


À medida que as técnicas convencionais de avaliação de IA se mostram inadequadas, os desenvolvedores de IA estão recorrendo a maneiras mais criativas de avaliar as capacidades dos modelos de IA generativa. Para um grupo de desenvolvedores, isso significa Minecraft, o jogo de construção em sandbox da Microsoft.
O site Minecraft Benchmark (ou MC-Bench) foi desenvolvido colaborativamente para colocar modelos de IA uns contra os outros em desafios lado a lado, respondendo a solicitações com criações no Minecraft. Os usuários podem votar em qual modelo fez um trabalho melhor, e somente após a votação podem ver qual IA fez cada construção no Minecraft.

Para Adi Singh, o aluno do 12º ano que iniciou o MC-Bench, o valor do Minecraft não está tanto no jogo em si, mas na familiaridade que as pessoas têm com ele — afinal, é o jogo de vídeo mais vendido de todos os tempos. Mesmo para aqueles que nunca jogaram, ainda é possível avaliar qual representação pixelada de um abacaxi é melhor realizada.
“O Minecraft permite que as pessoas vejam o progresso [do desenvolvimento da IA] de forma muito mais clara,” disse Singh ao TechCrunch. “As pessoas estão acostumadas com o Minecraft, com a aparência e a atmosfera do jogo.”
Atualmente, o MC-Bench lista oito pessoas como colaboradores voluntários. Anthropic, Google, OpenAI e Alibaba subsidiaram o uso de seus produtos para executar solicitações de benchmark, segundo o site do MC-Bench, mas as empresas não estão de outra forma afiliadas.
“Atualmente estamos apenas fazendo construções simples para refletir quão longe chegamos desde a era do GPT-3, mas [podemos] nos ver escalando para planos e tarefas orientadas a objetivos mais longos,” disse Singh. “Os jogos podem ser apenas um meio para testar o raciocínio agente de forma mais segura do que na vida real e mais controlável para fins de teste, tornando-os mais ideais aos meus olhos.”
Outros jogos, como Pokémon Red, Street Fighter e Pictionary, foram usados como benchmarks experimentais para IA, em parte porque a arte de avaliar IA é notoriamente complicada.
Os pesquisadores costumam testar modelos de IA em avaliações padronizadas, mas muitos desses testes dão vantagem ao modelo de IA. Devido à forma como são treinados, os modelos são naturalmente talentosos em certos tipos restritos de resolução de problemas, especialmente aqueles que requerem memorização ou extrapolação básica.
Simplificando, é difícil entender o que significa que o GPT-4 da OpenAI pode pontuar no 88º percentil no LSAT, mas não consegue discernir quantas letras R estão na palavra “morango.” A Claude 3.7 Sonnet da Anthropic alcançou 62,3% de precisão em um benchmark padronizado de engenharia de software, mas é pior em jogar Pokémon do que a maioria das crianças de cinco anos.
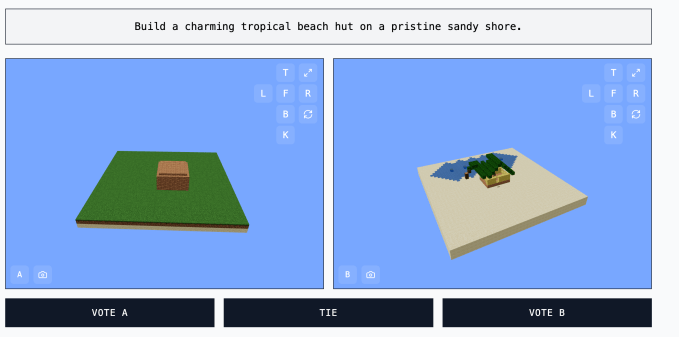
O MC-Bench é tecnicamente um benchmark de programação, uma vez que os modelos são solicitados a escrever código para criar a construção solicitada, como “Frosty the Snowman” ou “uma charmosa cabana tropical em uma costa de areia limpa.”
Mas é mais fácil para a maioria dos usuários do MC-Bench avaliar se um boneco de neve parece melhor do que se aprofundar no código, o que dá ao projeto um apelo mais amplo — e, portanto, o potencial de coletar mais dados sobre quais modelos têm pontuações consistentemente melhores.
Se essas pontuações significam muito em termos de utilidade da IA, fica em debate, é claro. Singh afirma que são um forte sinal, embora.
“O classificador atual reflete bastante minha própria experiência com o uso desses modelos, ao contrário de muitos benchmarks puramente textuais,” disse Singh. “Talvez [o MC-Bench] possa ser útil para as empresas saberem se estão indo na direção certa.”

Conteúdo relacionado

AllTrails lança assinatura de $80/ano que inclui rotas inteligentes com tecnologia de IA.
[the_ad id="145565"] AllTrails, o companheiro de caminhadas e ciclismo nomeado como o App do Ano para iPhone de 2023, está lançando uma nova assinatura premium chamada “Peak”,…

Melhorias nos modelos de IA de ‘raciocínio’ podem desacelerar em breve, aponta análise.
[the_ad id="145565"] Uma análise da Epoch AI, um instituto de pesquisa em IA sem fins lucrativos, sugere que a indústria de IA pode não conseguir obter grandes ganhos de…

Co-fundador da Anthropic, Jared Kaplan, virá ao TechCrunch Sessions: AI
[the_ad id="145565"] Está com vontade de aprender mais sobre a Anthropic diretamente da fonte? Você não está sozinho, e é por isso que estamos animados em anunciar que Jared…