


Todo domingo, o apresentador da NPR, Will Shortz, guru do quebra-cabeça do New York Times, tem a oportunidade de questionar milhares de ouvintes em um segmento de longa duração chamado Sunday Puzzle. Embora sejam escritos para serem resolvíveis sem muito conhecimento prévio, os enigmas geralmente são desafiadores mesmo para os competidores mais habilidosos.
Por isso, alguns especialistas acreditam que eles são uma maneira promissora de testar os limites das habilidades de resolução de problemas da IA.
Em um estudo recente, uma equipe de pesquisadores da Wellesley College, Oberlin College, da Universidade do Texas em Austin, da Northeastern University, da Charles University e da startup Cursor criou um benchmark de IA utilizando enigmas de episódios do Sunday Puzzle. A equipe afirma que seu teste revelou insights surpreendentes, como o fato de que modelos de raciocínio — incluindo o o1 da OpenAI — às vezes “desistem” e fornecem respostas que sabem que não estão corretas.
“Queríamos desenvolver um benchmark com problemas que os humanos pudessem entender com apenas conhecimento geral”, disse Arjun Guha, membro do corpo docente de ciência da computação da Northeastern e um dos co-autores do estudo, ao TechCrunch.
A indústria de IA está passando por um dilema em relação a benchmarks neste momento. A maioria dos testes comumente usados para avaliar os modelos de IA investiga habilidades, como competência em questões de matemática e ciência em nível de doutorado, que não são relevantes para o usuário comum. Enquanto isso, muitos benchmarks — até mesmo benchmarks lançados recentemente — estão rapidamente se aproximando do ponto de saturação.
As vantagens de um jogo de perguntas de rádio público como o Sunday Puzzle são que ele não testa conhecimentos esotéricos e os desafios são formulados de maneira que os modelos não possam se basear em “memória mecânica” para resolvê-los, explicou Guha.
“Eu acho que o que torna esses problemas difíceis é que é realmente complicado fazer avanços significativos em um problema até que você o resolva — é quando tudo se encaixa de uma vez”, disse Guha. “Isso requer uma combinação de insight e um processo de eliminação.”
Nenhum benchmark é perfeito, é claro. O Sunday Puzzle é centrado nos EUA e em inglês somente. E como os questionários estão disponíveis publicamente, é possível que modelos treinados com eles possam “trapacear” de certa forma, embora Guha afirme que não viu evidências disso.
“Novas perguntas são lançadas toda semana, e podemos esperar que as perguntas mais recentes sejam realmente inéditas”, acrescentou. “Pretendemos manter o benchmark atualizado e acompanhar como o desempenho do modelo muda ao longo do tempo.”
No benchmark dos pesquisadores, que consiste em cerca de 600 enigmas do Sunday Puzzle, modelos de raciocínio como o o1 e o R1 da DeepSeek superam amplamente os demais. Os modelos de raciocínio se auto-checam minuciosamente antes de fornecer resultados, o que os ajuda a evitar algumas das armadilhas que normalmente atrapalham modelos de IA. O trade-off é que modelos de raciocínio demoraram um pouco mais para chegar a soluções — tipicamente de segundos a minutos a mais.
Pelo menos um modelo, o R1 da DeepSeek, fornece soluções que sabe serem erradas para algumas das perguntas do Sunday Puzzle. O R1 declara verbatim “Eu desisto”, seguido por uma resposta incorreta escolhida aparentemente ao acaso — um comportamento que este humano certamente pode relatar.
Os modelos também tomam outras escolhas bizarras, como dar uma resposta errada apenas para imediatamente retratá-la, tentar extrair uma melhor e falhar novamente. Eles também ficam “pensando” para sempre e dão explicações sem sentido para respostas, ou chegam a uma resposta correta logo de cara, mas depois consideram respostas alternativas sem razão aparente.
“Em problemas difíceis, o R1 literalmente diz que está ficando ‘frustrado’”, disse Guha. “Foi engraçado ver como um modelo emula o que um humano poderia dizer. Resta saber como a ‘frustração’ no raciocínio pode afetar a qualidade dos resultados do modelo.”

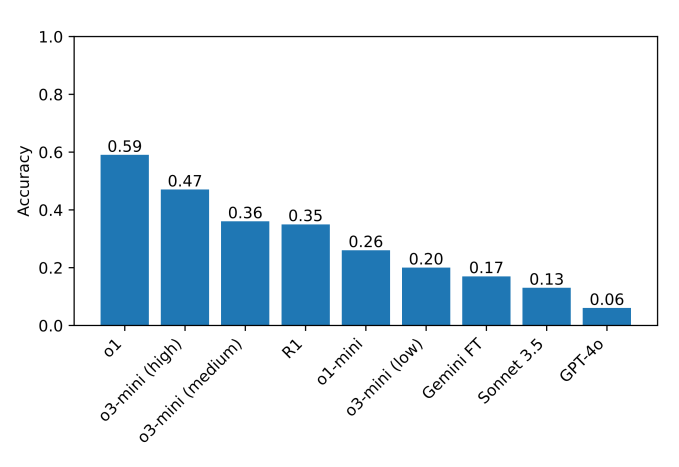
O modelo que atualmente tem o melhor desempenho no benchmark é o o1 com uma pontuação de 59%, seguido pelo o3-mini recém-lançado em “alto esforço de raciocínio” (47%). (O R1 marcou 35%.) Como próximo passo, os pesquisadores pretendem ampliar seus testes para modelos de raciocínio adicionais, o que eles esperam ajudar a identificar áreas onde esses modelos poderiam ser aprimorados.
“Você não precisa de um doutorado para ter um bom raciocínio, então deve ser possível desenhar benchmarks de raciocínio que não exigem conhecimento em nível de doutorado”, disse Guha. “Um benchmark com acesso mais amplo permite que um conjunto mais diversificado de pesquisadores compreenda e analise os resultados, o que pode, por sua vez, levar a melhores soluções no futuro. Além disso, à medida que modelos de ponta são cada vez mais implementados em cenários que afetam a todos, acreditamos que todos devem ser capazes de intuir o que esses modelos são — e não são — capazes de fazer.”

Conteúdo relacionado

Runway, conhecida por seus modelos de IA para geração de vídeo, arrecada R$ 308 milhões.
[the_ad id="145565"] Runway, uma startup que desenvolve uma variedade de modelos de IA generativa para a produção de mídia, incluindo modelos de geração de vídeo, levantou US$…

Plataforma de IA de Voz Phonic recebe apoio da Lux
[the_ad id="145565"] A qualidade das vozes geradas por IA é suficientemente boa para criar audiolivros e podcasts, ler artigos em voz alta e oferecer suporte ao cliente básico.…

Como Claude Pensa? A Busca da Anthropic para Desvendar a Caixa-preta da IA
[the_ad id="145565"] Modelos de linguagem de grande escala (LLMs) como Claude mudaram a maneira como usamos a tecnologia. Eles alimentam ferramentas como chatbots, ajudam a…