


Ainda que a manipulação profunda (deepfaking) de indivíduos privados tenha se tornado uma crescente preocupação pública e esteja progressivamente sendo proibida em diversas regiões, demonstrar que um modelo criado por usuários – como um que possibilita pornografia de vingança – foi especificamente treinado com imagens de uma pessoa em particular continua sendo uma tarefa extremamente difícil.
Para contextualizar o problema: um elemento chave de um ataque de deepfake é a afirmação falsa de que uma imagem ou vídeo retrata uma pessoa específica. Dizer simplesmente que alguém em um vídeo é a identidade #A, ao invés de um sósia, é suficiente para causar dano, e nenhuma IA é necessária nesse cenário.
No entanto, se um atacante gera imagens ou vídeos de IA usando modelos treinados com dados de pessoas reais, as redes sociais e os sistemas de reconhecimento facial dos motores de busca automaticamente associarão o conteúdo falsificado à vítima – sem a necessidade de nomes nas postagens ou metadados. Apenas os visuais gerados por IA garantem a associação.
Quanto mais distinta é a aparência da pessoa, mais inevitável isso se torna, até que o conteúdo fabricado apareça em buscas de imagem e, finalmente, alcance a vítima.
De Frente
Atualmente, a forma mais comum de disseminar modelos focados na identidade é através da Adaptação de Baixa Classificação (LoRA), onde o usuário treina um número limitado de imagens por algumas horas contra os pesos de um modelo fundamental muito maior, como a Difusão Estável (Stable Diffusion, principalmente para imagens estáticas) ou o Hunyuan Video, para deepfakes em vídeo.
Os alvos mais comuns de LoRAs, incluindo a nova geração de LoRAs baseadas em vídeo, são celebridades femininas, cuja fama as expõe a esse tipo de tratamento com menos críticas públicas do que no caso de vítimas “desconhecidas”, devido à suposição de que tais trabalhos derivados estão cobertos pelo conceito de ‘uso justo’ (pelo menos nos EUA e na Europa).
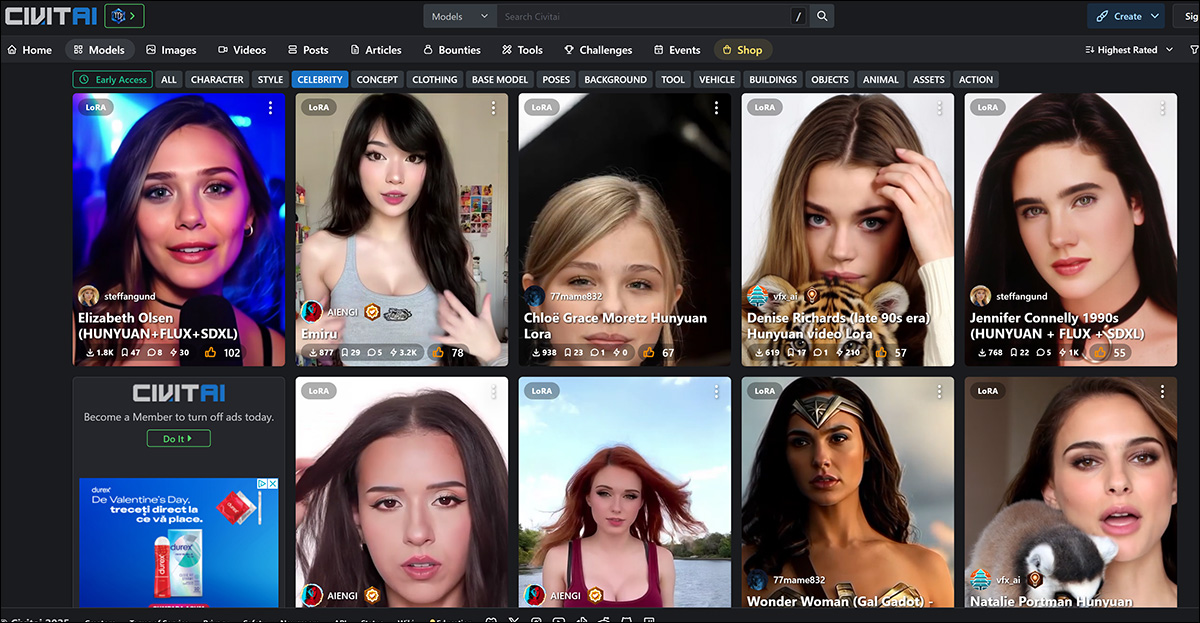
Celebridades femininas dominam as listas de LoRA e Dreambooth no portal civit.ai. A LoRA mais popular atualmente tem mais de 66.000 downloads, o que é considerável, uma vez que esse uso de IA ainda é visto como uma atividade ‘marginal’.
Não há um fórum público semelhante para as vítimas de deepfake que não são celebridades, que só surgem na mídia quando ocorrem casos de acusação, ou quando as vítimas falam em meios de comunicação populares.
No entanto, em ambos os cenários, os modelos usados para falsificar as identidades alvo ‘destilaram’ tanto seus dados de treinamento no espaço latente do modelo que se torna difícil identificar as imagens-fontes que foram usadas.
Se fosse possível fazer isso dentro de uma margem de erro aceitável, isso permitiria a acusação de aqueles que compartilham LoRAs, uma vez que não apenas provaria a intenção de deepfakear uma identidade específica (ou seja, a de uma ‘pessoa desconhecida’ específica, mesmo que o malfeitor nunca mencione seu nome durante o processo de difamação), mas também exporia o carregador a acusações de infração de direitos autorais, quando aplicável.
Isso seria útil em jurisdições onde a regulamentação legal sobre tecnologias de deepfake é carente ou está atrasada.
Superexposto
O objetivo de treinar um modelo fundamental, como o modelo base de vários gigabytes que um usuário pode baixar do Hugging Face, é que o modelo se torne bem generalizado e dúctil. Isso envolve treinar em um número adequado de imagens diversas, com as configurações apropriadas, e finalizar o treinamento antes que o modelo ‘superajuste’ aos dados.
Um modelo superajustado viu os dados tantas vezes (excessivamente) durante o processo de treinamento que tende a reproduzir imagens que são muito semelhantes, expondo assim a origem dos dados de treinamento.

A identidade ‘Ann Graham Lotz’ pode ser quase perfeitamente reproduzida no modelo Stable Diffusion V1.5. A reconstrução é quase idêntica aos dados de treinamento (à esquerda na imagem acima). Fonte: https://arxiv.org/pdf/2301.13188
No entanto, modelos superajustados geralmente são descartados por seus criadores em vez de serem distribuídos, uma vez que, de qualquer forma, não são adequados para o propósito. Portanto, essa é uma ‘oportunidade forense’ improvável. De qualquer forma, o princípio se aplica mais ao treinamento caro e em grande volume de modelos fundamentais, onde múltiplas versões da mesma imagem que se infiltraram em um enorme conjunto de dados de origem podem tornar certas imagens de treinamento fáceis de invocar (veja a imagem e exemplo acima).
A situação é um pouco diferente no caso de modelos LoRA e Dreambooth (embora o Dreambooth tenha caído em desuso devido ao tamanho grande dos arquivos). Aqui, o usuário seleciona um número muito limitado de imagens diversas de um sujeito e usa estas para treinar um LoRA.

À esquerda, saída de um LoRA de Vídeo Hunyuan. À direita, os dados que tornaram a semelhança possível (imagens usadas com permissão da pessoa representada).
Com frequência, o LoRA terá uma palavra-chave incorporada, como [nome da celebridade]. No entanto, muitas vezes o sujeito especificamente treinado aparecerá na saída gerada mesmo sem tais comandos, porque mesmo um LoRA bem equilibrado (ou seja, não superajustado) é de alguma forma ‘fixado’ no material com o qual foi treinado e tende a incluí-lo em qualquer saída.
Essa predisposição, combinada com o número limitado de imagens que são ideais para um conjunto de dados de LoRA, expõe o modelo à análise forense, como veremos.
Desmascarando os Dados
Essas questões são abordadas em um novo artigo da Dinamarca, que oferece uma metodologia para identificar imagens-fonte (ou grupos de imagens-fonte) em um Ataque de Inferência de Membros (Membership Inference Attack – MIA) em um modelo de caixa-preta. A técnica envolve, pelo menos em parte, o uso de modelos personalizados treinados que são projetados para ajudar a expor os dados-fonte gerando suas próprias ‘deepfakes’:

Exemplos de imagens ‘falsas’ geradas pela nova abordagem, em níveis cada vez mais altos de Orientação Sem Classificador (CFG), até o ponto de destruição. Fonte: https://arxiv.org/pdf/2502.11619
Embora o trabalho, intitulado Ataques de Inferência de Membros para Imagens Faciais contra Modelos de Difusão Latente Finamente Ajustados, seja uma contribuição bastante interessante à literatura sobre esse tópico em particular, também é um artigo inacessível e escrito de forma concisa que precisa de considerável decodificação. Portanto, abordaremos pelo menos os princípios básicos por trás do projeto aqui, junto com uma seleção dos resultados obtidos.
De fato, se alguém ajusta finamente um modelo de IA com a sua face, o método dos autores pode ajudar a provar isso, buscando sinais característicos de memorização nas imagens geradas pelo modelo.
Na primeira instância, um modelo de IA alvo é ajustado finamente em um conjunto de dados de imagens faciais, tornando mais provável que reproduza detalhes dessas imagens em suas saídas. Subsequentemente, um modo de ataque classificador é treinado usando imagens geradas por IA do modelo alvo como ‘positivos’ (suspeitos membros do conjunto de treinamento) e outras imagens de um conjunto de dados diferente como ‘negativos’ (não membros).
Aprendendo as sutis diferenças entre esses grupos, o modelo de ataque pode prever se uma dada imagem fez parte do conjunto de dados original de ajuste fino.
O ataque é mais eficaz em casos onde o modelo de IA foi ajustado finamente de forma extensiva, ou seja, quanto mais um modelo é especializado, mais fácil é detectar se certas imagens foram usadas. Isso geralmente se aplica a LoRAs projetados para recriar celebridades ou indivíduos privados.
Os autores também descobriram que adicionar marcas d’água visíveis às imagens de treinamento torna a detecção ainda mais fácil – embora marcas d’água ocultas não ajudem tanto.
Impressionantemente, a abordagem é testada em um ambiente de caixa-preta, significando que funciona sem acesso aos detalhes internos do modelo, apenas suas saídas.
O método desenvolvido é intensivo em computação, como os autores admitem; no entanto, o valor deste trabalho está em indicar a direção para pesquisas adicionais e provar que os dados podem ser realisticamente extraídos dentro de uma tolerância aceitável; portanto, dada sua natureza seminal, não é necessário que funcione em um smartphone neste estágio.
Método/Dados
Vários conjuntos de dados da Universidade Técnica da Dinamarca (DTU, a instituição anfitriã para os três pesquisadores do artigo) foram utilizados no estudo, para ajustar finamente o modelo alvo e para treinar e testar o modo de ataque.
Os conjuntos de dados usados foram derivados do DTU Orbit:
DseenDTU O conjunto de imagens base.
DDTU Imagens extraídas do DTU Orbit.
DseenDTU Uma partição de DDTU usada para ajustar finamente o modelo alvo.
DunseenDTU Uma partição de DDTU que não foi usada para ajustar finamente nenhum modelo de geração de imagens e foi em vez disso usada para testar ou treinar o modelo de ataque.
wmDseenDTU Uma partição de DDTU com marcas d’água visíveis usadas para ajustar finamente o modelo alvo.
hwmDseenDTU Uma partição de DDTU com marcas d’água ocultas usadas para ajustar finamente o modelo alvo.
DgenDTU Imagens geradas por um Modelo de Difusão Latente (LDM) que foi ajustado finamente no conjunto de imagens DseenDTU.
Os conjuntos de dados utilizados para ajustar finamente o modelo alvo consistem em pares de imagens-texto legendados pelo modelo de legenda BLIP (não por coincidência um dos modelos não censurados mais populares na comunidade de IA casual).
O BLIP foi configurado para adicionar à descrição a frase ‘um retrato dtu de um’.
Além disso, vários conjuntos de dados da Universidade de Aalborg (AAU) foram empregados nos testes, todos derivados do corpo AU VBN:
DAAU Imagens extraídas do AAU vbn.
DseenAAU Uma partição de DAAU usada para ajustar finamente o modelo alvo.
DunseenAAU Uma partição de DAAU que não é usada para ajustar finamente nenhum modelo de geração de imagens, mas sim para testar ou treinar o modelo de ataque.
DgenAAU Imagens geradas por um LDM ajustado finamente no conjunto de imagens DseenAAU.
Equivalente aos conjuntos anteriores, a frase ‘um retrato aau de um’ foi utilizada. Isso garantiu que todos os rótulos no conjunto de dados DTU seguissem o formato ‘um retrato dtu de um (…)’, reforçando as características centrais do conjunto de dados durante o ajuste fino.
Testes
Múltiplos experimentos foram realizados para avaliar quão bem os ataques de inferência de membros se saíram contra o modelo alvo. Cada teste tinha como objetivo determinar se era possível realizar um ataque bem-sucedido dentro do esquema mostrado abaixo, onde o modelo alvo é ajustado finamente em um conjunto de dados de imagens que foi obtido sem autorização.
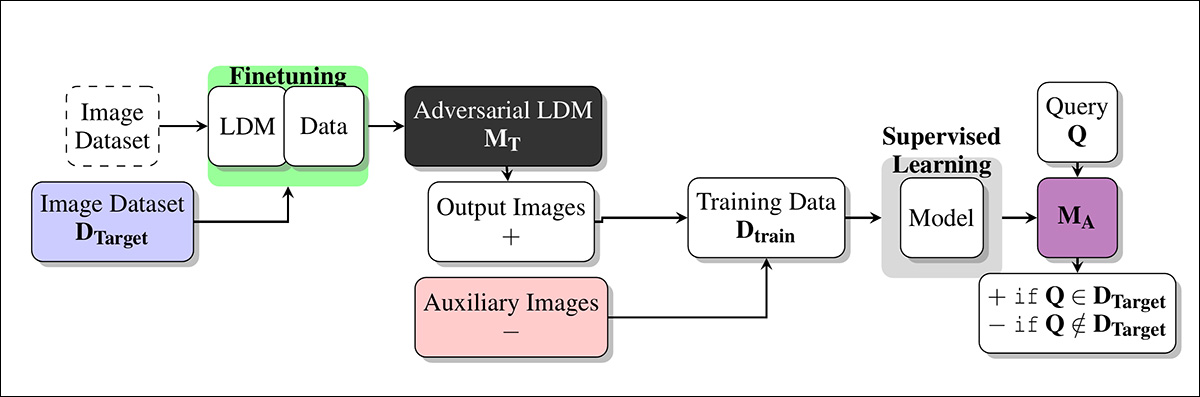
Esquema para a abordagem.
Com o modelo ajustado finamente consultado para gerar imagens de saída, essas imagens são então usadas como exemplos positivos para treinar o modelo de ataque, enquanto imagens adicionais não relacionadas são incluídas como exemplos negativos.
O modelo de ataque é treinado utilizando aprendizado supervisionado e, em seguida, testado em novas imagens para determinar se estas foram originalmente parte do conjunto de dados usado para ajustar o modelo alvo. Para avaliar a precisão do ataque, 15% dos dados de teste são reservados para validação.
Como o modelo alvo é ajustado finamente em um conjunto de dados conhecido, a verdadeira condição de membro de cada imagem já é estabelecida ao criar os dados de treinamento para o modelo de ataque. Essa configuração controlada permite uma avaliação clara de como o modelo de ataque pode diferenciar entre imagens que faziam parte do conjunto de dados de ajuste fino e aquelas que não faziam.
Para esses testes, a Difusão Estável V1.5 foi usada. Embora esse modelo antigo apareça com frequência em pesquisas devido à necessidade de testes consistentes, e ao extenso corpus de trabalhos anteriores que o utilizam, este é um caso de uso apropriado; V1.5 permaneceu popular para a criação de LoRAs na comunidade de entusiastas da Difusão Estável por muito tempo, apesar do lançamento de várias versões subsequentes e mesmo com o advento do Flux – porque o modelo é completamente não censurado.
O modelo de ataque dos pesquisadores foi baseado em Resnet-18, com os pesos pré-treinados do modelo mantidos. A última camada de 1000 neurônios do ResNet-18 foi substituída por uma camada totalmente conectada com dois neurônios. A perda de treinamento foi de entropia cruzada categórica cross-entropy, e o otimizador Adam foi usado.
Para cada teste, o modelo de ataque foi treinado cinco vezes usando diferentes sementes aleatórias para calcular intervalos de confiança de 95% para as principais métricas. A classificação zero-shot com o modelo CLIP foi usada como base.
(Por favor, observe que a tabela original de resultados primários no artigo é concisa e incomumente difícil de entender. Portanto, eu a reformulei abaixo de uma maneira mais amigável. Clique na imagem para ver em melhor resolução)
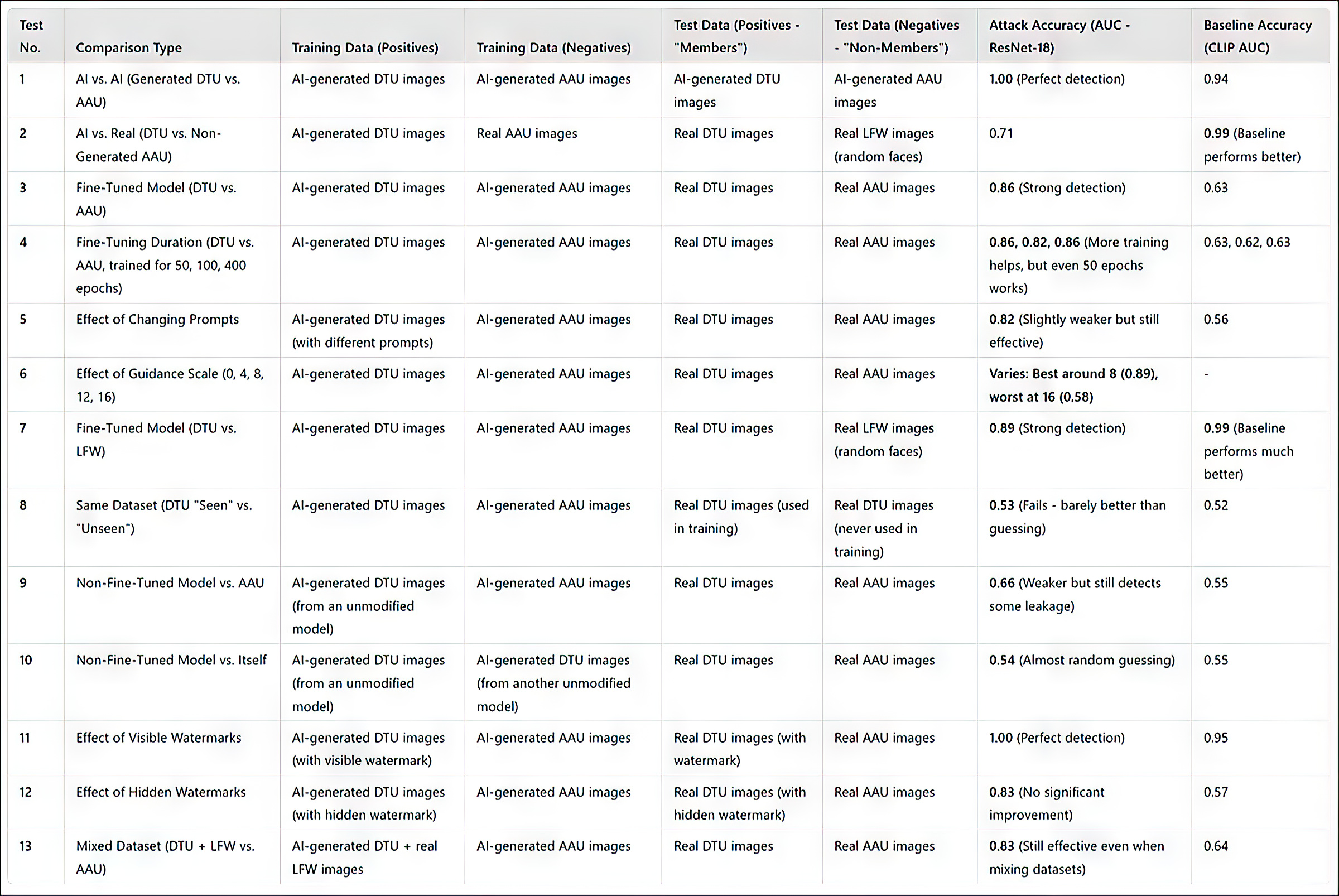
Resumo dos resultados de todos os testes. Clique na imagem para ver em maior resolução
O método de ataque dos pesquisadores provou ser mais eficaz ao direcionar modelos ajustados finamente, particularmente aqueles treinados em um conjunto específico de imagens, como a face de um indivíduo. No entanto, embora o ataque possa determinar se um conjunto de dados foi utilizado, ele tem dificuldade em identificar imagens individuais dentro desse conjunto.
Em termos práticos, este último não é necessariamente um obstáculo ao uso de uma abordagem como esta de forma forense; embora haja relativamente pouco valor em estabelecer que um conjunto de dados famoso como o ImageNet foi usado em um modelo, um atacante em um indivíduo privado (e não uma celebridade) tende a ter muito menos escolha de dados de origem e precisa explorar completamente grupos de dados disponíveis, como álbuns de mídia social e outras coleções online. Estes criam efetivamente um ‘hash’ que pode ser descoberto pelos métodos descritos.
O artigo observa que outra maneira de melhorar a precisão é usar imagens geradas por IA como ‘não membros’, em vez de depender apenas de imagens reais. Isso evita taxas de sucesso artificialmente altas que poderiam, de outra forma, enganar os resultados.
Um fator adicional que influencia significativamente a detecção, os autores notam, é a marca d’água. Quando as imagens de treinamento contêm marcas d’água visíveis, o ataque se torna altamente eficaz, enquanto marcas d’água ocultas oferecem pouco ou nenhum benefício.

A figura mais à direita mostra a marca d’água ‘oculta’ real usada nos testes.
Finalmente, o nível de orientação na geração de texto para imagem também desempenha um papel, com o equilíbrio ideal encontrado em uma escala de orientação de cerca de 8. Mesmo quando nenhum comando direto é utilizado, um modelo ajustado finamente ainda tende a produzir saídas que se assemelham aos seus dados de treinamento, reforçando a eficácia do ataque.
Conclusão
É uma pena que este artigo interessante tenha sido escrito de maneira tão inacessível, pois deveria ser de algum interesse para defensores da privacidade e pesquisadores de IA casuais.
Ainda que os ataques de inferência de membros possam acabar se revelando uma ferramenta forense interessante e frutífera, é talvez mais importante que esta linha de pesquisa desenvolva princípios amplos aplicáveis, para evitar que termine no mesmo jogo de mímica que aconteceu com a detecção de deepfake em geral, quando o lançamento de um modelo mais novo afeta negativamente a detecção e sistemas forenses similares.
Uma vez que há algumas evidências de um princípio de orientação de nível mais alto limpo nesta nova pesquisa, podemos esperar ver mais trabalhos nessa direção.
Primeira publicação na sexta-feira, 21 de fevereiro de 2025

Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…