


A Arc Prize Foundation, uma organização sem fins lucrativos co-fundada pelo renomado pesquisador de IA François Chollet, anunciou em um post no blog nesta segunda-feira que criou um novo teste desafiador para medir a inteligência geral dos principais modelos de IA.
Até agora, o novo teste, chamado ARC-AGI-2, tem deixado a maioria dos modelos perplexos.
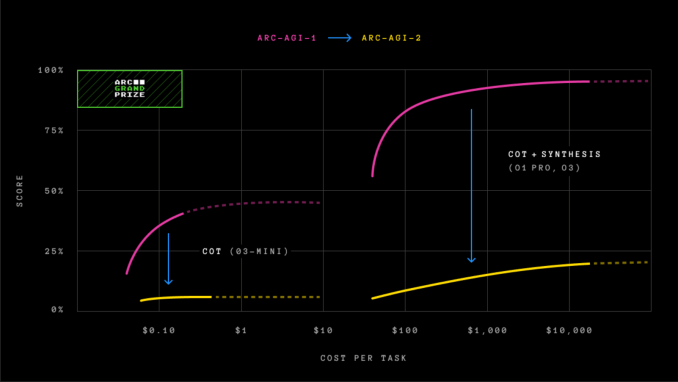
Modelos de IA “racionais” como o o1-pro da OpenAI e o R1 da DeepSeek pontuam entre 1% e 1,3% no ARC-AGI-2, de acordo com o ranking da Arc Prize. Modelos não-racionais poderosos, incluindo GPT-4.5, Claude 3.7 Sonnet e Gemini 2.0 Flash, também marcam em torno de 1%.
Os testes ARC-AGI consistem em problemas semelhantes a quebra-cabeças, onde a IA precisa identificar padrões visuais a partir de uma coleção de quadrados de cores diferentes e gerar a grade correta como “resposta”. Os problemas foram projetados para forçar uma IA a se adaptar a novos desafios que ela ainda não encontrou.
A Arc Prize Foundation teve mais de 400 pessoas participando do ARC-AGI-2 para estabelecer uma linha base humana. Em média, “painéis” dessas pessoas acertaram 60% das perguntas do teste — muito melhor do que qualquer uma das pontuações dos modelos.
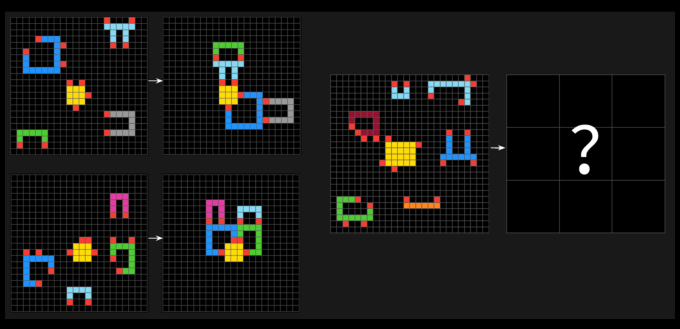
Em um post no X, Chollet afirmou que o ARC-AGI-2 é uma melhor medida da inteligência real de um modelo de IA do que a primeira iteração do teste, o ARC-AGI-1. Os testes da Arc Prize Foundation visam avaliar se um sistema de IA pode adquirir novas habilidades de forma eficiente fora dos dados com os quais foi treinado.
Chollet disse que, ao contrário do ARC-AGI-1, o novo teste impede que os modelos de IA se dependam da “força bruta” — poder computacional extensivo — para encontrar soluções. Chollet reconheceu anteriormente que essa era uma grande falha do ARC-AGI-1.
Para abordar as falhas do primeiro teste, o ARC-AGI-2 introduz uma nova métrica: eficiência. Ele também exige que os modelos interpretem padrões em tempo real, em vez de se basearem na memorização.
“A inteligência não é definida apenas pela capacidade de resolver problemas ou alcançar altas pontuações”, escreveu Greg Kamradt, co-fundador da Arc Prize Foundation, em um post no blog. “A eficiência com a qual essas capacidades são adquiridas e empregadas é um componente crucial e definidor. A questão central não é apenas, ‘A IA pode adquirir [a] habilidade para resolver uma tarefa?’ mas também, ‘Com que eficiência ou custo?’”
O ARC-AGI-1 permaneceu imbatido por cerca de cinco anos até dezembro de 2024, quando a OpenAI lançou seu modelo avançado de raciocínio, o o3, que superou todos os outros modelos de IA e igualou o desempenho humano na avaliação. No entanto, como notamos na época, os ganhos de desempenho do o3 no ARC-AGI-1 vieram com um preço elevado.
A versão do modelo o3 da OpenAI — o3 (baixo) — que foi a primeira a alcançar novas alturas no ARC-AGI-1, marcando 75,7% no teste, obteve apenas 4% no ARC-AGI-2 usando $200 em poder computacional por tarefa.
A chegada do ARC-AGI-2 ocorre em um momento em que muitos na indústria de tecnologia pedem novos benchmarks não saturados para medir o progresso da IA. O co-fundador da Hugging Face, Thomas Wolf, disse recentemente ao TechCrunch que a indústria de IA carece de testes suficientes para medir as características-chave da chamada inteligência geral artificial, incluindo criatividade.
Além do novo benchmark, a Arc Prize Foundation anunciou um novo concurso Arc Prize 2025, desafiando desenvolvedores a alcançarem 85% de precisão no teste ARC-AGI-2 enquanto gastam apenas $0,42 por tarefa.

Conteúdo relacionado

O Google está trazendo o Gemini para smartwatches com Wear OS e Google TV
[the_ad id="145565"] Durante o Android Show na terça-feira, próximo ao Google I/O, o Google anunciou que está trazendo o Gemini para smartwatches Wear OS e Google TV. O anúncio…

O Google está levando o Gemini para o seu carro com o Android Auto.
[the_ad id="145565"] O Google está trazendo o Gemini, sua IA generativa, para todos os carros que suportam o Android Auto nos próximos meses, conforme foi anunciado na sua…

TikTok lança o TikTok AI Alive, uma nova ferramenta de imagem para vídeo.
[the_ad id="145565"] O TikTok está lançando seu primeiro recurso de IA de imagem para vídeo, conforme a empresa anunciou na terça-feira. O novo recurso se chama "TikTok AI…