


Uma nova pesquisa da Rússia propõe um método não convencional para detectar imagens geradas por IA que são irreais – não melhorando a precisão de grandes modelos de linguagem de visão (LVLMs), mas aproveitando intencionalmente sua tendência a alucinar.
A abordagem inovadora extrai múltiplos ‘fatos atômicos’ sobre uma imagem usando LVLMs e, em seguida, aplica a inferência de linguagem natural (NLI) para medir sistematicamente as contradições entre essas declarações – transformando efetivamente as falhas do modelo em uma ferramenta de diagnóstico para detectar imagens que desafiam o senso comum.

Duas imagens do conjunto de dados WHOOPS! ao lado de declarações geradas automaticamente pelo modelo LVLM. A imagem à esquerda é realista, levando a descrições consistentes, enquanto a imagem incomum à direita faz com que o modelo alucine, produzindo declarações contraditórias ou falsas. Fonte: https://arxiv.org/pdf/2503.15948
Ao ser solicitado a avaliar o realismo da segunda imagem, o LVLM percebe que algo está errado, já que o camelo representado tem três corcovas, o que é desconhecido na natureza.
No entanto, o LVLM inicialmente confunde >2 corcovas com >2 animais, já que esta é a única maneira de se ver três corcovas em uma ‘imagem de camelo’. Ele então prossegue para alucinar algo ainda mais improvável do que três corcovas (ou seja, ‘duas cabeças’) e nunca detalha a própria coisa que parece ter desencadeado suas suspeitas – a improvável corcova extra.
Os pesquisadores do novo trabalho descobriram que os modelos LVLM podem realizar este tipo de avaliação nativamente, e de forma comparável (ou melhor) do que modelos que foram ajustados para uma tarefa desse tipo. Como o ajuste fino é complicado, caro e bastante instável em termos de aplicabilidade posterior, a descoberta de um uso nativo para um dos maiores obstáculos na atual revolução da IA é uma reviravolta refrescante nas tendências gerais da literatura.
Avaliação Aberta
A importância da abordagem, os autores afirmam, é que ela pode ser implementada com frameworks de código aberto. Embora um modelo avançado e de alto investimento como o ChatGPT possa (como o artigo admite) oferecer potencialmente melhores resultados nessa tarefa, o valor real discutido na literatura para a maioria de nós (e especialmente para as comunidades de hobbyistas e VFX) é a possibilidade de incorporar e desenvolver novas inovações em implementações locais; por outro lado, tudo que está destinado a um sistema de API comercial proprietário está sujeito a retiradas, aumentos de preços arbitrários e políticas de censura que são mais propensas a refletir preocupações corporativas do que as necessidades e responsabilidades do usuário.
O novo artigo é intitulado Não Lute Contra Alucinações, Use-as: Estimativa de Realismo de Imagens usando NLI sobre Fatos Atômicos, e vem de cinco pesquisadores do Instituto Skolkovo de Ciência e Tecnologia (Skoltech), do Instituto de Física e Tecnologia de Moscou, e das empresas russas MTS AI e AIRI. O trabalho possui uma página no GitHub acompanhando.
Método
Os autores utilizam o Conjunto de Dados WHOOPS! para o projeto:

Exemplos de imagens impossíveis do Conjunto de Dados WHOOPS! É notável como essas imagens montam elementos plausíveis, e que sua improbabilidade deve ser calculada com base na concatenação desses aspectos incompatíveis. Fonte: https://whoops-benchmark.github.io/
O conjunto de dados compreende 500 imagens sintéticas e mais de 10.874 anotações, especificamente projetadas para testar o raciocínio de senso comum e a compreensão composicional dos modelos de IA. Foi criado em colaboração com designers encarregados de gerar imagens desafiadoras através de sistemas de texto-para-imagem, como Midjourney e as séries DALL-E – produzindo cenários difíceis ou impossíveis de serem capturados naturalmente:

Exemplos adicionais do conjunto de dados WHOOPS!. Fonte: https://huggingface.co/datasets/nlphuji/whoops
A nova abordagem funciona em três etapas: primeiro, o LVLM (especificamente LLaVA-v1.6-mistral-7b) é solicitado a gerar múltiplas declarações simples – chamadas de ‘fatos atômicos’ – descrevendo uma imagem. Essas declarações são geradas usando Diverse Beam Search, garantindo variabilidade nas saídas.
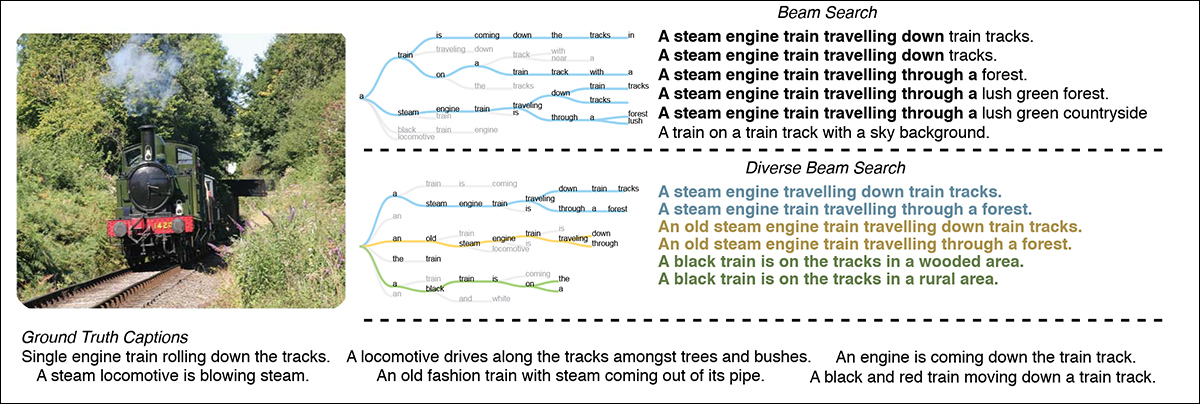
Diverse Beam Search produz uma melhor variedade de opções de legenda otimizando um objetivo aumentado de diversidade. Fonte: https://arxiv.org/pdf/1610.02424
Em seguida, cada declaração gerada é comparada sistematicamente com todas as outras declarações usando um modelo de Inferência de Linguagem Natural, que atribui pontuações refletindo se pares de declarações implicam, contradizem ou são neutras entre si.
Contradições indicam alucinações ou elementos irreais dentro da imagem:
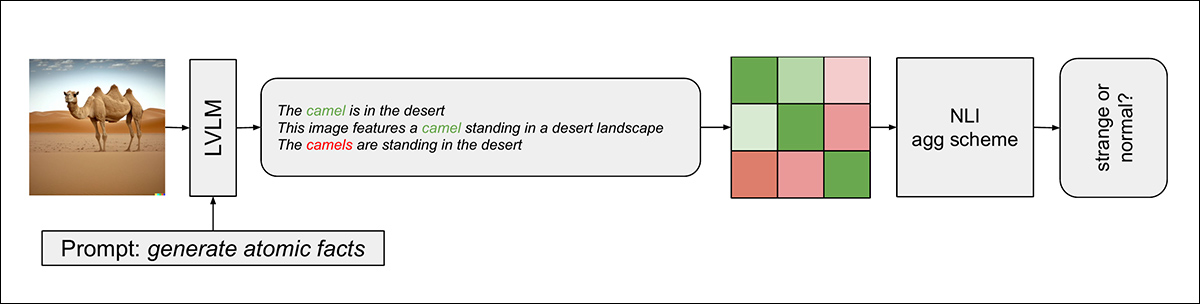
Esquema para o pipeline de detecção.
Finalmente, o método agrega essas pontuações NLI em par para uma única ‘pontuação de realidade’ que quantifica a coesão geral das declarações geradas.
Os pesquisadores exploraram diferentes métodos de agregação, com uma abordagem baseada em agrupamento apresentando o melhor desempenho. Os autores aplicaram o algoritmo de agrupamento k-means para separar pontuações NLI individuais em dois grupos, e o centroide do grupo de menor valor foi então escolhido como a métrica final.
Usar dois grupos se alinha diretamente com a natureza binária da tarefa de classificação, ou seja, distinguir imagens realistas de irreais. A lógica é semelhante a simplesmente escolher a menor pontuação geral; no entanto, o agrupamento permite que a métrica represente a média de contradições entre vários fatos, em vez de depender de um único outlier.
Dados e Testes
Os pesquisadores testaram seu sistema na benchmark WHOOPS!, usando divisões de teste rotativas (ou seja, validação cruzada). Os modelos testados foram BLIP2 FlanT5-XL e BLIP2 FlanT5-XXL em divisões, e BLIP2 FlanT5-XXL em formato de zero-shot (ou seja, sem treinamento adicional).
Para uma linha de base de seguimento de instruções, os autores solicitaram aos LVLMs a frase ‘Isso é incomum? Por favor, explique brevemente com uma frase curta’, que pesquisas anteriores descobriram eficazes para identificar imagens irreais.
Os modelos avaliados foram LLaVA 1.6 Mistral 7B, LLaVA 1.6 Vicuna 13B, e dois tamanhos (7/13 bilhões de parâmetros) de InstructBLIP.
O procedimento de teste foi centrado em 102 pares de imagens realistas e irreais (‘estranhas’). Cada par foi composto por uma imagem normal e uma contraparte que desafiava o senso comum.
Três anotadores humanos rotularam as imagens, alcançando um consenso de 92%, indicando forte concordância humana sobre o que constitui ‘estranheza’. A precisão dos métodos de avaliação foi medida pela capacidade de distinguir corretamente entre imagens realistas e irreais.
O sistema foi avaliado usando validação cruzada em três dobras, embaralhando aleatoriamente os dados com uma semente fixa. Os autores ajustaram pesos para pontuações de implicação (declarações que concordam logicamente) e pontuações de contradição (declarações que entram em conflito logicamente) durante o treinamento, enquanto as pontuações ‘neutras’ foram fixadas em zero. A precisão final foi calculada como a média em todas as divisões de teste.
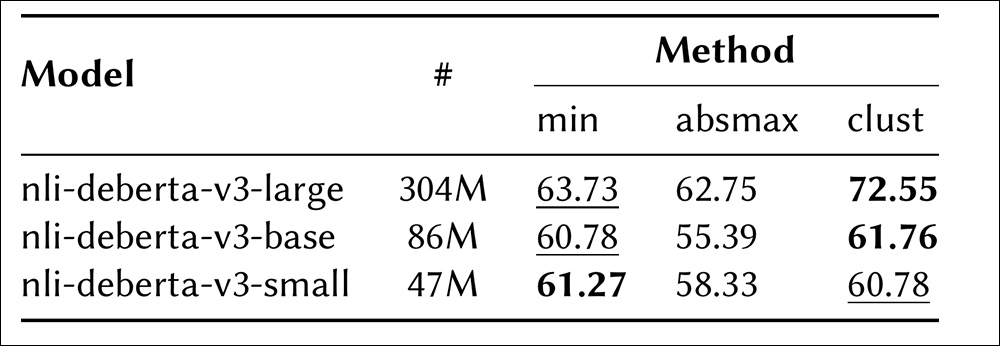
Comparação de diferentes modelos NLI e métodos de agregação em um subconjunto de cinco fatos gerados, medidos por precisão.
Quanto aos resultados iniciais mostrados acima, o artigo afirma:
‘O método [‘clust’] se destaca como um dos melhores desempenhos. Isso implica que a agregação de todas as pontuações de contradição é crucial, em vez de se concentrar apenas em valores extremos. Além disso, o maior modelo NLI (nli-deberta-v3-large) supera todos os outros para todos os métodos de agregação, sugerindo que captura a essência do problema de forma mais eficaz.’
Os autores descobriram que os pesos ótimos favoreciam consistentemente a contradição em detrimento da implicação, indicando que as contradições eram mais informativas para distinguir imagens irreais. O seu método superou todos os outros métodos de zero-shot testados, chegando muito próximo do desempenho do modelo BLIP2 ajustado:
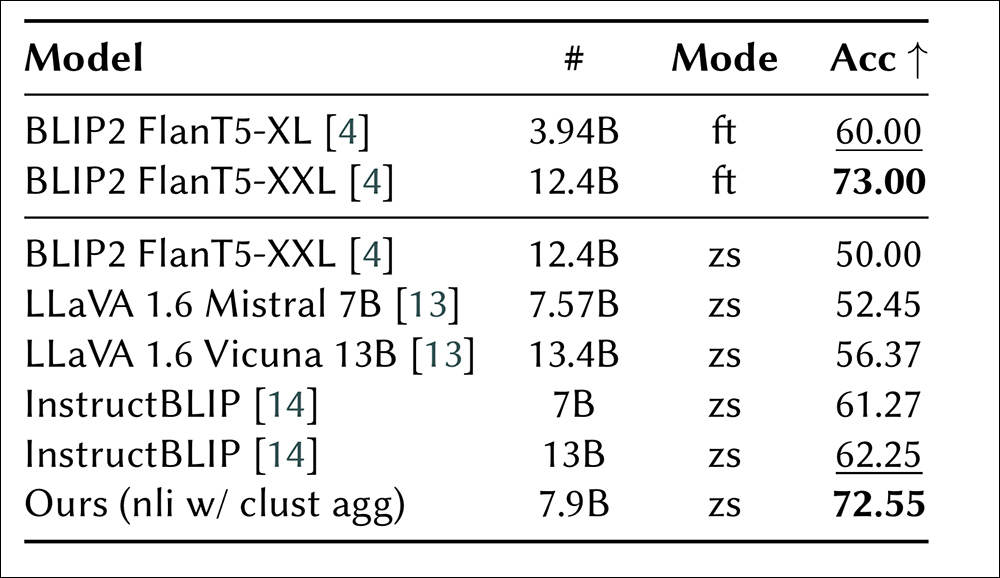
Desempenho de várias abordagens na benchmark WHOOPS!. Métodos ajustados (ft) aparecem no topo, enquanto métodos de zero-shot (zs) estão listados abaixo. O tamanho do modelo indica o número de parâmetros, e a precisão é usada como a métrica de avaliação.
Eles também notaram, um tanto inesperadamente, que o InstructBLIP teve melhor desempenho do que modelos LLaVA comparáveis, dada a mesma solicitação. Embora reconhecendo a precisão superior do GPT-4, o artigo enfatiza a preferência dos autores em demonstrar soluções práticas e de código aberto e, parece, podem reivindicar razoavelmente a novidade em explorar explicitamente alucinações como uma ferramenta de diagnóstico.
Conclusão
No entanto, os autores reconhecem a dívida de seu projeto ao lançamento do FaithScore de 2024, uma colaboração entre a Universidade do Texas em Dallas e a Universidade Johns Hopkins.

Ilustração de como a avaliação do FaithScore funciona. Primeiro, declarações descritivas dentro de uma resposta gerada por LVLM são identificadas. Em seguida, essas declarações são quebradas em fatos atômicos individuais. Finalmente, os fatos atômicos são comparados com a imagem de entrada para verificar sua precisão. O texto sublinhado destaca o conteúdo descritivo objetivo, enquanto o texto azul indica declarações alucinatórias, permitindo que o FaithScore forneça uma medida interpretável de correção factual. Fonte: https://arxiv.org/pdf/2311.01477
O FaithScore mede a fidelidade das descrições geradas por LVLM, verificando a consistência em relação ao conteúdo da imagem, enquanto os métodos do novo artigo exploram explicitamente as alucinações do LVLM para detectar imagens irreais através de contradições nos fatos gerados usando Inferência de Linguagem Natural.
O novo trabalho é, naturalmente, dependente das peculiaridades dos atuais modelos de linguagem e da disposição deles para alucinar. Se o desenvolvimento de modelos algum dia resultar em um modelo totalmente não alucinatório, mesmo os princípios gerais do novo trabalho não seriam mais aplicáveis. No entanto, isso continua a ser uma perspectiva desafiadora.
Primeira publicação na terça-feira, 25 de março de 2025

Conteúdo relacionado

AWS firma “parceria estratégica” com a Humain apoiada pela Arábia Saudita.
[the_ad id="145565"] A Amazon afirma que trabalhará com a Humain, a empresa de IA recentemente lançada pelo governante da Arábia Saudita, Mohammed bin Salman, para investir…

Anthropic e Google conquistam vitória ao conseguir Harvey, apoiado pela OpenAI, como usuário.
[the_ad id="145565"] O popular ferramenta de IA legal Harvey agora utilizará modelos de fundação de ponta da Anthropic e do Google, avançando além do uso exclusivo dos modelos…

O relatório de segurança prometido pela xAI está desaparecido.
[the_ad id="145565"] A empresa de IA de Elon Musk, xAI, perdeu um prazo autoimposto para publicar um framework de segurança de IA finalizado, conforme observado pelo grupo de…