


Um novo artigo publicado esta semana no Arxiv aborda uma questão que todos que adotaram os geradores de vídeo Hunyuan Video ou Wan 2.1 já devem ter enfrentado: aberrações temporais, onde o processo gerador tende a acelerar abruptamente, confundir, omitir ou de outra forma comprometer momentos cruciais em um vídeo gerado:
Clique para reproduzir. Alguns dos glitches temporais que estão se tornando familiares para os usuários da nova onda de sistemas de vídeo generativo, destacados no novo artigo. À direita, o efeito ameliorador da nova abordagem FluxFlow. Fonte: https://haroldchen19.github.io/FluxFlow/
O vídeo acima apresenta trechos de vídeos de teste exemplares (cuidado: bastante caóticos) no site do projeto relacionado ao artigo. Podemos ver vários problemas cada vez mais familiares sendo remediados pelo método dos autores (mostrado à direita no vídeo), que é efetivamente uma técnica de pré-processamento de dataset aplicável a qualquer arquitetura de vídeo generativa.
No primeiro exemplo, apresentando ‘duas crianças brincando com uma bola’, gerado pelo CogVideoX, observamos (à esquerda na compilação do vídeo acima e no exemplo específico abaixo) que a geração nativa rapidamente salta por vários micro-movimentos essenciais, acelerando a atividade das crianças até um nível ‘cartunesco’. Em contraste, o mesmo dataset e método produzem resultados melhores com a nova técnica de pré-processamento, chamada FluxFlow (à direita da imagem no vídeo abaixo):
Clique para reproduzir.
No segundo exemplo (utilizando NOVA-0.6B), vemos que um movimento central envolvendo um gato foi de alguma forma corrompido ou subamostrado significativamente na fase de treinamento, ao ponto de o sistema gerador ficar ‘paralisado’ e incapaz de fazer o sujeito se mover:
Clique para reproduzir.
Esse sintoma, onde o movimento ou o sujeito fica ‘preso’, é um dos problemas mais frequentemente relatados do HV e Wan, nos diversos grupos de síntese de imagem e vídeo.
Alguns desses problemas estão relacionados às questões de legendagem de vídeo no dataset original que analisamos esta semana; mas os autores do novo trabalho se concentram nas qualidades temporais dos dados de treinamento, e apresentam um argumento convincente de que abordar os desafios a partir dessa perspectiva pode gerar resultados úteis.
Como mencionado no artigo anterior sobre legendagem de vídeo, certos esportes são particularmente difíceis de destilar em momentos-chave, significando que eventos críticos (como um slam-dunk) não recebem a atenção necessária na hora do treinamento:
Clique para reproduzir.
No exemplo acima, o sistema gerador não sabe como avançar para a próxima fase de movimento e transita ilogicamente de uma pose para outra, mudando a atitude e a geometria do jogador no processo.
Esses são grandes movimentos que se perderam no treinamento – mas igualmente vulneráveis são movimentos muito menores, mas fundamentais, como o batimento das asas de uma borboleta:
Clique para reproduzir.
Ao contrário do slam-dunk, o batimento das asas não é um evento ‘raro’, mas sim persistente e monótono. Contudo, sua consistência se perde no processo de amostragem, uma vez que o movimento é tão rápido que é muito difícil estabelecê-lo temporalmente.
Esses não são problemas particularmente novos, mas estão recebendo mais atenção agora que poderosos modelos de vídeo generativo estão disponíveis para entusiastas para instalação local e geração gratuita.
As comunidades no Reddit e no Discord inicialmente trataram essas questões como ‘relacionadas ao usuário’. Essa é uma presunção compreensível, uma vez que os sistemas em questão são muito novos e minimamente documentados. Portanto, diversos comentaristas sugeriram remédios diversos (e nem sempre eficazes) para alguns dos glitches aqui documentados, como alterar as configurações em vários componentes de diversos tipos de fluxos de trabalho do ComfyUI para Hunyuan Video (HV) e Wan 2.1.
Em alguns casos, ao invés de produzir movimento rápido, tanto o HV quanto o Wan produzem movimento lento. Sugestões do Reddit e do ChatGPT (que se baseia principalmente no Reddit) incluem mudar o número de quadros na geração solicitada ou reduzir radicalmente a taxa de quadros*.
Isso tudo é questão desesperadora; a verdade emergente é que ainda não sabemos a causa exata ou o remédio exato para esses problemas; claramente, atormentar as configurações de geração para contorná-los (particularmente quando isso degrada a qualidade da saída, por exemplo, com uma taxa de fps muito baixa) é apenas um paliativo, e é bom ver que a pesquisa está abordando questões emergentes tão rapidamente.
Portanto, além desta análise desta semana de como a legendagem afeta o treinamento, vamos dar uma olhada no novo artigo sobre regularização temporal e quais melhorias ele pode oferecer à atual cena de vídeo generativo.
A ideia central é bastante simples e sutil, e nada pior por isso; no entanto, o artigo está um tanto folgado para atingir as oito páginas prescritas, e pularemos esse preenchimento conforme necessário.

O peixe na geração nativa da estrutura VideoCrafter é estático, enquanto a versão alterada pelo FluxFlow captura as mudanças necessárias. Source: https://arxiv.org/pdf/2503.15417
O novo trabalho é intitulado A Regularização Temporal Torna Seu Gerador de Vídeo Mais Forte, e vem de oito pesquisadores da Everlyn AI, da Universidade de Ciência e Tecnologia de Hong Kong (HKUST), da Universidade Central da Flórida (UCF) e da Universidade de Hong Kong (HKU).
(no momento da redação, há alguns problemas com o site do projeto que acompanha o artigo)
FluxFlow
A ideia central por trás de FluxFlow, o novo esquema de pré-treinamento dos autores, é superar os problemas generalizados de flickering e inconsistência temporal embaralhando blocos e grupos de blocos na ordem dos quadros temporais enquanto os dados são expostos ao processo de treinamento:
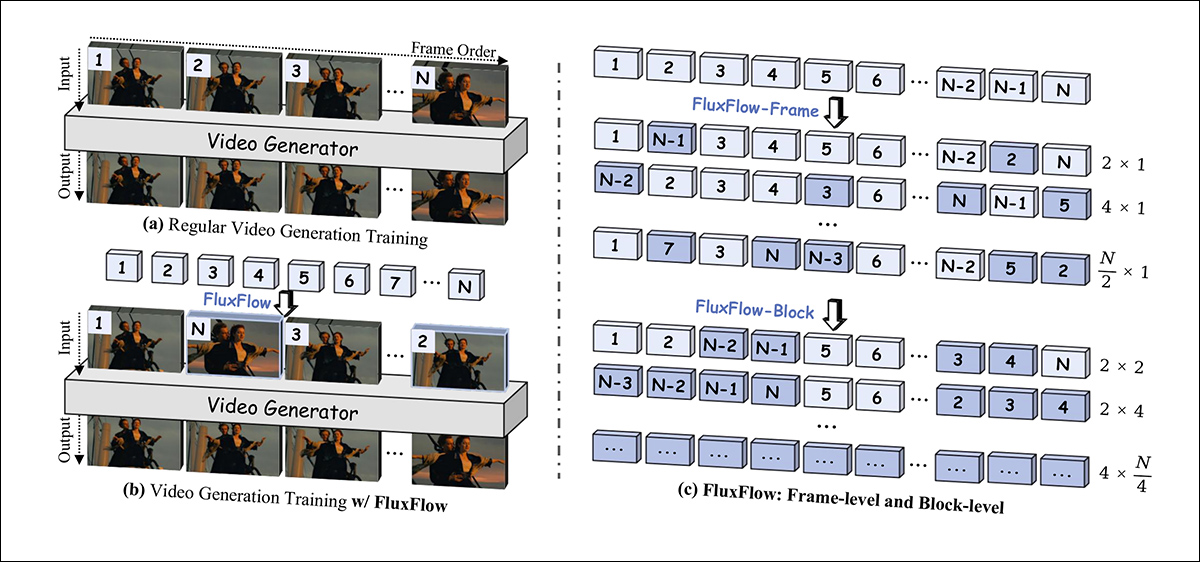
A ideia central por trás do FluxFlow é mover blocos e grupos de blocos para posições inesperadas e não temporais, como uma forma de aumento de dados.
O artigo explica:
‘[Artefatos] decorrem de uma limitação fundamental: apesar de aproveitar datasets em larga escala, os modelos atuais muitas vezes dependem de padrões temporais simplificados nos dados de treinamento (ex.: direções de caminhada fixas ou transições de quadros repetitivas) em vez de aprender dinâmicas temporais diversas e plausíveis.’
‘Esse problema é ainda mais agravado pela falta de aumento temporal explícito durante o treinamento, deixando os modelos propensos a se ajustarem demais a correlações temporais espúrias (ex.: “o quadro #5 deve seguir o #4”) em vez de generalizar em diversos cenários de movimento.’
A maioria dos modelos de geração de vídeo, explicam os autores, ainda se baseia demais na síntese de imagem, focando na fidelidade espacial enquanto ignora amplamente o eixo temporal. Embora técnicas como recorte, inversão e alteração de cor tenham ajudado a melhorar a qualidade da imagem estática, elas não são soluções adequadas quando aplicadas a vídeos, onde a ilusão de movimento depende de transições consistentes entre quadros.
Os problemas resultantes incluem texturas piscando, cortes abruptos entre quadros e padrões de movimento repetitivos ou excessivamente simplificados.
Clique para reproduzir.
O artigo argumenta que, embora alguns modelos – incluindo Stable Video Diffusion e LlamaGen – compensem com arquiteturas cada vez mais complexas ou restrições projetadas, isso vem a um custo em termos de computação e flexibilidade.
Uma vez que a ampliação de dados temporais já provou ser útil em tarefas de compreensão de vídeo (em frameworks como FineCliper, SeFAR e SVFormer), é surpreendente, afirmam os autores, que essa tática raramente seja aplicada em um contexto generativo.
Comportamento Disruptivo
Os pesquisadores sustentam que perturbações estruturadas e simples na ordem temporal durante o treinamento ajudam os modelos a generalizar melhor a movimentos diversos e realistas:
‘Treinando em sequências desordenadas, o gerador aprende a recuperar trajetórias plausíveis, regularizando efetivamente a entropia temporal. FLUXFLOW preenche a lacuna entre a ampliação temporal discriminativa e generativa, oferecendo uma solução de melhoria ‘plug-and-play’ para a geração de vídeo temporariamente plausível enquanto melhora a [qualidade] geral.’
‘Diferente de métodos existentes que introduzem mudanças arquitetônicas ou dependem de pós-processamento, FLUXFLOW opera diretamente no nível dos dados, introduzindo perturbações temporais controladas durante o treinamento.’
Clique para reproduzir.
As perturbações em nível de quadro, afirmam os autores, introduzem interrupções finas dentro de uma sequência. Esse tipo de interrupção não é muito diferente da ampliação de máscara, onde seções de dados são aleatoriamente bloqueadas, para evitar que o sistema se ajuste demais a pontos de dados, incentivando melhor generalização.
Testes
Embora a ideia central aqui não se estenda a um artigo de comprimento total, devido à sua simplicidade, há, no entanto, uma seção de testes que podemos analisar.
Os autores testaram quatro questões relacionadas à melhoria da qualidade temporal enquanto mantêm a fidelidade espacial; capacidade de aprender dinâmicas de movimento/fluxo óptico; manutenção da qualidade temporal na geração extraterrestre; e sensibilidade a hiperparâmetros chave.
Os pesquisadores aplicaram o FluxFlow a três arquiteturas generativas: com base em U-Net, na forma de VideoCrafter2; com base em DiT, na forma de CogVideoX-2B; e com base em AR, na forma de NOVA-0.6B.
Para uma comparação justa, eles ajustaram os modelos base das arquiteturas com o FluxFlow como uma fase adicional de treinamento, por uma época, no dataset OpenVidHD-0.4M.
Os modelos foram avaliados em relação a dois benchmarks populares: UCF-101; e VBench.
Para o UCF, as métricas de Fréchet Video Distance (FVD) e Inception Score (IS) foram usadas. Para o VBench, os pesquisadores concentraram-se na qualidade temporal, qualidade quadro a quadro e qualidade geral.
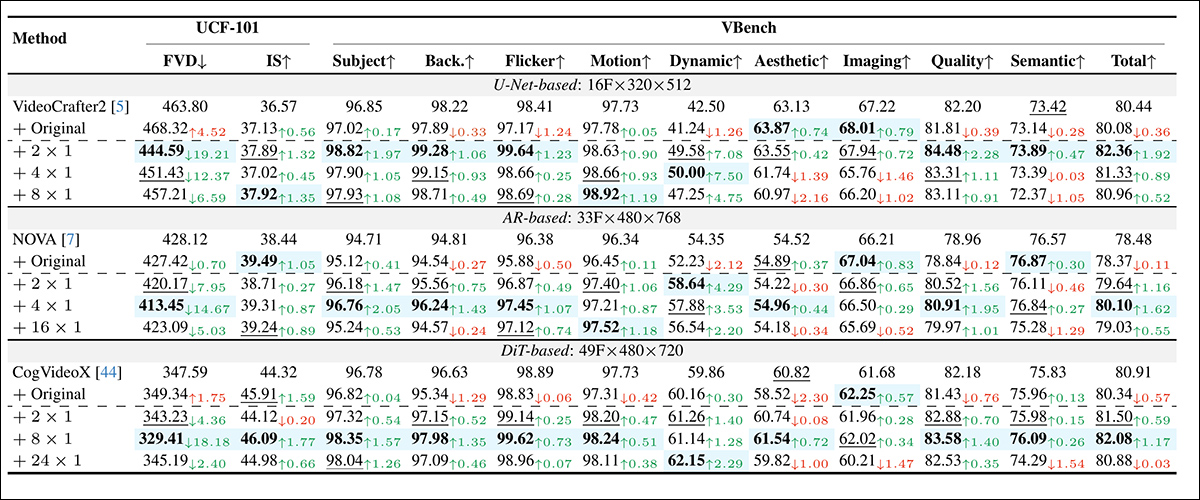
Avaliação inicial quantitativa do FluxFlow-Frame. “+ Original” indica treinamento sem FLUXFLOW, enquanto “+ Num × 1” mostra diferentes configurações do FluxFlow-Frame. Os melhores resultados estão sombreados; os segundos melhores estão sublinhados para cada modelo.
Comentando esses resultados, os autores afirmam:
‘Tanto o FLUXFLOW-FRAME quanto o FLUXFLOW-BLOCK melhoram significativamente a qualidade temporal, como evidenciado pelas métricas nas Tabelas 1 e 2 (ou seja, FVD, Sujeito, Flicker, Movimento e Dinâmico) e pelos resultados qualitativos na [imagem abaixo].
‘Por exemplo, o movimento do carro à deriva no VC2, o gato perseguindo o rabo no NOVA, e o surfista pegando uma onda no CVX tornam-se notavelmente mais fluidos com o FLUXFLOW. Importante, essas melhorias temporais são alcançadas sem sacrificar a fidelidade espacial, como evidenciado pelos detalhes nítidos de respingos de água, trilhas de fumaça e texturas de ondas, junto com métricas de fidelidade espacial e geral.’
Abaixo vemos seleções dos resultados qualitativos a que os autores se referem (por favor, consulte o artigo original para resultados completos e melhor resolução):

Seleções dos resultados qualitativos.
O artigo sugere que, embora tanto as perturbações em nível de quadro quanto em nível de bloco melhorem a qualidade temporal, os métodos em nível de quadro tendem a ter desempenho melhor. Isso é atribuído à sua granularidade mais fina, que permite ajustes temporais mais precisos. Por outro lado, as perturbações em nível de bloco podem introduzir ruído devido a padrões espaciais e temporais intimamente acoplados dentro dos blocos, reduzindo sua eficácia.
Conclusão
Este artigo, juntamente com a colaboração de legendagem Bytedance-Tsinghua lançada esta semana, deixou claro para mim que as aparentes deficiências na nova geração de modelos de vídeo generativos podem não resultar de erro do usuário, falhas institucionais ou limitações de financiamento, mas sim de um foco de pesquisa que, compreensivelmente, priorizou desafios mais urgentes, como coerência e consistência temporal, em detrimento dessas preocupações menores.
Até recentemente, os resultados dos sistemas de vídeo generativos disponíveis gratuitamente e para download estavam tão comprometidos que nenhum grande esforço surgiu da comunidade entusiasta para corrigir as questões (não menos porque os problemas eram fundamentais e não trivialmente solucionáveis).
Agora que estamos tão mais próximos da era tão aguardada de vídeos fotorrealistas gerados puramente por IA, é claro que tanto as comunidades de pesquisa quanto as casuais estão tomando um interesse mais profundo e produtivo em resolver as questões restantes; com sorte, esses não são obstáculos intransponíveis.
* A taxa de quadros nativa do Wan é de apenas 16fps, e como resposta às minhas próprias questões, notei que fóruns sugeriram baixar a taxa de quadros para tão baixo quanto 12fps e então usar FlowFrames ou outros sistemas de re-fluxo baseados em IA para interpolar as lacunas entre um número tão escasso de quadros.
Publicada pela primeira vez na sexta-feira, 21 de março de 2025

Conteúdo relacionado

A Microsoft está explorando uma forma de recompensar colaboradores de dados para treinamento de IA.
[the_ad id="145565"] A Microsoft está lançando um projeto de pesquisa para estimar a influência de exemplos de treinamento específicos sobre o texto, imagens e outros tipos de…

CEO da Wayve compartilha seus ingredientes essenciais para escalar a tecnologia de condução autônoma
[the_ad id="145565"] O co-fundador e CEO da Wayve, Alex Kendall, vê potencial em trazer a tecnologia de sua startup de veículos autônomos ao mercado. Isso, é claro, se a Wayve…

A Nvidia acredita que a IA pode resolver problemas da rede elétrica causados pela IA.
[the_ad id="145565"] A Nvidia anunciou na quinta-feira que está formando uma parceria com a EPRI, uma organização de P&D da indústria elétrica, para utilizar a IA na resolução…