


A OpenAI está lançando novos modelos de IA para transcrição e geração de voz em sua API, que a empresa afirma serem melhorias em relação às versões anteriores.
Para a OpenAI, os modelos se encaixam em sua visão mais ampla de “agentes”: construir sistemas automatizados que podem realizar tarefas de forma independente em nome dos usuários. A definição de “agente” pode ser debatida, mas Olivier Godement, Head de Produto da OpenAI, descreveu uma interpretação como um chatbot que pode conversar com os clientes de um negócio.
“Veremos mais e mais agentes surgirem nos próximos meses”, disse Godement ao TechCrunch durante um briefing. “E o tema geral é ajudar clientes e desenvolvedores a aproveitar agentes que sejam úteis, disponíveis e precisos.”
A OpenAI afirma que seu novo modelo de texto para fala, “gpt-4o-mini-tts”, não só proporciona uma fala mais nuançada e realista, como também é mais “direcionável” do que os modelos de síntese de fala da geração anterior. Os desenvolvedores podem instruir o gpt-4o-mini-tts sobre como dizer as coisas em linguagem natural — por exemplo, “fale como um cientista maluco” ou “use uma voz serena, como um professor de mindfulness.”
Aqui está uma voz “estilo true crime”, desgastada:
E aqui está um exemplo de uma voz “profissional” feminina:
Jeff Harris, um membro da equipe de produtos da OpenAI, disse ao TechCrunch que o objetivo é permitir que os desenvolvedores personalizem tanto a “experiência” quanto o “contexto” da voz.
“Em diferentes contextos, você não quer apenas uma voz plana e monótona”, disse Harris. “Se você está em uma experiência de suporte ao cliente e quer que a voz seja apologética porque cometeu um erro, você pode ter a voz com essa emoção… Nossa grande crença aqui é que desenvolvedores e usuários realmente querem controlar não apenas o que é falado, mas como as coisas são ditas.”
Quanto aos novos modelos de fala para texto da OpenAI, “gpt-4o-transcribe” e “gpt-4o-mini-transcribe”, eles efetivamente substituem o modelo de transcrição Whisper, que já estava desatualizado. Treinados em “conjuntos de dados de áudio diversos e de alta qualidade”, os novos modelos podem capturar melhor a fala acentuada e variada, afirma a OpenAI, mesmo em ambientes caóticos.
Eles também são menos propensos a alucinações, acrescentou Harris. O Whisper notoriamente tendia a fabricar palavras — e até mesmo passagens inteiras — nas conversas, introduzindo tudo, desde comentários raciais até tratamentos médicos imaginários nas transcrições.
“[T]esses modelos estão muito melhorados em comparação com o Whisper nesse aspecto,” disse Harris. “Garantir que os modelos sejam precisos é completamente essencial para obter uma experiência de voz confiável, e preciso [neste contexto] significa que os modelos estão ouvindo as palavras precisamente [e] não estão preenchendo detalhes que não ouviram.”
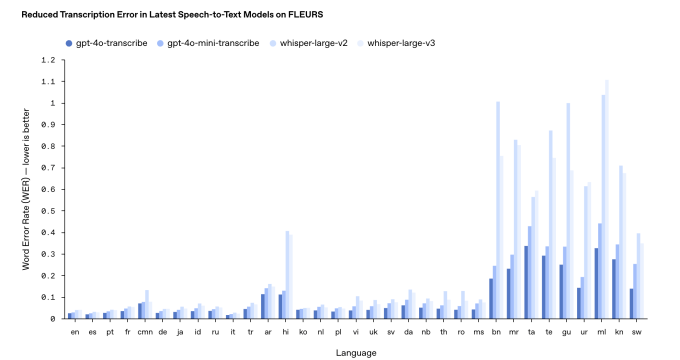
Entretanto, sua eficácia pode variar dependendo do idioma que está sendo transcrito.
De acordo com os benchmarks internos da OpenAI, o gpt-4o-transcribe, o mais preciso dos dois modelos de transcrição, tem uma “taxa de erro de palavras” que se aproxima de 30% (de 120%) para idiomas Indic e Dravídicos, como Tamil, Telugu, Malayalam e Kannada. Isso significa que três em cada dez palavras desse modelo diferirão de uma transcrição humana nesses idiomas.
Em uma ruptura com a tradição, a OpenAI não planeja tornar seus novos modelos de transcrição disponíveis abertamente. A empresa historicamente lançou novas versões do Whisper para uso comercial sob uma licença MIT.
Harris afirmou que gpt-4o-transcribe e gpt-4o-mini-transcribe são “muito maiores que o Whisper” e, portanto, não são boas opções para um lançamento aberto.
“[T]eles não são o tipo de modelo que você pode simplesmente executar localmente no seu laptop, como o Whisper”, continuou. “[N]ós queremos ter certeza de que, se estivermos lançando coisas como código aberto, estamos fazendo isso de forma reflexiva e temos um modelo que esteja realmente aprimorado para essa necessidade específica. E achamos que dispositivos de usuário final são um dos casos mais interessantes para modelos de código aberto.”
Atualizado em 20 de março de 2025, às 11h54 PT para esclarecer a linguagem sobre a taxa de erro de palavras e atualizar o gráfico de resultados de benchmarks com uma versão mais recente.

Conteúdo relacionado

O debate sobre IA de código aberto: Por que a transparência seletiva constitui um sério risco
Participe de nossos boletins diários e semanais para receber as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder na…

A Anthropic parece estar utilizando o Brave para impulsionar a busca na web para seu chatbot Claude.
No início desta semana, a Anthropic lançou um recurso de busca na web para sua plataforma de chatbot alimentada por IA, Claude, trazendo o bot em…

DeepSeek: Tudo o que você precisa saber sobre o aplicativo de chatbot de IA
DeepSeek se tornou viral. O laboratório de IA chinês DeepSeek ganhou destaque esta semana após seu aplicativo de chatbot chegar ao topo das paradas da…