


A Geração Aumentada por Recuperação (RAG) é uma abordagem para construir sistemas de IA que combina um modelo de linguagem com uma fonte de conhecimento externa. Em termos simples, a IA primeiro busca por documentos relevantes (como artigos ou páginas da web) relacionados à consulta de um usuário e, em seguida, usa esses documentos para gerar uma resposta mais precisa. Este método tem sido elogiado por ajudar grandes modelos de linguagem (LLMs) a se manterem factuais e reduzir alucinações, fundamentando suas respostas em dados reais.
Intuitivamente, pode-se pensar que quanto mais documentos uma IA recupera, mais informada estará sua resposta. No entanto, pesquisas recentes sugerem uma reviravolta surpreendente: quando se trata de alimentar informações para uma IA, às vezes menos é mais.
Menos Documentos, Melhores Respostas
Um novo estudo realizado por pesquisadores da Universidade Hebraica de Jerusalém explorou como a quantidade de documentos fornecidos a um sistema RAG afeta seu desempenho. Crucialmente, eles mantiveram a quantidade total de texto constante – o que significa que, se menos documentos fossem fornecidos, esses documentos eram ligeiramente expandidos para preencher o mesmo comprimento que muitos documentos preencheriam. Dessa forma, quaisquer diferenças de desempenho poderiam ser atribuídas à quantidade de documentos, em vez de simplesmente ter uma entrada mais curta.
Os pesquisadores usaram um conjunto de dados de perguntas e respostas (MuSiQue) com perguntas de trivia, cada uma originalmente emparelhada com 20 parágrafos da Wikipedia (apenas alguns dos quais realmente contêm a resposta, com o resto sendo distrações). Ao reduzir o número de documentos de 20 para apenas os 2 a 4 verdadeiramente relevantes – e preenchendo-os com um pouco de contexto extra para manter um comprimento consistente – eles criaram cenários nos quais a IA tinha menos materiais a considerar, mas ainda assim aproximadamente as mesmas palavras totais para ler.
Os resultados foram impressionantes. Na maioria dos casos, os modelos de IA responderam de forma mais precisa quando receberam menos documentos, em vez do conjunto completo. O desempenho melhorou significativamente – em algumas instâncias, a precisão aumentou em até 10% (pontuação F1) quando o sistema utilizou apenas um punhado de documentos de suporte em vez de uma grande coleção. Esse aumento contra-intuitivo foi observado em vários modelos de linguagem de código aberto diferentes, incluindo variantes do Llama da Meta e outros, indicando que o fenômeno não está atrelado a um único modelo de IA.
Um modelo (Qwen-2) foi uma exceção notável que lidou com múltiplos documentos sem queda na pontuação, mas quase todos os modelos testados tiveram um desempenho melhor com menos documentos no geral. Em outras palavras, adicionar mais material de referência além das peças-chave relevantes prejudicou mais vezes seu desempenho do que ajudou.
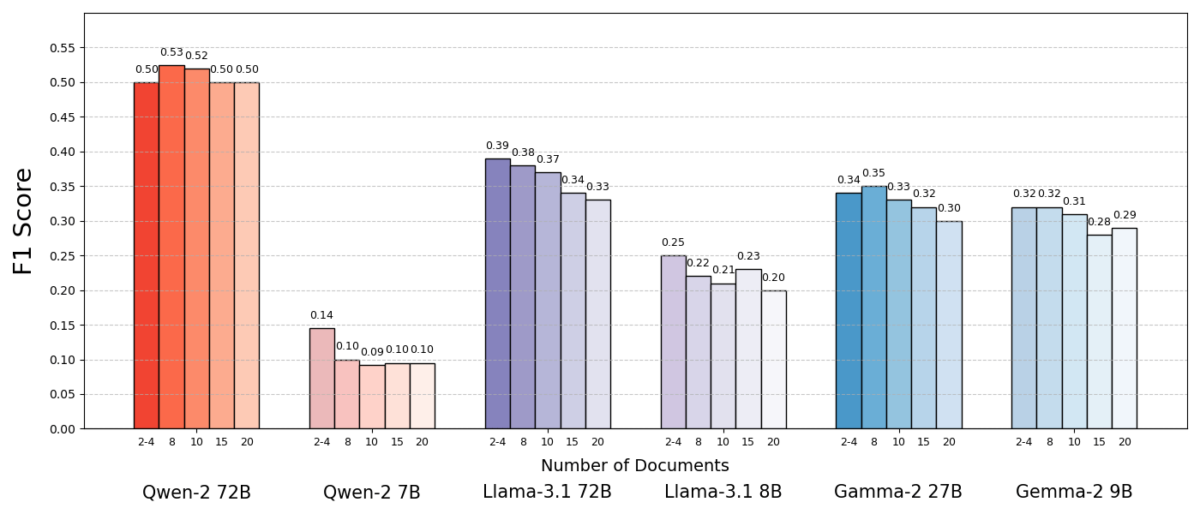
Fonte: Levy et al.
Por que isso é uma surpresa? Normalmente, os sistemas RAG são projetados com a suposição de que recuperar uma gama mais ampla de informações só pode ajudar a IA – afinal, se a resposta não estiver nos primeiros documentos, pode estar no décimo ou vigésimo.
Este estudo inverte essa lógica, demonstrando que acumular documentos extra sem critério pode ser contraproducente. Mesmo quando o comprimento total do texto foi mantido constante, a mera presença de muitos documentos diferentes (cada um com seu próprio contexto e peculiaridades) tornava a tarefa de perguntas e respostas mais desafiadora para a IA. Parece que além de um certo ponto, cada documento adicional introduziu mais ruído do que sinal, confundindo o modelo e prejudicando sua capacidade de extrair a resposta correta.
Por que Menos Pode Ser Mais no RAG
Esse resultado de “menos é mais” faz sentido uma vez que consideramos como os modelos de linguagem da IA processam informações. Quando uma IA recebe apenas os documentos mais relevantes, o contexto que ela vê é focado e livre de distrações, muito parecido com um estudante que recebeu apenas as páginas certas para estudar.
No estudo, os modelos tiveram um desempenho significativamente melhor quando receberam apenas os documentos de suporte, com material irrelevante removido. O contexto restante era não apenas mais curto, mas também mais limpo – continha fatos que apontavam diretamente para a resposta e nada mais. Com menos documentos para acomodar, o modelo poderia dedicar toda a sua atenção às informações pertinentes, fazendo com que fosse menos provável que se distraísse ou se confundisse.
Por outro lado, quando muitos documentos foram recuperados, a IA teve que passar por uma mistura de conteúdos relevantes e irrelevantes. Muitas vezes, esses documentos extras eram “similares, mas não relacionados” – podiam compartilhar um tópico ou palavras-chave com a consulta, mas não necessariamente conter a resposta. Esse tipo de conteúdo pode enganar o modelo. A IA pode desperdiçar esforço tentando conectar pontos entre documentos que não levam a uma resposta correta ou, pior, pode fundir informações de múltiplas fontes de maneira incorreta. Isso aumenta o risco de alucinações – instâncias em que a IA gera uma resposta que soa plausível, mas não está fundamentada em nenhuma fonte única.
Em essência, alimentar muitos documentos ao modelo pode diluir a informação útil e introduzir detalhes conflitantes, tornando mais difícil para a IA decidir o que é verdade.
Curiosamente, os pesquisadores descobriram que se os documentos extras fossem obviamente irrelevantes (por exemplo, texto aleatório não relacionado), os modelos eram melhores em ignorá-los. O verdadeiro problema surge dos dados distraentes que parecem relevantes: quando todos os textos recuperados estão em tópicos semelhantes, a IA assume que deve usar todos eles e pode ter dificuldade em discernir quais detalhes são realmente importantes. Isso está alinhado com a observação do estudo de que distratores aleatórios causaram menos confusão do que distratores realistas na entrada. A IA pode filtrar a besteira evidente, mas informações sutilmente fora do tópico são uma armadilha furtiva – entram disfarçadas de relevância e desvia a resposta. Ao reduzir o número de documentos para apenas os verdadeiramente necessários, evitamos estabelecer essas armadilhas desde o início.
Há também um benefício prático: recuperar e processar menos documentos reduz a sobrecarga computacional para um sistema RAG. Cada documento que é puxado precisa ser analisado (embarcado, lido e considerado pelo modelo), o que utiliza tempo e recursos computacionais. Eliminar documentos supérfluos torna o sistema mais eficiente – ele pode encontrar respostas mais rápido e a um custo menor. Em cenários onde a precisão melhorou ao se concentrar em menos fontes, temos uma vitória dupla: respostas melhores e um processo mais enxuto e eficiente.

Fonte: Levy et al.
Repensando o RAG: Direções Futuras
Essas novas evidências de que a qualidade muitas vezes supera a quantidade na recuperação têm importantes implicações para o futuro dos sistemas de IA que dependem de conhecimento externo. Sugere que os projetistas de sistemas RAG devem priorizar a filtragem e a classificação inteligentes de documentos em vez de apenas volume. Em vez de buscar 100 trechos possíveis e esperar que a resposta esteja lá, pode ser mais sábio buscar apenas os poucos altamente relevantes.
Os autores do estudo enfatizam a necessidade de métodos de recuperação que “encontrem um equilíbrio entre relevância e diversidade” nas informações que fornecem a um modelo. Em outras palavras, queremos fornecer cobertura suficiente do tópico para responder à pergunta, mas não tanto que os fatos essenciais sejam afogados em um mar de texto irrelevante.
No futuro, os pesquisadores provavelmente explorarão técnicas que ajudem os modelos de IA a lidar com múltiplos documentos de maneira mais elegante. Uma abordagem é desenvolver sistemas de recuperação ou reclassificadores melhores que possam identificar quais documentos realmente agregam valor e quais apenas introduzem conflito. Outra abordagem é melhorar os próprios modelos de linguagem: se um modelo (como o Qwen-2) conseguiu lidar com muitos documentos sem perder precisão, examinar como ele foi treinado ou estruturado poderia oferecer pistas para tornar outros modelos mais robustos. Talvez os futuros grandes modelos de linguagem incorporem mecanismos para reconhecer quando duas fontes estão dizendo a mesma coisa (ou se contradizendo) e se concentrar de acordo. O objetivo seria permitir que os modelos utilizem uma variedade rica de fontes sem se deixar confundir – efetivamente obtendo o melhor de ambos os mundos (abrangência da informação e clareza de foco).
Vale também ressaltar que à medida que os sistemas de IA ganham janelas de contexto maiores (a capacidade de ler mais texto de uma vez), simplesmente despejar mais dados no prompt não é uma solução mágica. Um contexto maior não significa automaticamente uma melhor compreensão. Este estudo mostra que mesmo que uma IA possa tecnicamente ler 50 páginas de cada vez, dar a ela 50 páginas de informações de qualidade mista pode não gerar um bom resultado. O modelo ainda se beneficia de ter conteúdo curado e relevante para trabalhar, em vez de um despejo indiscriminado. De fato, a recuperação inteligente pode se tornar ainda mais crucial na era das janelas de contexto gigantes – para garantir que a capacidade extra seja utilizada para conhecimento valioso em vez de ruído.
Os achados de “Mais Documentos, Mesmo Comprimento” (o título apropriadamente nomeado do artigo) incentivam uma reexame de nossas suposições na pesquisa em IA. Às vezes, alimentar uma IA com todos os dados que temos não é tão eficaz quanto pensamos. Ao nos concentrarmos nas peças de informação mais relevantes, não apenas melhoramos a precisão das respostas geradas pela IA, mas também tornamos os sistemas mais eficientes e mais fáceis de confiar. É uma lição contra-intuitiva, mas com ramificações empolgantes: os futuros sistemas RAG podem ser tanto mais inteligentes quanto mais enxutos ao escolher cuidadosamente menos, mas melhores documentos para recuperar.

Conteúdo relacionado

O novo jogo da Tinder com inteligência artificial avalia suas habilidades de conquista
[the_ad id="145565"] Você sabe que a cena de namoro online está ruim quando gigantes do setor, como o Tinder, estão introduzindo personas de IA para os usuários flertarem. Na…

Qualcomm adquire divisão de IA generativa da startup vietnamita VinAI
[the_ad id="145565"] A Qualcomm adquiriu a divisão de IA generativa da VinAI, uma empresa de pesquisa em IA com sede em Hanói, por um valor não revelado, conforme anunciado…

Sam Altman afirma que os problemas de capacidade da OpenAI causarão atrasos nos produtos.
[the_ad id="145565"] Em uma série de publicações no X na segunda-feira, o CEO da OpenAI, Sam Altman, afirmou que a popularidade da nova ferramenta de geração de imagens no…