


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre AI líder de mercado. Saiba Mais
O lançamento do Gemini 2.5 Pro na terça-feira não exatamente dominou o ciclo de notícias. Ele chegou na mesma semana em que a atualização de geração de imagens da OpenAI agitou as redes sociais com avatares inspirados no Studio Ghibli e renders instantâneos impressionantes. Mas enquanto o burburinho foi para a OpenAI, o Google pode ter lançado discretamente o modelo de raciocínio mais preparado para empresas até hoje.
O Gemini 2.5 Pro representa um avanço significativo para o Google na corrida dos modelos fundamentais – não apenas em benchmarks, mas em usabilidade. Com base em experimentos iniciais, dados de benchmark e reações de desenvolvedores, é um modelo que merece atenção séria de tomadores de decisão técnica em empresas, especialmente aqueles que historicamente tinham o OpenAI ou Claude como opções padrão para raciocínio de nível produtivo.
Aqui estão quatro principais conclusões para equipes de empresas avaliando o Gemini 2.5 Pro.
1. Raciocínio transparente e estruturado – um novo padrão para clareza no raciocínio encadeado
O que distingue o Gemini 2.5 Pro não é apenas sua inteligência – é como essa inteligência demonstra seu trabalho. A abordagem de treinamento passo a passo do Google resulta em uma cadeia de pensamento estruturada (CoT) que não parece divagar ou adivinhar, como vimos em modelos como o DeepSeek. E essas CoTs não são resumidas em sumários superficiais, como se vê nos modelos da OpenAI. O novo modelo Gemini apresenta ideias em etapas numeradas, com sub-itens e uma lógica interna que é notavelmente coerente e transparente.
Em termos práticos, isso é uma revolução para confiança e direcionamento. Usuários empresariais que avaliam a saída para tarefas críticas – como revisar implicações de políticas, lógica de codificação ou resumir pesquisas complexas – agora podem ver como o modelo chegou a uma resposta. Isso significa que eles podem validar, corrigir ou redirecionar suas ações com mais confiança. É uma evolução significativa em relação à sensação de “black box” que ainda aflige muitas saídas de LLM.
Para uma demonstração mais detalhada de como isso funciona na prática, assista ao vídeo onde testamos o Gemini 2.5 Pro ao vivo. Um exemplo que discutimos: Quando questionado sobre as limitações dos grandes modelos de linguagem, o Gemini 2.5 Pro demonstrou uma notável percepção. Ele recitou fraquezas comuns e as categorizou em áreas como “intuição física”, “síntese de conceitos novos”, “planejamento de longo prazo” e “nuances éticas”, fornecendo uma estrutura que ajuda os usuários a entender o que o modelo sabe e como ele está abordando o problema.
Equipes técnicas empresariais podem aproveitar essa capacidade para:
- Depurar cadeias de raciocínio complexas em aplicações críticas
- Compreender melhor as limitações do modelo em domínios específicos
- Proporcionar um processo de tomada de decisão assistido por IA mais transparente para as partes interessadas
- Aprimorar seu próprio pensamento crítico estudando a abordagem do modelo
Uma limitação que vale a pena mencionar: Embora esse raciocínio estruturado esteja disponível no aplicativo Gemini e no Google AI Studio, ainda não está acessível via API – uma deficiência para desenvolvedores que buscam integrar essa capacidade em aplicações empresariais.
2. Um verdadeiro concorrente de ponta – não apenas no papel
O modelo atualmente está no topo da tabela de classificação do Chatbot Arena por uma margem notável – 35 pontos Elo à frente do próximo melhor modelo – que é a atualização OpenAI 4o lançada no dia seguinte ao lançamento do Gemini 2.5 Pro. E enquanto a supremacia em benchmarks muitas vezes é uma coroa passageira (já que novos modelos são lançados semanalmente), o Gemini 2.5 Pro parece genuinamente diferente.
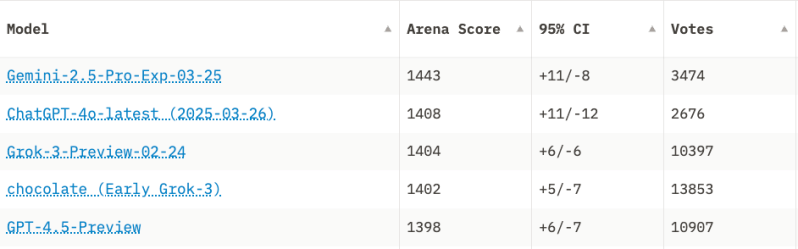
Ele se destaca em tarefas que premiam raciocínio profundo: codificação, resolução de problemas sutis, síntese de documentos e até planejamento abstrato. Em testes internos, ele se saiu especialmente bem em benchmarks anteriormente difíceis de decifrar, como o “Exame Final da Humanidade”, um favorito para expor fraquezas de LLM em domínios abstratos e sutis. (Você pode ver o anúncio do Google aqui, juntamente com todas as informações de benchmark.)
As equipes empresariais podem não se importar qual modelo ganha qual tabela acadêmica. Mas elas se importarão com o fato de que este pode pensar – e mostrar como está pensando. A prova de vibe é importante, e pela primeira vez, é a vez do Google se sentir como se tivesse passado.
Como o respeitado engenheiro de IA Nathan Lambert observou, “O Google tem os melhores modelos novamente, como deveria ter começado toda essa explosão da IA. O erro estratégico foi corrigido.” Usuários empresariais devem ver isso não apenas como o Google alcançando concorrentes, mas potencialmente ultrapassando-os em capacidades que importam para aplicações empresariais.
3. Finalmente: O jogo de codificação do Google é forte
Historicamente, o Google ficou atrás da OpenAI e Anthropic quando se trata de assistência de codificação centrada no desenvolvedor. O Gemini 2.5 Pro muda isso – de uma maneira significativa.
Em testes práticos, demonstrou uma forte capacidade de execução em desafios de codificação, incluindo a criação de um jogo Tetris funcionando que rodou na primeira tentativa ao ser exportado para o Replit – sem necessidade de depuração. Ainda mais notável: ele raciocinou sobre a estrutura do código com clareza, rotulando variáveis e etapas de maneira cuidadosa, e expondo sua abordagem antes de escrever uma única linha de código.
O modelo rivaliza com o Claude 3.7 Sonnet da Anthropic, que tem sido considerado o líder em geração de código, e um motivo importante para o sucesso da Anthropic no setor empresarial. Mas o Gemini 2.5 oferece uma vantagem crítica: uma janela de contexto massiva de 1 milhão de tokens. O Claude 3.7 Sonnet está apenas agora começando a oferecer 500.000 tokens.
Essa imensa janela de contexto abre novas possibilidades para raciocínio em toda a base de código, leitura de documentação em linha e trabalho em vários arquivos interdependentes. A experiência do engenheiro de software Simon Willison ilustra essa vantagem. Ao usar o Gemini 2.5 Pro para implementar um novo recurso em sua base de código, o modelo identificou as alterações necessárias em 18 arquivos diferentes e completou o projeto inteiro em aproximadamente 45 minutos – uma média de menos de três minutos por arquivo modificado. Para empresas experimentando frameworks de agentes ou ambientes de desenvolvimento assistido por IA, esta é uma ferramenta séria.
4. Integração multimodal com comportamento semelhante ao de agentes
Embora alguns modelos, como o mais recente 4o da OpenAI, possam mostrar mais brilho com geração de imagens chamativa, o Gemini 2.5 Pro parece estar redefinindo discretamente como o raciocínio multimodal fundamentado se apresenta.
Em um exemplo, o teste prático de Ben Dickson para o VentureBeat demonstrou a capacidade do modelo de extrair informações chave de um artigo técnico sobre algoritmos de busca e criar um fluxograma SVG correspondente – melhorando posteriormente esse fluxograma quando lhe foi mostrada uma versão renderizada com erros visuais. Esse nível de raciocínio multimodal possibilita novos fluxos de trabalho que anteriormente não eram possíveis com modelos apenas de texto.
Em outro exemplo, o desenvolvedor Sam Witteveen enviou uma captura de tela simples de um mapa de Las Vegas e perguntou quais eventos do Google estavam acontecendo nas proximidades em 9 de abril (veja minuto 16:35 deste vídeo). O modelo identificou a localização, inferiu a intenção do usuário, pesquisou online (com o grounding ativado) e retornou detalhes precisos sobre o Google Cloud Next – incluindo datas, localização e citações. Tudo sem um framework de agente personalizado, apenas o modelo principal e a pesquisa integrada.
O modelo realmente raciocina sobre essa entrada multimodal, além de apenas analisá-la. E isso sugere como os fluxos de trabalho empresariais podem se parecer em seis meses: fazendo upload de documentos, diagramas, painéis – e tendo o modelo fazendo síntese significativa, planejamento ou ação com base no conteúdo.
Bônus: É apenas… útil
Embora não seja uma conclusão separada, vale a pena notar: Este é o primeiro lançamento do Gemini que tirou o Google do “pântano” dos LLM para muitos de nós. Versões anteriores nunca conseguiram entrar no uso diário, já que modelos como OpenAI ou Claude definiram a agenda. O Gemini 2.5 Pro parece diferente. A qualidade do raciocínio, a utilidade de longo contexto e os toques práticos de UX – como exportação para Replit e acesso ao Studio – tornam-no um modelo difícil de ignorar.
Ainda assim, é cedo. O modelo ainda não está no Vertex AI do Google Cloud, embora o Google tenha dito que isso está a caminho. Algumas perguntas sobre latência permanecem, especialmente com o processo de raciocínio mais profundo (com tantos tokens de pensamento sendo processados, o que isso significa para o tempo até o primeiro token?), e os preços ainda não foram divulgados.
Outra observação das minhas observações sobre sua capacidade de escrita: OpenAI e Claude ainda parecem ter uma vantagem na produção de prosa bem legível. O Gemini 2.5 parece muito estruturado e carece de um pouco da suavidade conversacional que os outros oferecem. Isso é algo que eu percebi que a OpenAI, em particular, tem se concentrado bastante ultimamente.
Mas para empresas que equilibram desempenho, transparência e escala, o Gemini 2.5 Pro pode ter acabado de tornar o Google um sério concorrente novamente.
Como afirmou o CTO da Zoom, Xuedong Huang, em uma conversa comigo ontem: o Google continua firme na competição quando se trata de LLMs em produção. O Gemini 2.5 Pro apenas nos deu uma razão para acreditar que isso pode ser mais verdade amanhã do que foi ontem.
Assista ao vídeo completo sobre as ramificações empresariais aqui:


Conteúdo relacionado

Pesquisadores sugerem que a OpenAI treinou modelos de IA com livros da O’Reilly que estão atrás de paywall.
[the_ad id="145565"] A OpenAI foi acusada por vários grupos de treinar sua IA com conteúdo protegido por direitos autorais sem permissão. Agora, um novo artigo de uma…

O novo jogo da Tinder com inteligência artificial avalia suas habilidades de conquista
[the_ad id="145565"] Você sabe que a cena de namoro online está ruim quando gigantes do setor, como o Tinder, estão introduzindo personas de IA para os usuários flertarem. Na…

Qualcomm adquire divisão de IA generativa da startup vietnamita VinAI
[the_ad id="145565"] A Qualcomm adquiriu a divisão de IA generativa da VinAI, uma empresa de pesquisa em IA com sede em Hanói, por um valor não revelado, conforme anunciado…