


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder no setor. Saiba Mais
O mais recente modelo de IA de código aberto da Google, o Gemma 3, não é a única grande novidade da subsidiária da Alphabet hoje.
Na verdade, o foco pode ter sido roubado pelo Gemini 2.0 Flash da Google com geração de imagem nativa, um novo modelo experimental disponível gratuitamente para usuários do Google AI Studio e para desenvolvedores através da API Gemini da Google.
Este é o primeiro caso em que uma grande empresa de tecnologia dos EUA lançou geração de imagem multimodal diretamente dentro de um modelo para consumidores. A maioria das outras ferramentas de geração de imagem de IA eram modelos de difusão (específicos para imagem) conectados a grandes modelos de linguagem (LLMs), exigindo uma interpretação entre dois modelos para derivar uma imagem a partir de um prompt de texto solicitado pelo usuário.
Em contraste, o Gemini 2.0 Flash pode gerar imagens nativamente dentro do mesmo modelo em que o usuário digita os prompts de texto, permitindo teoricamente uma maior precisão e mais capacidades — e as indicações iniciais são que isso é totalmente verdadeiro.
O Gemini 2.0 Flash, apresentado pela primeira vez em dezembro de 2024, mas sem a capacidade de geração de imagem nativa ativada para os usuários, integra entrada multimodal, raciocínio e compreensão de linguagem natural para gerar imagens junto com texto.
A nova versão experimental, gemini-2.0-flash-exp, permite que desenvolvedores criem ilustrações, aperfeiçoem imagens através de conversas e gerem visuais detalhados com base em conhecimentos do mundo.
Como o Gemini 2.0 Flash aprimora as imagens geradas por IA
Em um post de blog voltado para desenvolvedores publicado hoje mais cedo, a Google destaca várias capacidades chave da geração de imagem nativa do Gemini 2.0 Flash:
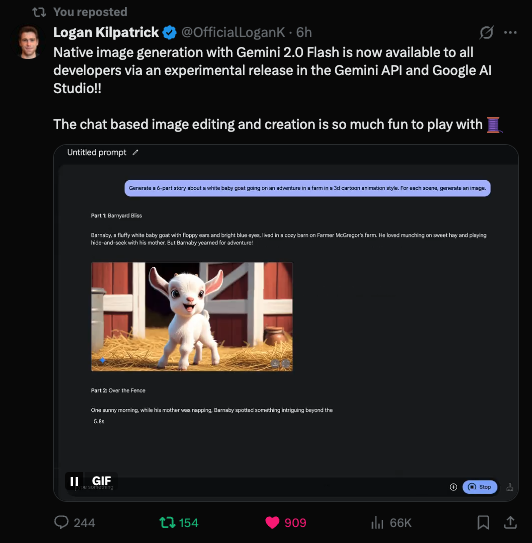
• Contação de histórias com texto e imagem: Os desenvolvedores podem usar o Gemini 2.0 Flash para gerar histórias ilustradas mantendo a consistência em personagens e cenários. O modelo também responde ao feedback, permitindo que os usuários ajustem a história ou mudem o estilo artístico.
• Edição de imagem conversacional: A IA suporta edições em várias etapas, o que significa que os usuários podem refiná-la iterativamente fornecendo instruções através de prompts em linguagem natural. Este recurso possibilita colaboração em tempo real e exploração criativa.
• Geração de imagem baseada em conhecimento do mundo: Ao contrário de muitos outros modelos de geração de imagem, o Gemini 2.0 Flash aproveita capacidades de raciocínio mais amplas para produzir imagens mais contextualmente relevantes. Por exemplo, ele pode ilustrar receitas com visuais detalhados que se alinham aos ingredientes e métodos de cozinhar do mundo real.
• Renderização de texto aprimorada: Muitos modelos de imagem de IA lutam para gerar texto legível dentro de imagens, muitas vezes produzindo erros de ortografia ou caracteres distorcidos. A Google relata que o Gemini 2.0 Flash supera os principais concorrentes em renderização de texto, tornando-o particularmente útil para anúncios, postagens em redes sociais e convites.
Exemplos iniciais mostram um potencial incrível e promissor
Funcionários da Google e alguns usuários avançados de IA foram ao X compartilhar exemplos das novas capacidades de geração e edição de imagem oferecidas pelo Gemini 2.0 Flash Experimental, e eles eram, sem dúvida, impressionantes.
O pesquisador da Google DeepMind, Robert Riachi, demonstrou como o modelo pode gerar imagens em um estilo pixel-art e, em seguida, criar novas na mesma estética com base em prompts de texto.
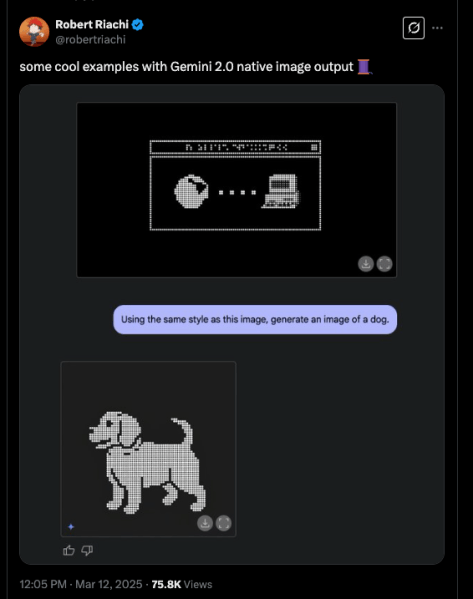
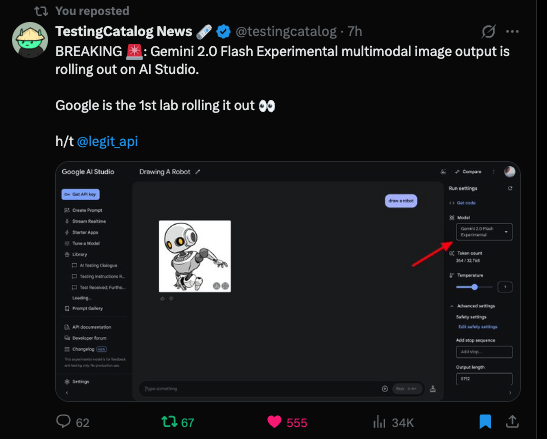
A conta de notícias de IA, TestingCatalog News relatou sobre a implementação das capacidades multimodais do Gemini 2.0 Flash Experimental, observando que a Google é o primeiro grande laboratório a implantar esse recurso.
O usuário @Angaisb_ conhecido como “Angel” mostrou em um exemplo convincente como um prompt para “adicionar cobertura de chocolate” modificou uma imagem existente de croissants em segundos — revelando as capacidades rápidas e precisas de edição de imagem do Gemini 2.0 Flash ao simplesmente conversar com o modelo.

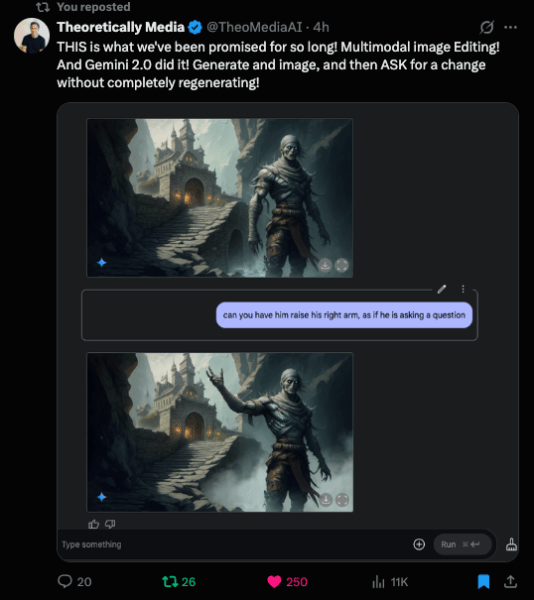
O YouTuber Theory Media apontou que esta edição incremental de imagem sem regeneração completa é algo que a indústria de IA aguardava há muito tempo, demonstrando como foi fácil pedir ao Gemini 2.0 Flash para editar uma imagem para levantar o braço de um personagem enquanto preservava toda a referência da imagem.
O ex-Googler e atual YouTuber de IA, Bilawal Sidhu mostrou como o modelo coloriza imagens em preto e branco, sugerindo potencial para aplicações de restauração histórica ou aprimoramento criativo.
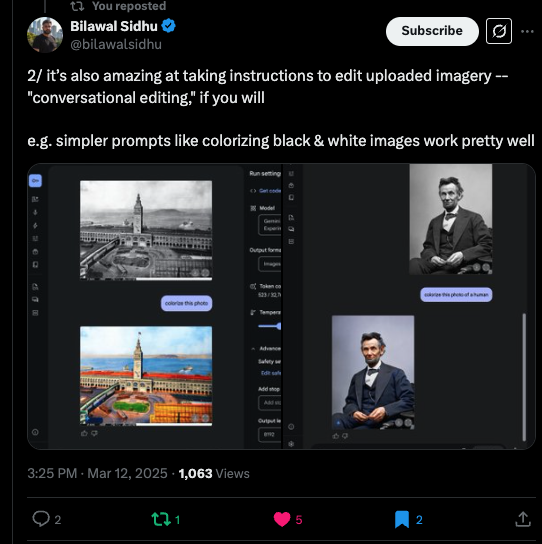
Essas reações iniciais sugerem que desenvolvedores e entusiastas da IA veem o Gemini 2.0 Flash como uma ferramenta altamente flexível para design iterativo, contação de histórias criativas e edição visual assistida por IA.
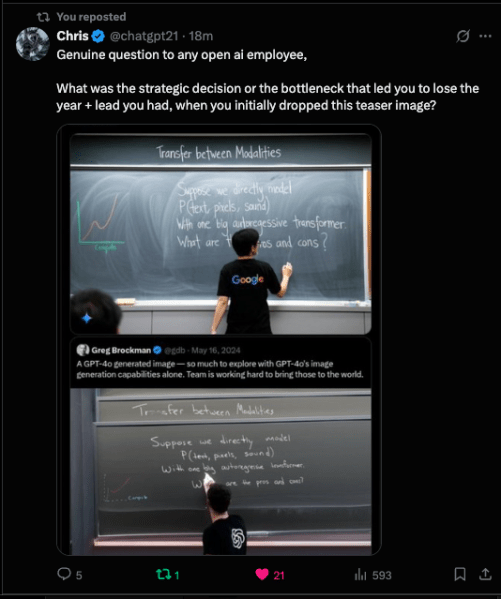
A rápida implementação também contrasta com o GPT-4o da OpenAI, que revelou capacidades de geração de imagem nativa em maio de 2024 — quase um ano atrás — mas ainda não lançou o recurso publicamente, permitindo que a Google aproveite uma oportunidade para liderar na implantação de IA multimodal.
Como o usuário @chatgpt21 conhecido como “Chris” apontou no X, a OpenAI, neste caso, “perdeu o ano + liderança” que tinha nessa capacidade por razões desconhecidas. O usuário convidou qualquer um da OpenAI a comentar sobre o motivo.
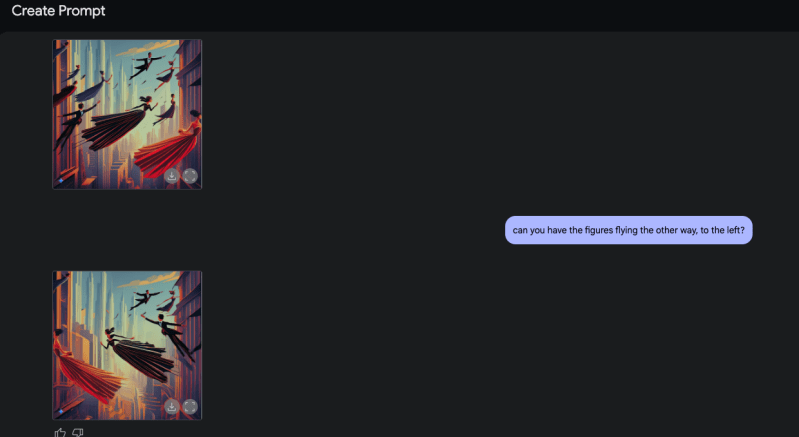
Meus próprios testes revelaram algumas limitações com a proporção da imagem — parecia presa em 1:1 para mim, apesar de pedir em texto para modificar — mas conseguiu mudar a direção dos personagens em uma imagem em questão de segundos.
Embora grande parte da discussão inicial em torno da geração de imagem nativa do Gemini 2.0 Flash tenha se concentrado em usuários individuais e aplicações criativas, suas implicações para equipes de empresas, desenvolvedores e arquitetos de software são significativas.
Design e Marketing Potencializados por IA em Escala: Para equipes de marketing e criadores de conteúdo, o Gemini 2.0 Flash poderia servir como uma alternativa econômica aos fluxos de trabalho tradicionais de design gráfico, automatizando a criação de conteúdo de marca, anúncios e visuais para redes sociais. Visto que suporta a renderização de texto dentro de imagens, poderia simplificar a criação de anúncios, design de embalagens e gráficos promocionais, reduzindo a dependência de edições manuais.
Ferramentas de Desenvolvedor Aprimoradas e Fluxos de Trabalho de IA: Para CTOs, CIOs e engenheiros de software, a geração de imagem nativa poderia simplificar a integração da IA em aplicações e serviços. Combinando saídas de texto e imagem em um único modelo, o Gemini 2.0 Flash permite que os desenvolvedores construam:
- Assistentes de design alimentados por IA que gerem mockups de UI/UX ou ativos de aplicativos.
- Ferramentas de documentação automatizadas que ilustrem conceitos em tempo real.
- Plataformas de contação de histórias dinâmicas impulsionadas por IA para mídia e educação.
Como o modelo também suporta edição de imagem conversacional, as equipes poderiam desenvolver interfaces guiadas por IA onde os usuários refinam designs através de diálogo natural, reduzindo a barreira de entrada para usuários não técnicos.
Novas Possibilidades para Software de Produtividade Impulsionado por IA: Para equipes empresariais que constroem ferramentas de produtividade alimentadas por IA, o Gemini 2.0 Flash poderia suportar aplicações como:
- Geração automatizada de apresentações com slides e visuais criados por IA.
- Anotações de documentos legais e empresariais com infográficos gerados por IA.
- Visualização de e-commerce, gerando dinamicamente mockups de produtos baseados em descrições.
Como implantar e experimentar com esta capacidade
Os desenvolvedores podem começar a testar as capacidades de geração de imagem do Gemini 2.0 Flash usando a API Gemini. A Google fornece um exemplo de solicitação de API para demonstrar como os desenvolvedores podem gerar histórias ilustradas com texto e imagens em uma única resposta:
from google import genai
from google.genai import types
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash-exp",
contents=(
"Gere uma história sobre uma tartaruga bebê fofa em um estilo de arte digital 3D. "
"Para cada cena, gere uma imagem."
),
config=types.GenerateContentConfig(
response_modalities=["Text", "Image"]
),
)Ao simplificar a geração de imagens alimentadas por IA, o Gemini 2.0 Flash oferece aos desenvolvedores novas formas de criar conteúdo ilustrado, projetar aplicações assistidas por IA e experimentar com contação de histórias visuais.


Conteúdo relacionado

Uma linha do tempo do mercado de semicondutores dos EUA em 2025
[the_ad id="145565"] Já foi um ano tumultuado para a indústria de semicondutores dos EUA. A indústria de semicondutores desempenha um papel significativo na "corrida da IA" que…

Zencoder lança Zen Agents, inaugurando uma nova era de IA em equipe para o desenvolvimento de software.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre coberturas líderes do setor em IA. Saiba mais…

SoundCloud altera políticas para permitir treinamento de IA com conteúdo dos usuários.
[the_ad id="145565"] O SoundCloud aparentemente mudou silenciosamente seus termos de uso para permitir que a empresa treine IA com o áudio que os usuários enviam para sua…