


Participe de nossas newsletters diárias e semanais para receber as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder do setor. Saiba mais
Um novo artigo de pesquisadores do Google Research e da Universidade da Califórnia, Berkeley demonstra que uma abordagem surpreendentemente simples de escalonamento em tempo de teste pode aumentar as habilidades de raciocínio de grandes modelos de linguagem (LLMs). O segredo? Aumentar a pesquisa baseada em amostragem, uma técnica que depende da geração de múltiplas respostas e da verificação dessas respostas pelo próprio modelo.
A descoberta central é que até mesmo uma implementação minimalista da pesquisa baseada em amostragem, utilizando amostragem aleatória e auto-verificação, pode elevar o desempenho de raciocínio de modelos como Gemini 1.5 Pro além do o1-Preview em benchmarks populares. Essas descobertas podem ter implicações importantes para aplicações empresariais e desafiar a suposição de que um treinamento altamente especializado ou arquiteturas complexas são sempre necessárias para alcançar um desempenho de alto nível.
Os limites do atual escalonamento de computação em tempo de teste
O método popular atual para escalonamento em tempo de teste em LLMs é treinar o modelo por meio de aprendizado por reforço para gerar respostas mais longas com rastros de cadeia de pensamento (CoT). Essa abordagem é utilizada em modelos como o OpenAI o1 e DeepSeek-R1. Embora benéficas, essas metodologias geralmente requerem um investimento substancial na fase de treinamento.
Outro método de escalonamento em tempo de teste é a “auto-consistência”, onde o modelo gera múltiplas respostas à consulta e escolhe a que aparece com mais frequência. A auto-consistência encontra seus limites ao lidar com problemas complexos, pois nesses casos, a resposta mais repetida não é necessariamente a correta.
A pesquisa baseada em amostragem oferece uma alternativa mais simples e altamente escalável ao escalonamento em tempo de teste: deixar o modelo gerar múltiplas respostas e selecionar a melhor por meio de um mecanismo de verificação. A pesquisa baseada em amostragem pode complementar outras estratégias de escalonamento de computação em tempo de teste e, como os pesquisadores escrevem em seu artigo, “também possui a vantagem única de ser embaraçosamente paralela e permitir escalonamento arbitrário: basta amostrar mais respostas.”
Mais importante ainda, a pesquisa baseada em amostragem pode ser aplicada a qualquer LLM, incluindo aqueles que não foram explicitamente treinados para raciocínio.
Como a pesquisa baseada em amostragem funciona
Os pesquisadores focam em uma implementação minimalista da pesquisa baseada em amostragem, utilizando um modelo de linguagem para gerar tanto as respostas candidatas quanto para verificá-las. Este é um processo de “auto-verificação”, onde o modelo avalia suas próprias saídas sem depender de respostas verdadeiras externas ou sistemas de verificação simbólica.
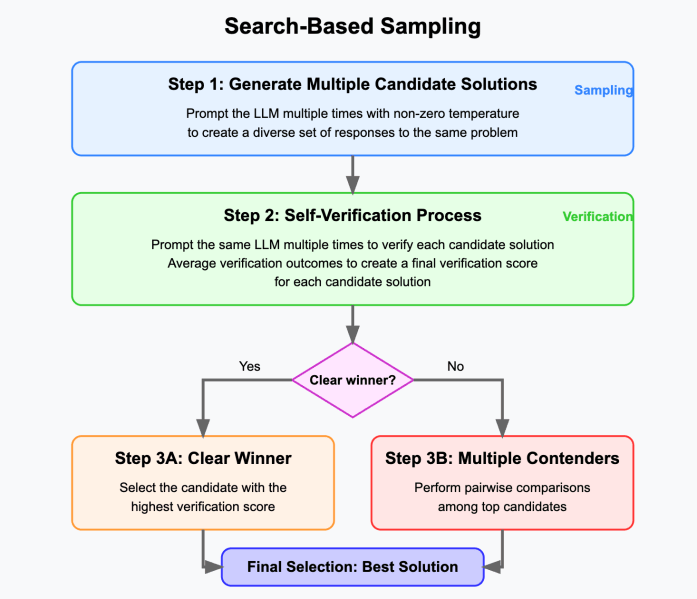
O algoritmo funciona em algumas etapas simples:
1—O algoritmo começa gerando um conjunto de soluções candidatas para o problema dado usando um modelo de linguagem. Isso é feito ao fornecer ao modelo o mesmo prompt várias vezes e usando uma configuração de temperatura diferente de zero para criar um conjunto diversificado de respostas.
2—Cada resposta candidata passa por um processo de verificação no qual o LLM é solicitado várias vezes para determinar se a resposta está correta. Os resultados das verificações são então médios para criar uma pontuação de verificação final para a resposta.
3— O algoritmo seleciona a resposta com a maior pontuação como a resposta final. Se várias candidatas estiverem próximas uma da outra, o LLM é solicitado a compará-las em pares e escolher a melhor. A resposta que vencer mais comparações em pares é escolhida como a resposta final.
Os pesquisadores consideraram dois eixos principais para o escalonamento em tempo de teste:
Amostragem: O número de respostas que o modelo gera para cada problema de entrada.
Verificação: O número de pontuações de verificação computadas para cada solução gerada.
Como a pesquisa baseada em amostragem se compara a outras técnicas
O estudo revelou que o desempenho de raciocínio continua a melhorar com a pesquisa baseada em amostragem, mesmo quando o cálculo em tempo de teste é escalado muito além do ponto em que a auto-consistência se satura.
Em uma escala suficiente, esta implementação minimalista aumenta significativamente a precisão do raciocínio em benchmarks como AIME e MATH. Por exemplo, o desempenho do Gemini 1.5 Pro superou o do o1-Preview, que foi explicitamente treinado em problemas de raciocínio, e o Gemini 1.5 Flash superou o Gemini 1.5 Pro.
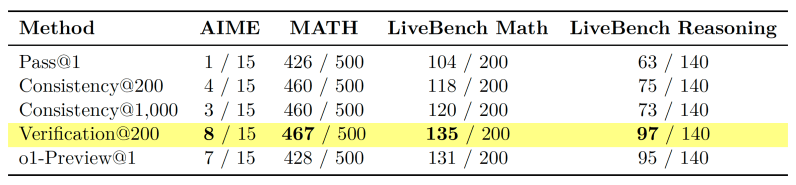
“Isto não só destaca a importância da pesquisa baseada em amostragem para capacidade de escalonamento, mas também sugere a utilidade da pesquisa baseada em amostragem como uma linha de base simples na qual comparar outras estratégias de escalonamento de computação em tempo de teste e medir melhorias genuínas nas capacidades de busca dos modelos,” escrevem os pesquisadores.
Vale a pena notar que, embora os resultados da amostragem baseada em pesquisa sejam impressionantes, os custos também podem se tornar proibitivos. Por exemplo, com 200 amostras e 50 etapas de verificação por amostra, uma consulta do AIME gerará cerca de 130 milhões de tokens, o que custa $650 com o Gemini 1.5 Pro. No entanto, essa é uma abordagem muito minimalista para a pesquisa baseada em amostragem, e é compatível com técnicas de otimização propostas em outros estudos. Com métodos de amostragem e verificação mais inteligentes, os custos de inferência podem ser reduzidos consideravelmente usando modelos menores e gerando menos tokens. Por exemplo, ao usar o Gemini 1.5 Flash para realizar a verificação, os custos caem para $12 por pergunta.
Estratégias eficazes de auto-verificação
Há um debate em andamento sobre se os LLMs podem verificar suas próprias respostas. Os pesquisadores identificaram duas estratégias principais para melhorar a auto-verificação usando computação em tempo de teste:
Comparação direta entre candidatos de resposta: Desacordos entre soluções candidatas indicam fortemente potenciais erros. Ao fornecer ao verificador múltiplas respostas para comparar, o modelo pode identificar melhor erros e alucinações, abordando uma fraqueza central dos LLMs. Os pesquisadores descrevem isso como um exemplo de “escalonamento implícito.”
Reescrita específica da tarefa: Os pesquisadores propõem que o estilo de saída ideal de um LLM depende da tarefa. A cadeia de pensamento é eficaz para resolver tarefas de raciocínio, mas as respostas são mais fáceis de verificar quando escritas em um estilo mais formal e convencional, matematicamente. Os verificadores podem reescrever respostas candidatas em um formato mais estruturado (por exemplo, teorema-lei-prova) antes da avaliação.
“Antecipamos que as capacidades de auto-verificação do modelo melhoram rapidamente no curto prazo, à medida que os modelos aprendem a aproveitar os princípios de escalonamento implícito e adequação do estilo de saída, e impulsionam taxas de escalonamento melhoradas para a pesquisa baseada em amostragem,” escrevem os pesquisadores.
Implicações para aplicações do mundo real
O estudo demonstra que uma técnica relativamente simples pode alcançar resultados impressionantes, potencialmente reduzindo a necessidade de arquiteturas de modelos complexas e onerosas ou regimes de treinamento.
Esta é também uma técnica escalável, permitindo que empresas aumentem o desempenho alocando mais recursos de computação para amostragem e verificação. Isso também permite que desenvolvedores ampliem modelos de linguagem de ponta além de suas limitações em tarefas complexas.
“Considerando que complementa outras estratégias de escalonamento de computação em tempo de teste, é paralelizável e permite escalonamento arbitrário, além de admitir implementações simples que são demonstravelmente eficazes, esperamos que a pesquisa baseada em amostragem desempenhe um papel crucial à medida que os modelos de linguagem são encarregados de resolver problemas cada vez mais complexos com orçamentos de computação cada vez maiores,” escrevem os pesquisadores.


Conteúdo relacionado

AllTrails lança assinatura de $80/ano que inclui rotas inteligentes com tecnologia de IA.
[the_ad id="145565"] AllTrails, o companheiro de caminhadas e ciclismo nomeado como o App do Ano para iPhone de 2023, está lançando uma nova assinatura premium chamada “Peak”,…

Melhorias nos modelos de IA de ‘raciocínio’ podem desacelerar em breve, aponta análise.
[the_ad id="145565"] Uma análise da Epoch AI, um instituto de pesquisa em IA sem fins lucrativos, sugere que a indústria de IA pode não conseguir obter grandes ganhos de…

Co-fundador da Anthropic, Jared Kaplan, virá ao TechCrunch Sessions: AI
[the_ad id="145565"] Está com vontade de aprender mais sobre a Anthropic diretamente da fonte? Você não está sozinho, e é por isso que estamos animados em anunciar que Jared…