


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder no setor. Saiba mais
A Reve AI, Inc., uma startup de IA com sede em Palo Alto, Califórnia, lançou oficialmente o Reve Image 1.0, um modelo avançado de geração de imagem a partir de texto, projetado para se destacar na adesão a prompts, estética e tipografia. Este é o primeiro lançamento da empresa, com ferramentas futuras previstas para serem desenvolvidas.
O Reve Image está atualmente disponível para prévia gratuita em preview.reve.art, permitindo que usuários gerem imagens a partir de descrições de texto sem necessidade de engenharia de prompt avançada.
A empresa ainda não anunciou o acesso à API ou planos de preços de longo prazo, nem está claro se o modelo será proprietário ou open source, e, se for, sob qual licença.
Uma nova abordagem para imagens de IA
O Reve Image se diferencia ao buscar uma compreensão mais profunda da intenção do usuário. Permite que os usuários não só gerem imagens a partir de texto, mas também modifiquem imagens existentes com comandos de linguagem simples.
As modificações de exemplo incluem mudança de cores, ajuste de texto e alteração de perspectivas. O modelo também suporta o upload de imagens de referência, permitindo que os usuários criem visuais que correspondam a um estilo ou inspiração específicos.
Uma das capacidades de destaque do modelo é seu forte desempenho de renderização de texto, abordando um desafio comum na imagem gerada por IA — e tornando-o mais competitivo diretamente com modelos de imagem focados em texto, como Ideogram, que são mais valiosos para aqueles que estão projetando logotipos e branding.
Além disso, testes iniciais de usuários sugerem que o Reve Image lida com prompts de múltiplos caracteres de forma mais eficaz do que modelos anteriores.
Já liderando as tabelas de benchmark de terceiros
O Reve Image já foi avaliado pelo serviço de teste de modelos de IA de terceiros Artificial Analysis.
No Image Arena da Artificial Analysis, que classifica vários modelos de geração de imagem com base em avaliações de usuários e outras métricas quantitativas, o Reve está atualmente na liderança em #1 por “qualidade de geração de imagem”, superando concorrentes como Midjourney v6.1, Imagen 3 do Google, Recraft V3 e FLUX.1.1 [pro] do Black Forest Lab.
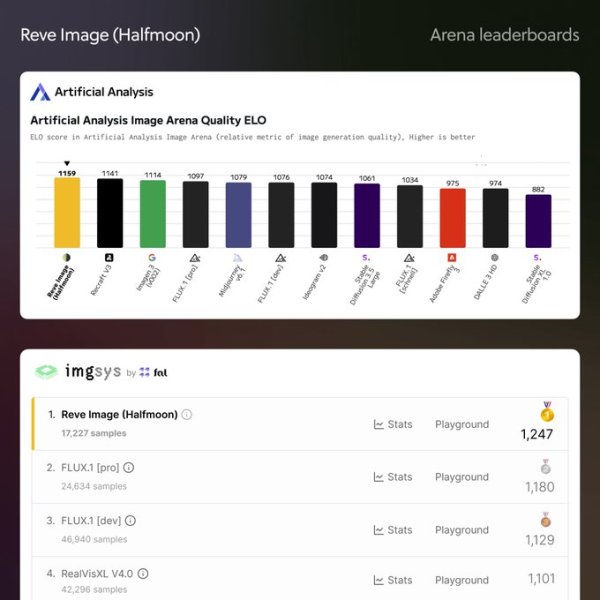
O grupo de benchmark destacou a capacidade do Reve Image de gerar texto claro e legível dentro das imagens, uma tarefa historicamente difícil para modelos de IA.
Antes de sua revelação oficial, o Reve Image era conhecido pelo codinome “Halfmoon” nas redes sociais, gerando especulação e antecipação dentro da comunidade de IA.
Unindo a compreensão humana e de IA para criar imagens melhores, de maior qualidade e mais realistas
A Reve se descreve como uma “pequena equipe de pesquisadores, construtores, designers e contadores de histórias apaixonados com grandes ideias.” A empresa está focada em desenvolver ferramentas criativas que melhorem a interação dos usuários com visuais movidos por IA.
No X, Michaël Gharbi, cofundador e cientista de pesquisa da Reve, compartilhou insights sobre a visão de longo prazo da empresa, enfatizando o objetivo de construir modelos de IA que compreendam a intenção criativa em vez de apenas gerar saídas visualmente plausíveis.
“Capturar a intenção criativa exige uma compreensão avançada da linguagem natural e de outras interações”, disse Gharbi. “Nossa visão é construir uma nova representação semântica intermediária que tanto um humano quanto uma máquina possam entender, raciocinar e operar.”
Outros membros da equipe, incluindo o engenheiro Hunter Loftis e o pesquisador Taesung Park, enfatizaram a importância de trazer lógica aos visuais gerados por IA.
Park comparou os atuais modelos de imagem a partir de texto com os primeiros grandes modelos de linguagem (LLMs), afirmando que eles costumam produzir resultados visualmente atraentes, mas logicamente inconsistentes.
Relatórios iniciais de usuários mostram promessas e limitações
Os primeiros feedbacks de usuários no subreddit r/singularity (no Reddit) foram, em sua maioria, positivos, com muitos elogiando a aderência precisa do modelo aos prompts, a alta qualidade de renderização de texto e a velocidade rápida de geração.
Alguns usuários relataram sucesso em gerar cenas com múltiplos personagens e ambientes complexos, áreas nas quais modelos anteriores costumavam enfrentar dificuldades.
No entanto, alguns desafios permanecem. Os usuários notaram que o Reve Image:
- Enfrenta dificuldades com certos objetos complexos (por exemplo, materiais transparentes como um copo de vinho cheio).
- Tem dificuldade em reconhecer personagens ficcionais específicos (por exemplo, usuários que tentaram gerar personagens de videogames descobriram que o modelo produziu resultados mais genéricos).
- Ocasionalmente, coloca detalhes de forma errada em composições com múltiplos objetos.
Apesar desses obstáculos, a equipe da Reve tem se engajado ativamente com a comunidade de usuários e incorporado feedbacks nas melhorias em andamento.
Em minha própria breve utilização enquanto redigia e criava a imagem de cabeçalho para este artigo, descobri que o Reve era bastante intuitivo e fácil de usar, com visuais impressionantes e boa aderência aos prompts. Como muitos geradores de imagens por IA, há uma caixa de entrada de prompts, embora, ao contrário do Midjourney e Ideogram, o Reve a coloque na parte inferior do site e deixe seu conteúdo gerado na parte superior para preencher a maior parte do espaço.
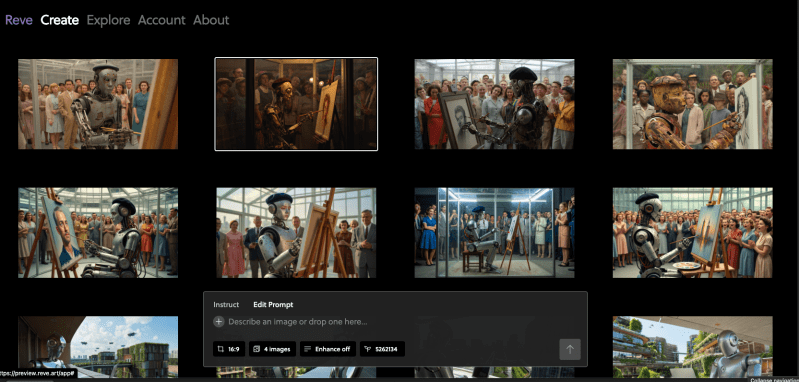
Além disso, a caixa de entrada de prompts também contém quatro botões abaixo dela para ajustes finos na sequência do prompt de geração de imagem, incluindo um ajustador de aspecto (com tamanhos padrão entre 16:9 (paisagem widescreen) e 9:16 (retrato, como em um smartphone)…
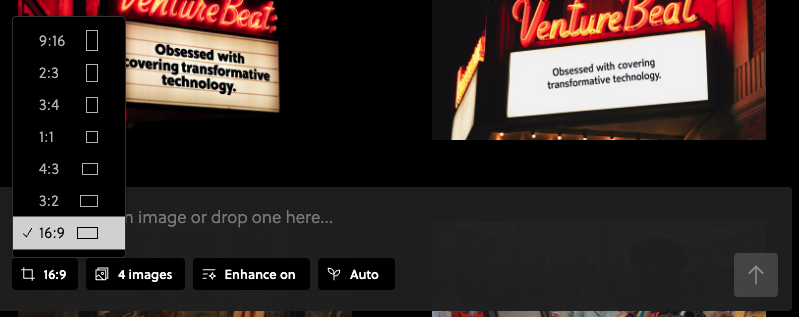
Há também um botão para selecionar quantas imagens você deseja produzir a partir de cada prompt (1, 2, 4, 8), um botão para alternar a melhoria do texto do prompt (que está padrão ativado, o que significa que o Reve editará automaticamente o texto que você digitar com base no que acha que você deseja ver em sua imagem, adicionando muitos mais detalhes ricos e linguagem visual do que você poderia incluir inicialmente) e um botão “seed” para escolher se deseja usar uma string numérica específica de uma imagem gerada anteriormente para guiar as gerações futuramente.
É um número muito menor de configurações e não inclui editores visuais baseados em imagens como o Midjourney, mas os fundamentos estão lá e deve ser mais do que suficiente para a maioria dos usuários casuais de imagens de IA começarem.
Meus testes breves também mostraram que ele estava à par ou melhor do que o Ideogram na renderização de texto legível integrado às imagens (superando de longe o Midjourney), além de estar à par ou superior na qualidade de renderização de figuras públicas reconhecíveis como o Grok (novamente, o Midjourney e muitos outros geradores de imagens proíbem isso).

O que vem a seguir para o Reve Image?
Embora o modelo esteja atualmente disponível apenas através do site da empresa, há uma crescente expectativa por acesso à API ou opções open source potenciais.
Os usuários também expressaram interesse em recursos adicionais, como treinamento de modelos personalizados, ferramentas de controle para animação e integração com software criativo.
Por enquanto, o Reve Image permanece acessível gratuitamente em preview.reve.art, permitindo que os usuários explorem suas capacidades em primeira mão. À medida que a Reve continua a refinar seus modelos de IA e expandir suas ofertas, a empresa está se posicionando como um jogador importante no mundo em evolução das ferramentas criativas movidas por IA.


Conteúdo relacionado

CEO da Perplexity nega ter problemas financeiros e afirma que não haverá IPO antes de 2028.
[the_ad id="145565"] Perplexity O CEO da Perplexity, Aravind Srinivas, recentemente recorreu ao Reddit para abordar as reclamações dos usuários sobre o produto e…

Apple estaria reformulando o app Saúde para incluir um treinador de IA.
[the_ad id="145565"] A Apple está desenvolvendo uma nova versão de seu aplicativo de Saúde que inclui um coach de IA que pode aconselhar os usuários sobre como melhorar sua…

Os modelos de IA mais inovadores: o que fazem e como utilizá-los
[the_ad id="145565"] Modelos de IA estão sendo produzidos a um ritmo alucinante, por todos, desde grandes empresas de tecnologia como Google até startups como OpenAI e…