


Embora o modelo de difusão latente (LDM) da Adobe, Firefly, seja sem dúvida um dos melhores atualmente disponíveis, usuários do Photoshop que testaram suas funcionalidades gerativas perceberão que ele não consegue facilmente editar imagens existentes – em vez disso, ele substitui completamente a área selecionada pelo usuário por imagens baseadas em um prompt textual fornecido pelo usuário (embora o Firefly tenha habilidade em integrar a seção gerada ao contexto da imagem).
Na versão beta atual, o Photoshop pode, pelo menos, incorporar uma imagem de referência como um prompt parcial de imagem, o que coloca o produto estrela da Adobe a par da funcionalidade que os usuários do Stable Diffusion já desfrutam há mais de dois anos, graças a estruturas de terceiros como Controlnet:

A versão beta atual do Adobe Photoshop permite o uso de imagens de referência ao gerar novo conteúdo dentro de uma seleção – embora no momento seja uma questão de acerto e erro.
Isso ilustra um problema aberto na pesquisa em síntese de imagens – a dificuldade que os modelos de difusão têm em editar imagens existentes sem realizar uma ‘re-imaginação’ completa da seleção indicada pelo usuário.

Embora essa pintura de preenchimento baseada em difusão obedeça ao prompt do usuário, ela reinventa completamente o assunto da imagem original sem levar a imagem original em consideração (exceto pela mesclagem da nova geração com o ambiente). Fonte: https://arxiv.org/pdf/2502.20376
Esse problema ocorre porque os LDMs geram imagens através da remoção iterativa de ruído, onde cada estágio do processo é condicionado ao prompt textual fornecido pelo usuário. Com o conteúdo do prompt textual convertido em tokens de embedding, e com um modelo de hiperscale como o Stable Diffusion ou Flux contendo centenas de milhares (ou milhões) de embeddings quase correspondentes ao prompt, o processo tem uma distribuição condicional a que se destina; e cada etapa dada é um passo em direção a esse ‘alvo de distribuição condicional’.
Então, isso é texto para imagem – um cenário onde o usuário ‘espera pelo melhor’, já que não se pode prever exatamente como será a geração.
Em vez disso, muitos têm buscado usar a poderosa capacidade gerativa de um LDM para editar imagens existentes – mas isso envolve um ato de equilíbrio entre fidelidade e flexibilidade.
Quando uma imagem é projetada no espaço latente do modelo por métodos como inversão DDIM, o objetivo é recuperar a original o mais próximo possível, permitindo ao mesmo tempo edições significativas. O problema é que quanto mais precisamente a imagem é reconstruída, mais o modelo adere a sua estrutura original, tornando modificações significativas difíceis.

Assim como outras estruturas de edição de imagem baseadas em difusão propostas nos últimos anos, a arquitetura Renoise tem dificuldade em fazer mudanças reais na aparência da imagem, apresentando apenas uma indicação superficial de uma gravata no fundo do pescoço do gato.
Por outro lado, se o processo prioriza a editabilidade, o modelo solta seu controle sobre o original, facilitando a introdução de mudanças – mas à custa da consistência geral com a imagem fonte:

Missão cumprida – mas é uma transformação em vez de um ajuste, para a maioria das estruturas de edição de imagens baseadas em IA.
Considerando que é um problema que até os consideráveis recursos da Adobe estão lutando para resolver, podemos razoavelmente considerar que o desafio é notável e pode não permitir soluções fáceis, se houver.
Inversão Apertada
Portanto, os exemplos de um novo artigo publicado esta semana chamaram minha atenção, pois o trabalho oferece uma melhoria valiosa e digna de nota sobre o estado da arte atual nesta área, provando ser capaz de aplicar edições sutis e refinadas a imagens projetadas no espaço latente de um modelo – sem que as edições sejam insignificantes ou domine o conteúdo original na imagem fonte:

Com a Inversão Apertada aplicada a métodos de inversão existentes, a seleção fonte é considerada de maneira muito mais granular, e as transformações se conformam ao material original em vez de sobrepujá-los.
Os entusiastas e praticantes de LDM podem reconhecer esse tipo de resultado, já que grande parte disso pode ser criada em um fluxo de trabalho complexo utilizando sistemas externos como Controlnet e IP-Adapter.
Na verdade, o novo método – denominado Inversão Apertada – aproveita, de fato, o IP-Adapter, junto com um modelo baseado em rosto dedicado, para representações humanas.
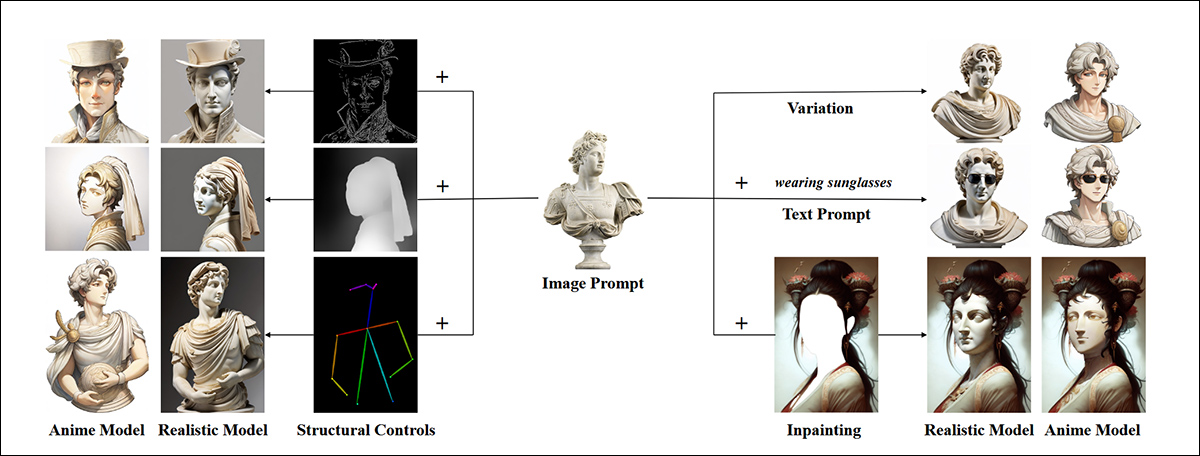
Do artigo original do IP-Adapter de 2023, exemplos de edições apropriadas ao material fonte. Fonte: https://arxiv.org/pdf/2308.06721
A conquista sinalizada pela Inversão Apertada, então, é ter proceduralizado técnicas complexas em um único modo de plug-in que pode ser aplicado a sistemas existentes, incluindo muitas das distribuições LDM mais populares.
Naturalmente, isso significa que a Inversão Apertada (TI), assim como os sistemas adjuntos dos quais se aproveita, utiliza a imagem fonte como um fator de condicionamento para sua própria versão editada, em vez de depender exclusivamente de prompts textuais precisos:

Mais exemplos da capacidade da Inversão Apertada de aplicar edições verdadeiramente integradas ao material fonte.
Embora os autores reconheçam que sua abordagem não está livre da tensão tradicional e contínua entre fidelidade e editabilidade nas técnicas de edição de imagens baseadas em difusão, eles relatam resultados de estado da arte ao injetar TI em sistemas existentes, em comparação com o desempenho de referência.
O novo trabalho é intitulado Inversão Apertada: Inversão Condicionada por Imagem para Edição Real de Imagens, e é obra de cinco pesquisadores da Universidade de Tel Aviv e da Snap Research.
Método
Inicialmente, um Modelo de Linguagem Grande (LLM) é usado para gerar um conjunto de prompts textuais variados a partir dos quais uma imagem é gerada. Em seguida, a mencionada inversão DDIM é aplicada a cada imagem com três condições textuais: o prompt textual usado para gerar a imagem; uma versão abreviada da mesma; e um prompt nulo (vazio).
Com o ruído invertido retornado desses processos, as imagens são novamente regeneradas com a mesma condição, e sem orientação livre de classificador (CFG).
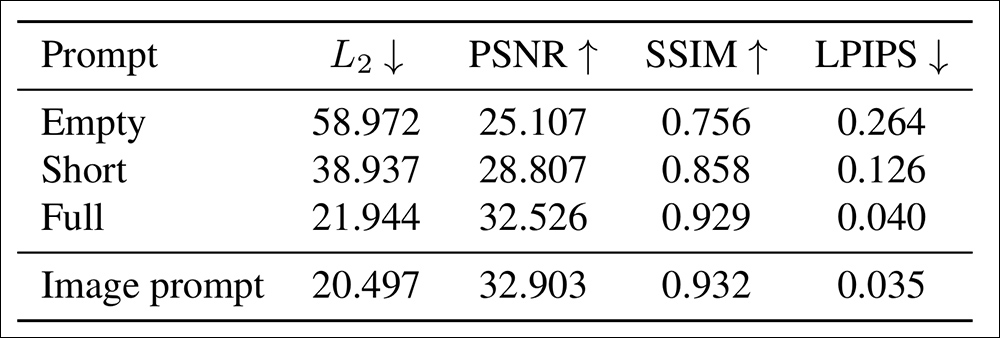
Pontuações de inversão DDIM em várias métricas com diferentes configurações de prompt.
Como podemos ver no gráfico acima, as pontuações em várias métricas melhoraram com o aumento do comprimento do texto. As métricas utilizadas foram Relação Sinal-Ruído de Pico (PSNR); distância L2; Índice de Similaridade Estrutural (SSIM); e Similaridade de Patches de Imagem Perceptual Aprendida (LPIPS).
Consciente da Imagem
Efetivamente, a Inversão Apertada muda como um modelo de difusão anfitrião edita imagens reais, condicionando o processo de inversão na própria imagem em vez de confiar apenas no texto.
Normalmente, inverter uma imagem no espaço de ruído de um modelo de difusão requer estimar o ruído inicial que, quando desdenizado, reconstrói a entrada. Métodos padrão usam um prompt textual para guiar esse processo; mas um prompt imperfeito pode levar a erros, perdendo detalhes ou alterando estruturas.
A Inversão Apertada, em vez disso, usa o Adapter de IP para fornecer informações visuais ao modelo, para que ele reconstrua a imagem com maior precisão, convertendo as imagens fontes em tokens de condicionamento e projetando-as no pipeline de inversão.
Esses parâmetros são editáveis: aumentar a influência da imagem fonte torna a reconstrução quase perfeita, enquanto reduzi-la permite que mudanças mais criativas sejam introduzidas. Isso torna a Inversão Apertada útil tanto para modificações sutis, como mudar a cor de uma camisa, quanto para edições mais significativas, como trocar objetos – sem os comuns efeitos colaterais de outros métodos de inversão, como a perda de detalhes finos ou aberrações inesperadas no conteúdo do fundo.
Os autores afirmam:
‘Observamos que a Inversão Apertada pode ser facilmente integrada a métodos de inversão anteriores (por exemplo, Edit Friendly DDPM, ReNoise) ao [substituir o núcleo nativo de difusão pelo modelo alterado do IP Adapter], e [a Inversão Apertada melhora consistentemente esses métodos em termos de reconstrução e editabilidade.’
Dados e Testes
Os pesquisadores avaliaram a TI quanto à sua capacidade de reconstruir e editar imagens fonte do mundo real. Todos os experimentos utilizaram Stable Diffusion XL com um scheduler DDIM, conforme descrito no artigo original do Stable Diffusion; e todos os testes utilizaram 50 etapas de desnoiser à uma escala de orientação padrão de 7,5.
Para condicionamento de imagem, IP-Adapter-plus sdxl vit-h foi usado. Para testes de poucos passos, os pesquisadores usaram SDXL-Turbo com um scheduler Euler, e também realizaram experimentos com FLUX.1-dev, condicionando o modelo neste último caso com PuLID-Flux, utilizando RF-Inversion em 28 etapas.
PulID foi usado exclusivamente em casos que apresentavam rostos humanos, uma vez que este é o domínio que o PulID foi treinado para abordar – e embora seja notável que um subsistema especializado seja utilizado para esse tipo de prompt específico, nosso enorme interesse em gerar rostos humanos sugere que depender exclusivamente dos pesos mais amplos de um modelo básico como Stable Diffusion pode não ser adequado aos padrões que exigimos para esta tarefa específica.
Testes de reconstrução foram realizados para avaliação qualitativa e quantitativa. Na imagem abaixo, vemos exemplos qualitativos para a inversão DDIM:

Resultados qualitativos para inversão DDIM. Cada linha mostra uma imagem altamente detalhada junto a suas versões reconstruídas, com cada etapa usando condições progressivamente mais precisas durante a inversão e desnoisamento. À medida que a condicionamento se torna mais precisa, a qualidade da reconstrução melhora. A coluna mais à direita demonstra os melhores resultados, onde a imagem original é usada como condição, alcançando a maior fidelidade. CFG não foi utilizado em nenhuma etapa. Consulte o documento fonte para melhor resolução e detalhe.
O artigo afirma:
‘Esses exemplos destacam que condicionar o processo de inversão em uma imagem melhora significativamente a reconstrução em regiões altamente detalhadas.
‘Notavelmente, no terceiro exemplo [da imagem abaixo], nosso método reconstrói com sucesso a tatuagem nas costas do boxeador à direita. Além disso, a pose da perna do boxeador é preservada com mais precisão e a tatuagem na perna se torna visível.’

Mais resultados qualitativos para a inversão DDIM. Condições descritivas melhoram a inversão DDIM, com condicionamento de imagem superando texto, especialmente em imagens complexas.
Os autores também testaram a Inversão Apertada como um módulo embutido para sistemas existentes, comparando as versões modificadas com seu desempenho de referência.
Os três sistemas testados foram a mencionada Inversão DDIM, RF-Inversion; e também ReNoise, que compartilha parte da autoria com o artigo que discutimos aqui. Uma vez que os resultados DDIM não têm dificuldade em alcançar uma reconstrução de 100%, os pesquisadores se concentraram apenas na editabilidade.
(As imagens de resultados qualitativos estão formatadas de maneira que é difícil reproduzir aqui, então nos referimos o leitor ao PDF fonte para uma cobertura mais completa e melhor resolução, não obstante algumas seleções serem apresentadas abaixo)

À esquerda, resultados qualitativos de reconstrução para a Inversão Apertada com SDXL. À direita, reconstrução com Flux. O layout desses resultados no trabalho publicado torna difícil reproduzir aqui, então consulte o PDF fonte para uma verdadeira impressão das diferenças obtidas.
Aqui os autores comentam:
‘Como ilustrado, integrar a Inversão Apertada com métodos existentes melhora consistentemente a reconstrução. Por [exemplo,] nosso método reconstrói com precisão o corrimão no exemplo mais à esquerda e o homem com a camisa azul no exemplo mais à direita [na figura 5 do artigo].’
Os autores também testaram o sistema quantitativamente. Em linha com trabalhos anteriores, utilizaram o conjunto de validação de MS-COCO, e observam que os resultados (ilustrados abaixo) melhoraram a reconstrução em todas as métricas para todos os métodos.
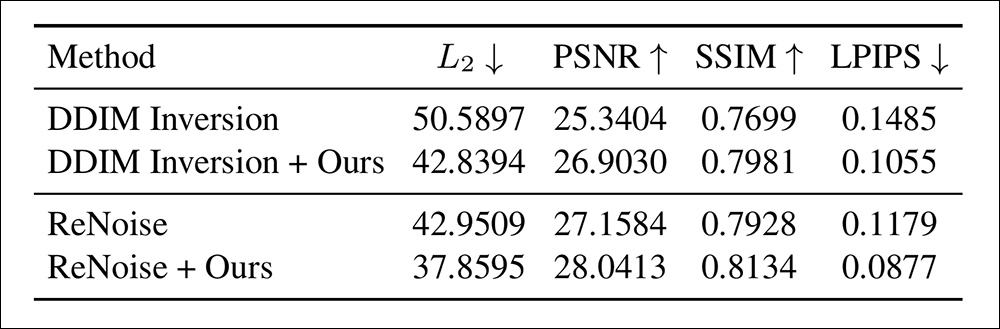
Comparando as métricas de desempenho dos sistemas com e sem a Inversão Apertada.
Em seguida, os autores testaram a capacidade do sistema de editar fotos, comparando-o com versões base de abordagens anteriores prompt2prompt; Edit Friendly DDPM; LED-ITS++; e RF-Inversion.
Mostramos abaixo uma seleção dos resultados qualitativos do artigo para SDXL e Flux (e referimos ao leitor a disposição um tanto comprimida do artigo original para mais exemplos).

Seleções dos resultados qualitativos espalhados (de maneira confusa) ao longo do artigo. Referimos o leitor ao PDF fonte para resolução melhorada e clareza significativa.
Os autores afirmam que a Inversão Apertada supera consistentemente as técnicas de inversão existentes, alcançando um melhor equilíbrio entre reconstrução e editabilidade. Métodos padrão como inversão DDIM e ReNoise podem recuperar bem uma imagem, mas o artigo afirma que eles frequentemente lutam para preservar detalhes finos ao se aplicarem edições.
Por outro lado, a Inversão Apertada aproveita o condicionamento da imagem para ancorar a saída do modelo mais próximo do original, evitando distorções indesejadas. Os autores afirmam que mesmo quando abordagens concorrentes produzem reconstruções que aparentemente são precisas, a introdução de edições muitas vezes leva a artefatos ou inconsistências estruturais, e que a Inversão Apertada mitiga esses problemas.
Finalmente, resultados quantitativos foram obtidos ao avaliar a Inversão Apertada contra o benchmark MagicBrush, usando inversão DDIM e LEDITS++, medidos pelo CLIP Sim.
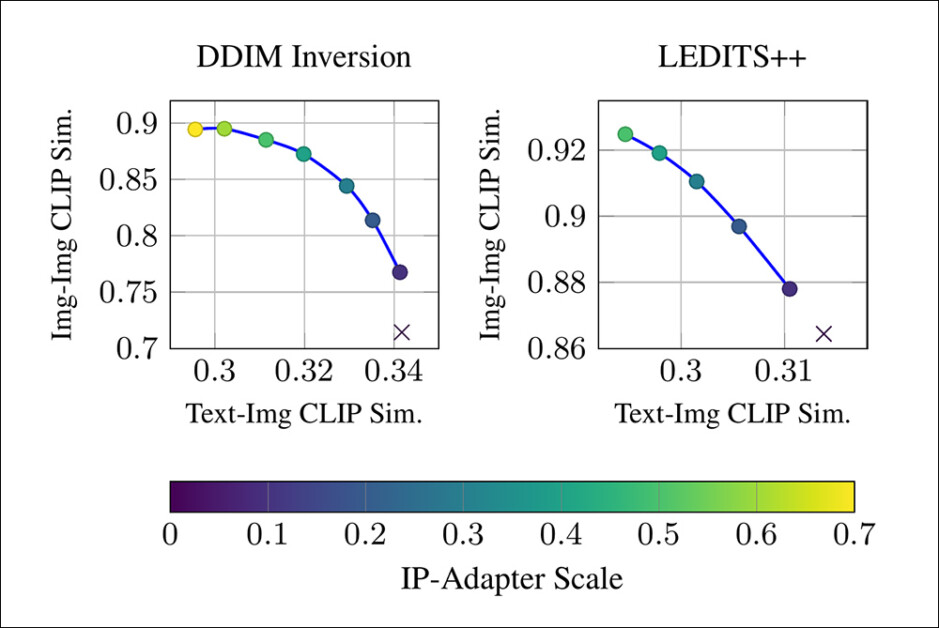
Comparações quantitativas da Inversão Apertada contra o benchmark MagicBrush.
Os autores concluem:
‘Em ambos os gráficos, a troca entre preservação da imagem e aderência à edição alvo é claramente observada. A Inversão Apertada fornece melhor controle sobre essa troca e preserva melhor a imagem de entrada enquanto ainda se alinha com a edição [do prompt].
‘Note que uma similaridade CLIP superior a 0.3 entre uma imagem e um prompt textual indica uma possível aderência entre a imagem e o prompt.’
Conclusão
Embora não represente um ‘avanço’ em um dos desafios mais espinhosos na síntese de imagem baseada em LDM, a Inversão Apertada consolida uma série de abordagens auxiliares penosas em um método unificado de edição de imagens baseado em IA.
Ainda que a tensão entre editabilidade e fidelidade não tenha desaparecido sob este método, ela é notavelmente reduzida, de acordo com os resultados apresentados. Considerando que o desafio central que este trabalho aborda pode revelar-se, em última instância, intratável se tratado em seus próprios termos (em vez de considerar futuras arquiteturas além dos LDMs), a Inversão Apertada representa uma melhoria incremental bem-vinda no estado da arte.
Publicada pela primeira vez na sexta-feira, 28 de fevereiro de 2025

Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…