitas com base em sinais como classificações de respostas ou gostos/desgostos das respostas do modelo.
O SFT é útil para direcionar o comportamento de um modelo em direção aos tipos de tarefas para os quais os criadores do modelo o projetaram. No entanto, reunir os dados é um processo lento e caro, sendo um gargalo para muitas empresas e laboratórios.
Desenvolvimentos recentes em LLMs despertaram interesse em abordagens puras de aprendizado por reforço (RL), onde o modelo recebe uma tarefa e é deixado para aprendê-la sozinho, sem exemplos elaborados manualmente. O exemplo mais importante é o DeepSeek-R1, o concorrente o1 da OpenAI que utilizou principalmente aprendizado por reforço para aprender tarefas complexas de raciocínio.
Generalização vs memorização
Um dos principais problemas dos sistemas de aprendizado de máquina (ML) é o overfitting, onde o modelo apresenta bom desempenho em seus dados de treinamento, mas falha ao generalizar para exemplos não vistos. Durante o treinamento, o modelo dá a falsa impressão de ter aprendido a tarefa, enquanto na verdade apenas memorizou seus exemplos de treinamento. Em modelos de IA grandes e complexos, separar generalização de memorização pode ser difícil.
O novo estudo foca nas habilidades de generalização dos treinamentos RL e SFT em tarefas de raciocínio textual e visual. Para raciocínio textual, um LLM treinado em um conjunto de regras deve ser capaz de generalizar para variantes dessas regras. No raciocínio visual, um VLM deve manter a consistência no desempenho da tarefa diante de mudanças em diferentes aspectos da entrada visual, como cor e disposição espacial.

Em seus experimentos, os pesquisadores usaram duas tarefas representativas. Primeiro foi o GeneralPoints, um benchmark que avalia as capacidades de raciocínio aritmético de um modelo. O modelo recebe quatro cartas, como descrições textuais ou imagens, e é solicitado a combiná-las para alcançar um número-alvo. Para estudar a generalização baseada em regras, os pesquisadores treinaram o modelo usando um conjunto de regras e, em seguida, o avaliaram usando uma regra diferente. Para a generalização visual, eles treinaram o modelo usando cartas de uma cor e testaram seu desempenho em cartas de outras cores e esquemas de numeração.
A segunda tarefa é V-IRL, que testa as capacidades de raciocínio espacial do modelo em um domínio de navegação em mundo aberto que utiliza entradas visuais realistas. Esta tarefa também possui versões puras em linguagem e linguagem-visual. Os pesquisadores avaliaram a generalização alterando o tipo de instruções e representações visuais que o modelo foi treinado e testado.
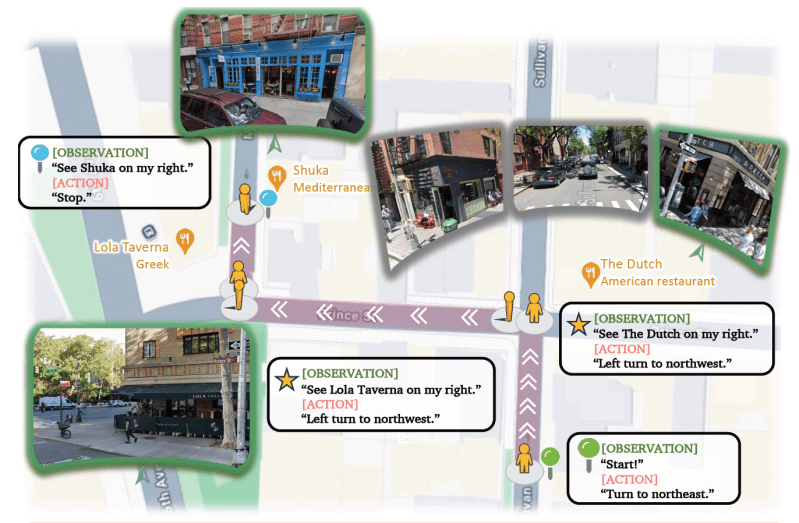
Eles realizaram seus testes no Llama-3.2-Vision-11B, aquecendo o modelo ao treiná-lo em um pequeno conjunto de dados SFT, criando versões separadas para cada tarefa e paradigma de treinamento. Para cada tarefa, eles escalaram separadamente o treinamento em RL e SFT. O processo SFT treina o modelo em soluções adicionais elaboradas manualmente, enquanto o RL permite que o modelo gere muitas soluções para cada problema, avalie os resultados e se treine nas respostas corretas.
As descobertas mostram que o aprendizado por reforço melhora consistentemente o desempenho em exemplos que são drasticamente diferentes dos dados de treinamento. Por outro lado, o SFT parece memorizar as regras de treinamento e não generaliza para exemplos fora da distribuição (OOD). Essas observações se aplicam tanto em configurações apenas de texto quanto multimodais.
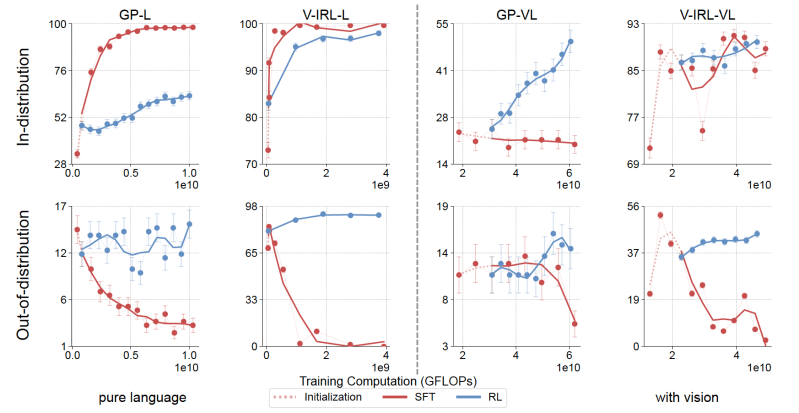
Implicações para aplicações do mundo real
Embora seus experimentos mostrem que o RL é melhor em generalização do que o SFT, os pesquisadores também descobriram que o SFT é útil para estabilizar o formato de saída do modelo e é crucial para permitir que o RL alcance seus ganhos de desempenho. Os pesquisadores descobriram que, sem a fase inicial de SFT, o treinamento de RL não obteve resultados desejáveis.
Isso é um pouco diferente dos resultados obtidos pelo DeepSeek-R1-Zero, que foi pós-treinado apenas com RL. Os pesquisadores sugerem que isso pode se dever ao modelo básico diferente que utilizaram em seus experimentos.
É claro que há muito potencial inexplorado em abordagens pesadas em RL. Para casos de uso que têm resultados verificáveis, permitir que os modelos aprendam por conta própria pode muitas vezes levar a resultados inesperados que os humanos não poderiam ter elaborado. Isso pode ser muito útil em contextos onde criar exemplos elaborados manualmente pode ser tedioso e caro.


Conteúdo relacionado

Runway, conhecida por seus modelos de IA para geração de vídeo, arrecada R$ 308 milhões.
[the_ad id="145565"] Runway, uma startup que desenvolve uma variedade de modelos de IA generativa para a produção de mídia, incluindo modelos de geração de vídeo, levantou US$…

Plataforma de IA de Voz Phonic recebe apoio da Lux
[the_ad id="145565"] A qualidade das vozes geradas por IA é suficientemente boa para criar audiolivros e podcasts, ler artigos em voz alta e oferecer suporte ao cliente básico.…

Como Claude Pensa? A Busca da Anthropic para Desvendar a Caixa-preta da IA
[the_ad id="145565"] Modelos de linguagem de grande escala (LLMs) como Claude mudaram a maneira como usamos a tecnologia. Eles alimentam ferramentas como chatbots, ajudam a…