


Modelos de vídeos de fundação, como Hunyuan e Wan 2.1, apesar de serem poderosos, não oferecem aos usuários o nível de controle granular que a produção de filmes e TV (especialmente a produção de VFX) exige.
Em estúdios profissionais de efeitos visuais, modelos de código aberto como estes, juntamente com modelos anteriores baseados em imagens (em vez de vídeos), como Stable Diffusion, Kandinsky e Flux, são normalmente utilizados ao lado de uma gama de ferramentas auxiliares que adaptam suas saídas brutas para atender a necessidades criativas específicas. Quando um diretor diz, “Isso está ótimo, mas podemos torná-lo um pouco mais [n]?”, não se pode responder que o modelo não é preciso o suficiente para lidar com tais pedidos.
Em vez disso, uma equipe de VFX com IA utilizará uma variedade de técnicas tradicionais de CGI e composição, aliadas a procedimentos e fluxos de trabalho personalizados desenvolvidos ao longo do tempo, para tentar levar os limites da síntese de vídeo um pouco além.
Assim, por analogia, um modelo de vídeo de fundação é muito semelhante a uma instalação padrão de um navegador da web como o Chrome; ele faz muitas coisas logo de cara, mas se você quiser que ele se adapte às suas necessidades, e não o contrário, precisará de alguns plugins.
Freaks de Controle
No mundo da síntese de imagens baseada em difusão, o sistema de terceiros mais importante é o ControlNet.
ControlNet é uma técnica para adicionar controle estruturado a modelos generativos baseados em difusão, permitindo que os usuários orientem a geração de imagens ou vídeos com entradas adicionais, como mapas de borda, mapas de profundidade ou informações de pose.

Os vários métodos do ControlNet permitem geração de imagem a partir de profundidade (linha de cima), segmentação semântica para imagem (inferior esquerda) e geração de imagem guiada por pose de humanos e animais (inferior direita).
Em vez de depender apenas de prompts de texto, o ControlNet introduz ramificações de rede neural separadas, ou adaptadores, que processam esses sinais de condicionamento enquanto preservam as capacidades gerativas do modelo base.
Isso possibilita saídas ajustadas que aderem mais de perto às especificações do usuário, tornando-o particularmente útil em aplicações onde o controle de composição, estrutura ou movimento é necessário:

Com uma pose guia, uma variedade de tipos de saída precisos pode ser obtida via ControlNet. Fonte: https://arxiv.org/pdf/2302.05543
No entanto, estruturas baseadas em adaptadores desse tipo operam externamente a um conjunto de processos neurais que estão muito focados internamente. Essas abordagens têm várias desvantagens.
Primeiro, os adaptadores são treinados de forma independente, levando a conflitos de ramificação quando múltiplos adaptadores são combinados, o que pode comprometer a qualidade da geração.
Em segundo lugar, eles introduzem redundância de parâmetros, exigindo computação e memória adicionais para cada adaptador, tornando a escalabilidade ineficiente.
Terceiro, apesar de sua flexibilidade, os adaptadores costumam produzir resultados sub-éticos em comparação com modelos que são totalmente ajustados para geração de múltiplas condições. Esses problemas tornam os métodos baseados em adaptadores menos eficazes para tarefas que requerem uma integração perfeita de múltiplos sinais de controle.
Idealmente, as capacidades do ControlNet seriam treinadas nativamente no modelo, de uma maneira modular que poderia acomodar inovações óbvias e muito aguardadas, como geração simultânea de vídeo/áudio ou capacidades nativas de sincronia labial (para áudio externo).
Atualmente, cada funcionalidade extra representa uma tarefa de pós-produção ou um procedimento não nativo que precisa navegar pelos pesos apertados e sensíveis de qualquer modelo de fundação no qual está operando.
FullDiT
Em meio a esse impasse, surge uma nova oferta da China, que propõe um sistema onde medidas do tipo ControlNet são incorporadas diretamente em um modelo de vídeo generativo no momento do treinamento, em vez de serem relegadas a uma reflexão posterior.
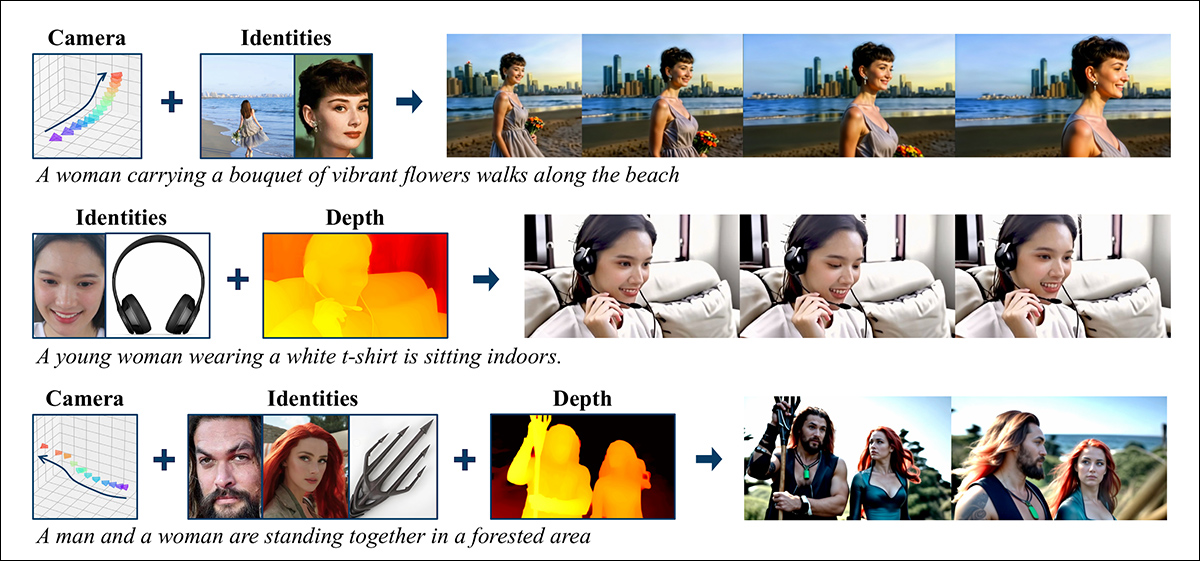
De novo paper: a abordagem FullDiT pode incorporar imposição de identidade, profundidade e movimento de câmera em uma geração nativa e pode convocar qualquer combinação desses ao mesmo tempo. Fonte: https://arxiv.org/pdf/2503.19907
Intitulado FullDiT, a nova abordagem funde condições de múltiplas tarefas, como transferência de identidade, mapeamento de profundidade e movimento de câmera em uma parte integrada de um modelo de vídeo generativo treinado, para o qual os autores produziram um modelo protótipo treinado e clipes de vídeo em um site do projeto.
No exemplo abaixo, vemos gerações que incorporam movimento de câmera, informações de identidade e informações de texto (ou seja, prompts textuais guiados pelo usuário):
Clique para reproduzir. Exemplos de imposição de usuário do tipo ControlNet com apenas um modelo de fundação treinado nativamente. Fonte: https://fulldit.github.io/
Deve-se notar que os autores não propõem seu modelo treinado experimental como um modelo de fundação funcional, mas sim como uma prova de conceito para modelos nativos de texto-para-vídeo (T2V) e imagem-para-vídeo (I2V) que oferecem aos usuários mais controle do que apenas um prompt de imagem ou um prompt de texto.
Como não há modelos similares desse tipo ainda, os pesquisadores criaram um novo benchmark chamado FullBench, para a avaliação de vídeos multitarefa, e afirmam ter um desempenho de ponta em testes comparativos que elaboraram contra abordagens anteriores. No entanto, uma vez que o FullBench foi projetado pelos próprios autores, sua objetividade não foi testada, e seu conjunto de dados contém 1.400 casos, que podem ser muito limitados para conclusões mais amplas.
Talvez o aspecto mais interessante da arquitetura proposta no artigo é seu potencial para incorporar novos tipos de controle. Os autores afirmam:
‘Neste trabalho, exploramos apenas condições de controle da câmera, identidades e informações de profundidade. Não investigamos mais outras condições e modalidades, como áudio, fala, nuvens de pontos, caixas delimitadoras de objetos, fluxo óptico, etc. Embora o design do FullDiT possa integrar outras modalidades sem problemas com modificações mínimas na arquitetura, como adaptar rapidamente modelos existentes a novas condições e modalidades ainda é uma questão importante que merece mais exploração.’
Embora os pesquisadores apresentem o FullDiT como um avanço na geração de vídeo multitarefa, deve-se considerar que este novo trabalho se baseia em arquiteturas existentes em vez de introduzir um paradigma fundamentalmente novo.
No entanto, o FullDiT atualmente se destaca (até onde sei) como um modelo de fundação de vídeo com as facilidades do tipo ControlNet ‘hard coded’ – e é bom ver que a arquitetura proposta pode acomodar inovações posteriores também.
Clique para reproduzir. Exemplos de movimentos de câmera controlados pelo usuário, do site do projeto.
O novo artigo é intitulado FullDiT: Multi-Task Video Generative Foundation Model with Full Attention, e provém de nove pesquisadores da Kuaishou Technology e da Universidade Chinesa de Hong Kong. A página do projeto está aqui e os novos dados de benchmark estão no Hugging Face.
Método
Os autores sustentam que o mecanismo de atenção unificado do FullDiT permite um aprendizado de representação cross-modal mais forte, capturando tanto relacionamentos espaciais quanto temporais entre as condições:
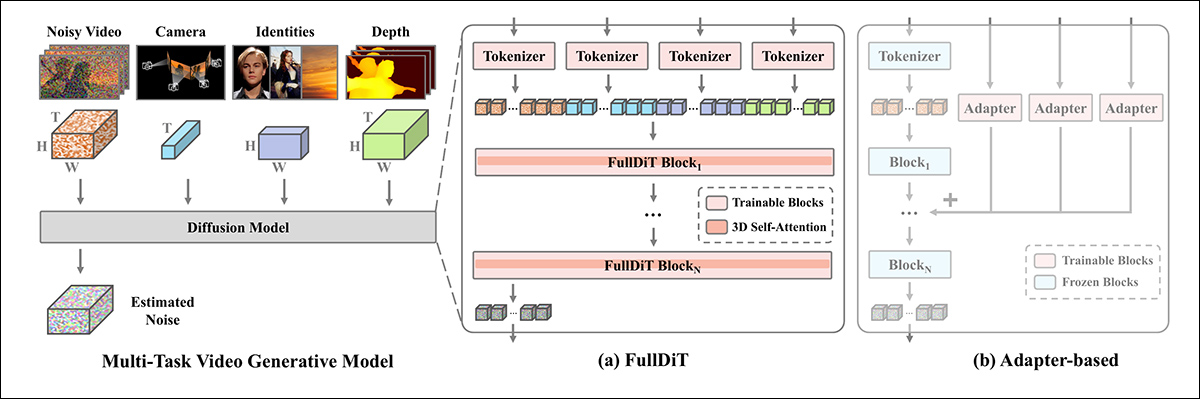
De acordo com o novo artigo, o FullDiT integra múltiplas condições de entrada por meio de atenção total, convertendo-as em uma sequência unificada. Em contraste, modelos baseados em adaptadores (mais à esquerda) usam módulos separados para cada entrada, levando à redundância, conflitos e desempenho mais fraco.
Diferentemente das configurações baseadas em adaptadores que processam cada fluxo de entrada separadamente, esta estrutura de atenção compartilhada evita conflitos de ramificação e reduz a sobrecarga de parâmetros. Eles também afirmam que a arquitetura pode escalar com novos tipos de entrada sem redesenhos significativos – e que o esquema do modelo mostra sinais de generalização para combinações de condições não vistas durante o treinamento, como vincular movimento de câmera com identidade de personagem.
Clique para reproduzir. Exemplos de geração de identidade do site do projeto.
Na arquitetura do FullDiT, todas as entradas de condição – como texto, movimento de câmera, identidade e profundidade – são primeiro convertidas em um formato de token unificado. Esses tokens são então concatenados em uma única sequência longa, que é processada através de um conjunto de camadas de transformadores usando atenção total. Essa abordagem segue trabalhos anteriores como Open-Sora Plan e Movie Gen.
Esse design permite que o modelo aprenda as relações temporais e espaciais de forma conjunta entre todas as condições. Cada bloco transformador opera sobre toda a sequência, permitindo interações dinâmicas entre modalidades sem depender de módulos separados para cada entrada – e, como observamos, a arquitetura foi projetada para ser extensível, tornando muito mais fácil incorporar sinais de controle adicionais no futuro, sem alterações estruturais significativas.
O Poder dos Três
O FullDiT converte cada sinal de controle em um formato de token padronizado para que todas as condições possam ser processadas juntas em uma estrutura de atenção unificada. Para o movimento da câmera, o modelo codifica uma sequência de parâmetros extrínsecos – como posição e orientação – para cada quadro. Esses parâmetros são temporizados e projetados em vetores de embedding que refletem a natureza temporal do sinal.
As informações de identidade são tratadas de forma diferente, pois são inerentemente espaciais em vez de temporais. O modelo usa mapas de identidade que indicam quais personagens estão presentes em quais partes de cada quadro. Esses mapas são divididos em patches, e cada patch é projetado em um embedding que captura pistas de identidade espacial, permitindo que o modelo associe regiões específicas do quadro a entidades específicas.
A profundidade é um sinal espaçotemporal, e o modelo a trata dividindo vídeos de profundidade em patches 3D que abrangem espaço e tempo. Esses patches são então embutidos de uma maneira que preserva sua estrutura entre quadros.
Uma vez embutidos, todos esses tokens de condição (câmera, identidade e profundidade) são concatenados em uma longa sequência, permitindo que o FullDiT os processe juntos usando atenção total. Essa representação compartilhada torna possível para o modelo aprender interações entre modalidades e ao longo do tempo sem depender de fluxos de processamento isolados.
Dados e Testes
A abordagem de treinamento do FullDiT confiou em conjuntos de dados seletivamente anotados voltados para cada tipo de condicionamento, em vez de exigir que todas as condições estivessem presentes simultaneamente.
Para condições textuais, a iniciativa segue a abordagem de legendagem estruturada descrita no projeto MiraData.

Pipeline de coleção e anotação de vídeo do projeto MiraData. Fonte: https://arxiv.org/pdf/2407.06358
Para movimento de câmera, o conjunto de dados RealEstate10K foi a principal fonte de dados, devido às suas anotações de parâmetros de câmera de alta qualidade.
No entanto, os autores observaram que o treinamento exclusivamente em conjuntos de dados de cena estática, como o RealEstate10K, tendia a reduzir movimentos dinâmicos de objetos e humanos nos vídeos gerados. Para contornar isso, eles realizaram um ajuste fino adicional usando conjuntos de dados internos que incluíam movimentos de câmera mais dinâmicos.
Anotações de identidade foram geradas usando o pipeline desenvolvido para o projeto ConceptMaster, que permitiu filtragem e extração eficientes de informações de identidade detalhadas.

O framework ConceptMaster é projetado para lidar com questões de desacoplamento de identidade enquanto preserva a fidelidade do conceito em vídeos personalizados. Fonte: https://arxiv.org/pdf/2501.04698
Anotações de profundidade foram obtidas do conjunto de dados Panda-70M usando Depth Anything.
Otimização por meio de Ordenação de Dados
Os autores também implementaram um cronograma de treinamento progressivo, introduzindo condições mais desafiadoras mais cedo no treinamento para garantir que o modelo adquirisse representações robustas antes que tarefas mais simples fossem adicionadas. A ordem de treinamento procedeu de texto para condições de câmera, depois identidades e, finalmente, profundidade, com tarefas mais fáceis geralmente apresentadas mais tarde e com menos exemplos.
Os autores enfatizam o valor de ordenar a carga de trabalho dessa maneira:
‘Durante a fase de pré-treinamento, notamos que tarefas mais desafiadoras demandam tempo de treinamento estendido e devem ser introduzidas mais cedo no processo de aprendizado. Essas tarefas desafiadoras envolvem distribuições de dados complexas que diferem significativamente do vídeo de saída, exigindo que o modelo possua capacidade suficiente para capturá-las e representá-las adequadamente.’
‘Por outro lado, introduzir tarefas mais fáceis muito cedo pode levar o modelo a priorizar seu aprendizado, pois proporcionam um feedback de otimização mais imediato, o que prejudica a convergência de tarefas mais desafiadoras.’
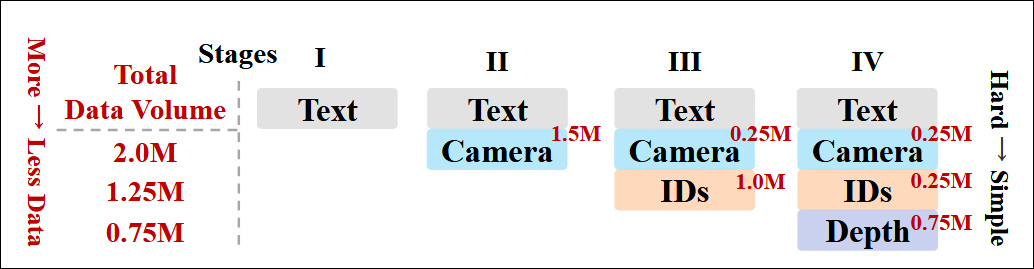
Uma ilustração da ordem de treinamento de dados adotada pelos pesquisadores, com vermelho indicando maior volume de dados.
Após o pré-treinamento inicial, uma fase final de ajuste fino refinou ainda mais o modelo para melhorar a qualidade visual e a dinâmica de movimento. Depois, o treinamento seguiu o de um framework de difusão padrão*: ruído adicionado a latentes de vídeo, e o modelo aprendendo a prever e remover esse ruído, usando os tokens de condição embutidos como guia.
Para avaliar efetivamente o FullDiT e fornecer uma comparação justa com métodos existentes, e na ausência da disponibilidade de qualquer benchmark apropriado, os autores introduziram FullBench, um conjunto de benchmarks curados que consiste em 1.400 casos de teste distintos.
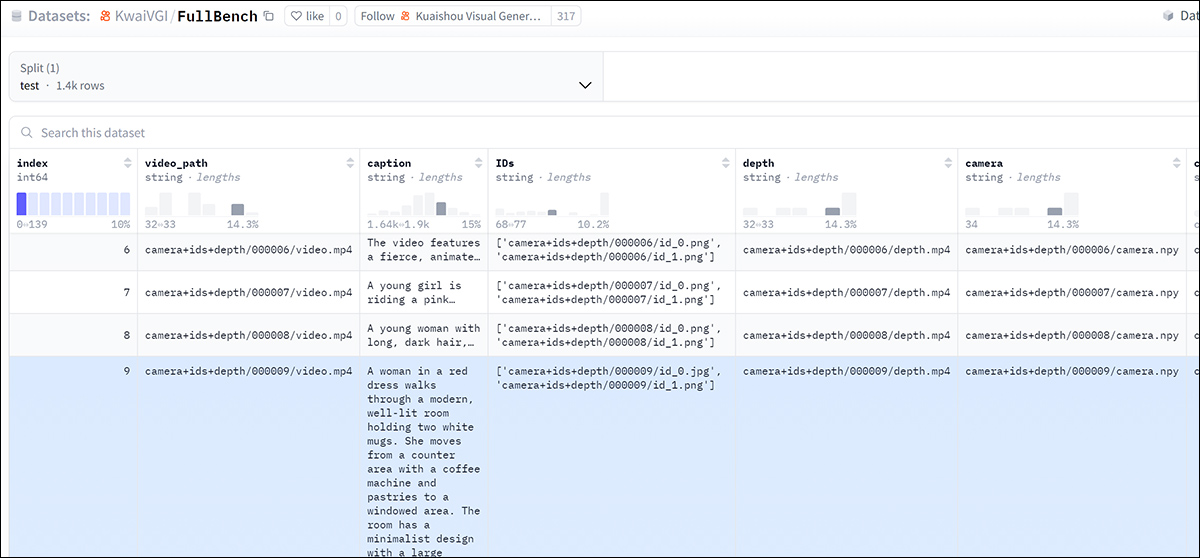
Uma instância do explorador de dados para o novo benchmark FullBench. Fonte: https://huggingface.co/datasets/KwaiVGI/FullBench
Cada ponto de dados fornecia anotações de verdade de solo para vários sinais de condicionamento, incluindo movimento de câmera, identidade e profundidade.
Métricas
Os autores avaliaram o FullDiT usando dez métricas cobrindo cinco aspectos principais de desempenho: alinhamento de texto, controle de câmera, similaridade de identidade, precisão de profundidade e qualidade geral do vídeo.
O alinhamento de texto foi medido usando similaridade CLIP, enquanto o controle da câmera foi avaliado por meio de erro de rotação (RotErr), erro de tradução (TransErr) e consistência de movimento da câmera (CamMC), seguindo a abordagem de CamI2V (no projeto CameraCtrl).
A similaridade de identidade foi avaliada usando DINO-I e CLIP-I, e a precisão do controle de profundidade foi quantificada usando Erro Absoluto Médio (MAE).
A qualidade do vídeo foi avaliada com três métricas do MiraData: similaridade CLIP em nível de quadro para suavidade; distância de movimento baseada em fluxo óptico para dinâmica; e pontuações estéticas LAION para apelo visual.
Treinamento
Os autores treinaram o FullDiT usando um modelo interno (não divulgado) de difusão de texto-para-vídeo contendo aproximadamente um bilhão de parâmetros. Eles escolheram intencionalmente um tamanho de parâmetro modesto para manter a equidade nas comparações com métodos anteriores e garantir a reprodutibilidade.
Uma vez que os vídeos de treinamento diferiam em duração e resolução, os autores padronizaram cada batch redimensionando e preenchendo os vídeos para uma resolução comum, amostrando 77 quadros por sequência e usando máscaras de atenção e máscaras de perda para otimizar a eficácia do treinamento.
O otimizador Adam foi utilizado a uma taxa de aprendizado de 1×10−5 em um cluster de 64 GPUs NVIDIA H800, para um total combinado de 5.120GB de VRAM (considerando que nas comunidades de síntese entusiasta, 24GB em uma RTX 3090 ainda é considerado um padrão luxuoso).
O modelo foi treinado por cerca de 32.000 etapas, incorporando até três identidades por vídeo, junto com 20 quadros de condições de câmera e 21 quadros de condições de profundidade, ambos uniformemente amostrados do total de 77 quadros.
Para inferência, o modelo gerou vídeos em uma resolução de 384×672 pixels (cerca de cinco segundos a 15 quadros por segundo) com 50 etapas de difusão de inferência e uma escala de orientação sem classificador de cinco.
Métodos Anteriores
Para avaliação de câmera-para-vídeo, os autores compararam o FullDiT com MotionCtrl, CameraCtrl e CamI2V, com todos os modelos treinados usando o conjunto de dados RealEstate10k para garantir consistência e equidade.
Na geração condicionada por identidade, como não estavam disponíveis modelos multi-identidade de código aberto comparáveis, o modelo foi avaliado contra o modelo ConceptMaster de 1B parâmetros, usando os mesmos dados de treinamento e arquitetura.
Para tarefas de profundidade-para-vídeo, as comparações foram feitas com Ctrl-Adapter e ControlVideo.
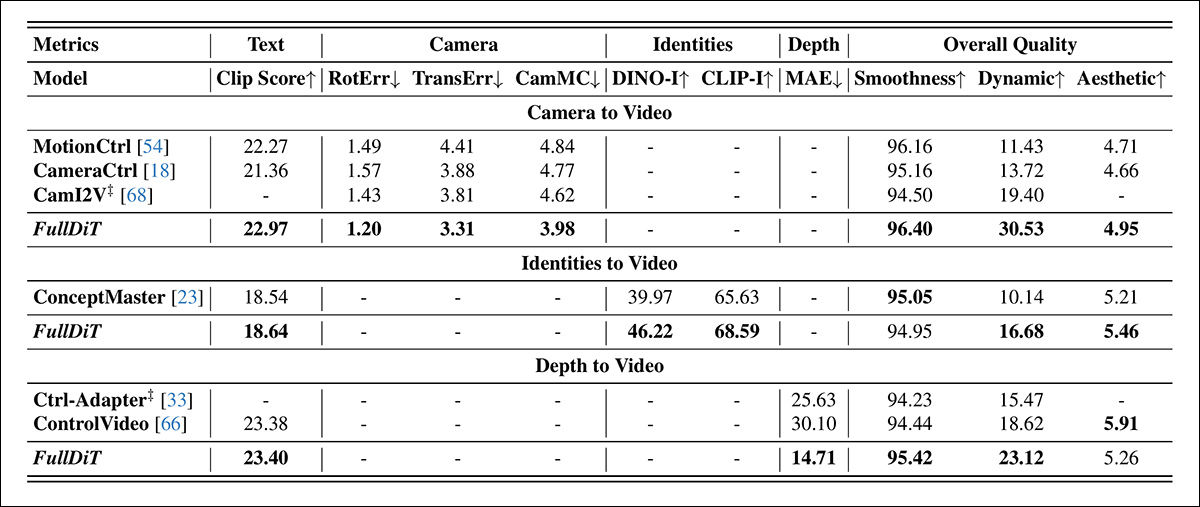
Resultados quantitativos para geração de vídeo de tarefa única. O FullDiT foi comparado com MotionCtrl, CameraCtrl e CamI2V para geração de câmera-para-vídeo; ConceptMaster (versão de 1B parâmetros) para identidade-para-vídeo; e Ctrl-Adapter e ControlVideo para profundidade-para-vídeo. Todos os modelos foram avaliados usando suas configurações padrão. Para consistência, 16 quadros foram amostrados uniformemente de cada método, correspondendo ao comprimento de saída de modelos anteriores.
Os resultados indicam que o FullDiT, apesar de manusear múltiplos sinais de condicionamento simultaneamente, alcançou desempenho de ponta em métricas relacionadas ao texto, movimento da câmera, identidade e controles de profundidade.
Em métricas de qualidade geral, o sistema geralmente superou outros métodos, embora sua suavidade fosse ligeiramente inferior à do ConceptMaster. Aqui os autores comentam:
‘A suavidade do FullDiT é ligeiramente inferior à do ConceptMaster, uma vez que o cálculo de suavidade é baseado na similaridade CLIP entre quadros adjacentes. Como o FullDiT apresenta dinâmicas significativamente maiores em comparação com o ConceptMaster, a métrica de suavidade é impactada pelas grandes variações entre quadros adjacentes.’
‘Para a pontuação estética, já que o modelo de avaliação favorece imagens em estilo de pintura e o ControlVideo geralmente gera vídeos nesse estilo, ele atinge uma alta pontuação em estética.’
Sobre a comparação qualitativa, pode ser preferível direcionar para os vídeos de amostra no site do projeto FullDiT, já que os exemplos em PDF são inevitavelmente estáticos (e também muito grandes para reproduzir completamente aqui).

A primeira seção dos resultados qualitativos reproduzidos no PDF. Consulte o documento fonte para os exemplos adicionais, que são extensos demais para reproduzir aqui.
Os autores comentam:
‘O FullDiT demonstra preservação superior de identidade e gera vídeos com melhores dinâmicas e qualidade visual em comparação com o [ConceptMaster]. Como o ConceptMaster e o FullDiT são treinados na mesma base, isso ressalta a eficácia da injeção de condição com atenção total.’
‘… Os [outros] resultados demonstram a superior controlabilidade e qualidade de geração do FullDiT em comparação com métodos existentes de profundidade-para-vídeo e câmera-para-vídeo.’

Uma seção dos exemplos do PDF da saída do FullDiT com múltiplos sinais. Consulte o documento fonte e o site do projeto para exemplos adicionais.
Conclusão
Embora o FullDiT seja uma empolgante incursão em um tipo de modelo de fundação de vídeo mais completo, deve-se questionar se a demanda por funcionalidades do tipo ControlNet algum dia justificará a implementação de tais recursos em escala, pelo menos para projetos FOSS, que teriam dificuldade em obter a enorme quantidade de poder de processamento GPU necessária, sem o apoio comercial.
O principal desafio é que usar sistemas como Profundidade e Pose geralmente exige familiaridade não trivial com interfaces de usuário relativamente complexas, como a ComfyUI. Portanto, parece que um modelo funcional FOSS desse tipo é mais provável de ser desenvolvido por um grupo de pequenas empresas de VFX que não têm o dinheiro (ou a vontade, dado que tais sistemas rapidamente se tornam obsoletos com atualizações de modelos) para curar e treinar um modelo em segredo.
Por outro lado, sistemas baseados em API que oferecem “aluguel de IA” podem estar bem motivados para desenvolver métodos mais simples e amigáveis de interpretação para modelos nos quais sistemas de controle auxiliares foram treinados diretamente.
Clique para reproduzir. Controles de Profundidade+Texto impostos a uma geração de vídeo usando o FullDiT.
* Os autores não especificam nenhum modelo base conhecido (ou seja, SDXL, etc.)
Publicado pela primeira vez na quinta-feira, 27 de março de 2025

Conteúdo relacionado

CEO da Perplexity nega ter problemas financeiros e afirma que não haverá IPO antes de 2028.
[the_ad id="145565"] Perplexity O CEO da Perplexity, Aravind Srinivas, recentemente recorreu ao Reddit para abordar as reclamações dos usuários sobre o produto e…

Apple estaria reformulando o app Saúde para incluir um treinador de IA.
[the_ad id="145565"] A Apple está desenvolvendo uma nova versão de seu aplicativo de Saúde que inclui um coach de IA que pode aconselhar os usuários sobre como melhorar sua…

Os modelos de IA mais inovadores: o que fazem e como utilizá-los
[the_ad id="145565"] Modelos de IA estão sendo produzidos a um ritmo alucinante, por todos, desde grandes empresas de tecnologia como Google até startups como OpenAI e…