


Em 2019, a Presidente da Câmara dos Representantes dos EUA, Nancy Pelosi, foi alvo de um ataque direcionado e bastante rudimentar estilo deepfake, quando um vídeo real dela foi editado para fazê-la parecer bêbada – um incidente surreal que foi compartilhado várias milhões de vezes antes que a verdade sobre isso emergisse (e, potencialmente, após algum dano persistente ao seu capital político, causado por aqueles que não acompanharam a história).
Embora essa má representação tenha exigido apenas uma simples edição audiovisual, ao invés de qualquer IA, continua sendo um exemplo chave de como mudanças sutis na saída audiovisual real podem ter um efeito devastador.
Na época, a cena dos deepfakes era dominada pelos sistemas de substituição facial baseados em autoencoders que estrearam no final de 2017, e que não haviam melhorado significativamente em qualidade desde então. Esses sistemas iniciais teriam dificuldade em criar esse tipo de alterações pequenas, mas significativas, ou em buscar realisticamente linhas de pesquisa modernas, como a edição de expressões:
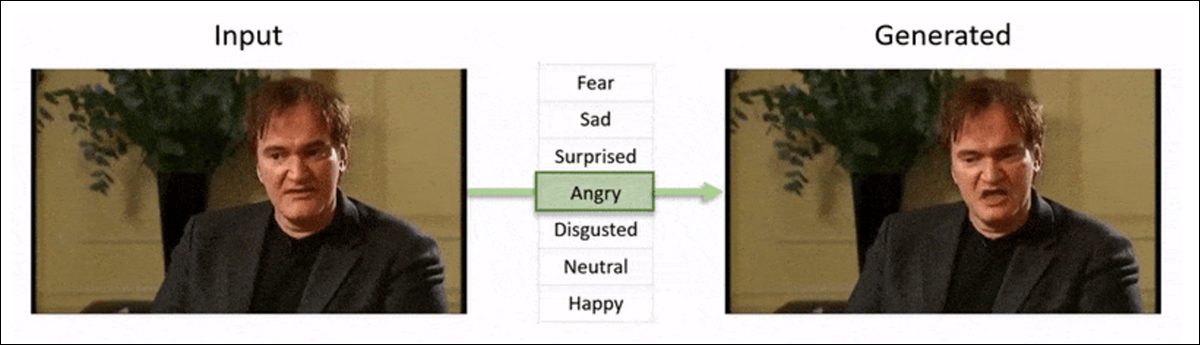
O framework ‘Neural Emotion Director’ de 2022 muda o humor de um rosto famoso. Fonte: https://www.youtube.com/watch?v=Li6W8pRDMJQ
As coisas agora são bastante diferentes. A indústria de cinema e TV está seriamente interessada na alteração pós-produção de performances reais utilizando abordagens de aprendizado de máquina, e a facilitação da IA para o perfeccionismo pós fato até recebeu críticas recentes.
Antecipando (ou argumentando que criando) essa demanda, a cena de pesquisa em síntese de imagem e vídeo lançou uma ampla gama de projetos que oferecem ‘edições locais’ de capturas faciais, em vez de substituições totais: projetos desse tipo incluem Diffusion Video Autoencoders; Stitch it in Time; ChatFace; MagicFace; e DISCO, entre outros.

Edição de expressões com o projeto MagicFace de janeiro de 2025. Fonte: https://arxiv.org/pdf/2501.02260
Novos rostos, novas nuances
No entanto, as tecnologias habilitadoras estão se desenvolvendo muito mais rapidamente do que os métodos para detectá-las. Quase todos os métodos de detecção de deepfake que surgem na literatura estão perseguindo métodos de deepfake de ontem com conjuntos de dados de ontem. Até esta semana, nenhum deles havia abordado o crescente potencial dos sistemas de IA para criar pequenas e tópicas alterações locais em vídeo.
Agora, um novo artigo da Índia corrigiu isso, com um sistema que busca identificar rostos que foram editados (em vez de substituídos) através de técnicas baseadas em IA:

Detecção de Edições Locais Sutis em Deepfakes: um vídeo real é alterado para produzir fakes com mudanças sutis, como sobrancelhas levantadas, traços de gênero modificados e mudanças na expressão para nojo (ilustrado aqui com um único quadro). Fonte: https://arxiv.org/pdf/2503.22121
O sistema dos autores visa identificar deepfakes que envolvem manipulações faciais sutis e localizadas – uma classe de falsificação que foi negligenciada. Em vez de se concentrar em inconsistências globais ou desvios de identidade, a abordagem se concentra em mudanças finas, como leves variações de expressão ou pequenas edições em características faciais específicas.
O método utiliza o delimitador de Unidades de Ação (AUs) no Sistema de Codificação de Ação Facial (FACS), que define 64 áreas individuais mutáveis no rosto, que juntas formam expressões.
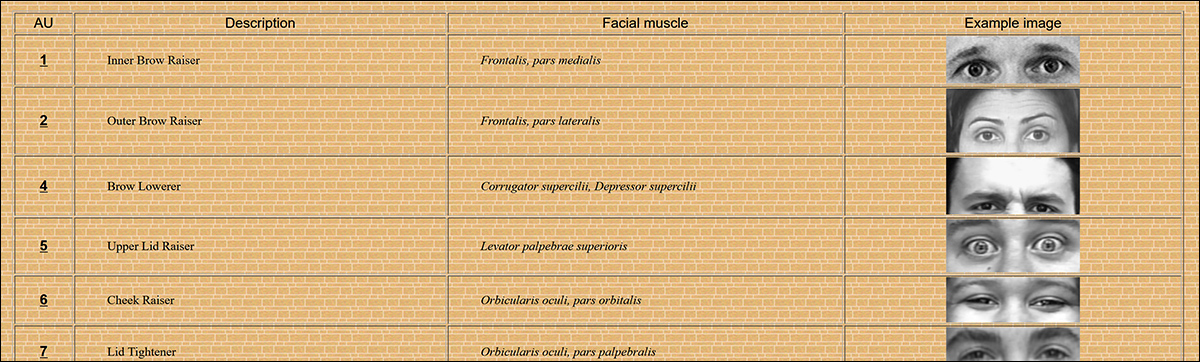
Algumas das 64 partes constitutivas da expressão no FACS. Fonte: https://www.cs.cmu.edu/~face/facs.htm
Os autores avaliaram sua abordagem em relação a uma variedade de métodos de edição recentes e relatam ganhos de desempenho consistentes, tanto com conjuntos de dados mais antigos quanto com vetores de ataque muito mais recentes:
‘Ao usar recursos baseados em AU para orientar representações de vídeo aprendidas através de Autoencoders Mascarados [(MAE)], nosso método captura efetivamente mudanças localizadas cruciais para a detecção de edições faciais sutis.
‘Essa abordagem nos permite construir uma representação latente unificada que codifica tanto edições localizadas quanto alterações mais amplas em vídeos centrados no rosto, proporcionando uma solução abrangente e adaptável para a detecção de deepfakes.’
O novo artigo tem o título Detectando Manipulações Localizadas de Deepfake Usando Representações de Vídeo Guiadas por Unidades de Ação e é de três autores do Instituto Indiano de Tecnologia em Madras.
Método
De acordo com a abordagem adotada pelo VideoMAE, o novo método começa aplicando a detecção facial a um vídeo e amostrando quadros espaçados uniformemente centrados nos rostos detectados. Esses quadros são então divididos em pequenas divisões 3D (ou seja, patches temporais), cada um capturando detalhes locais espaciais e temporais.
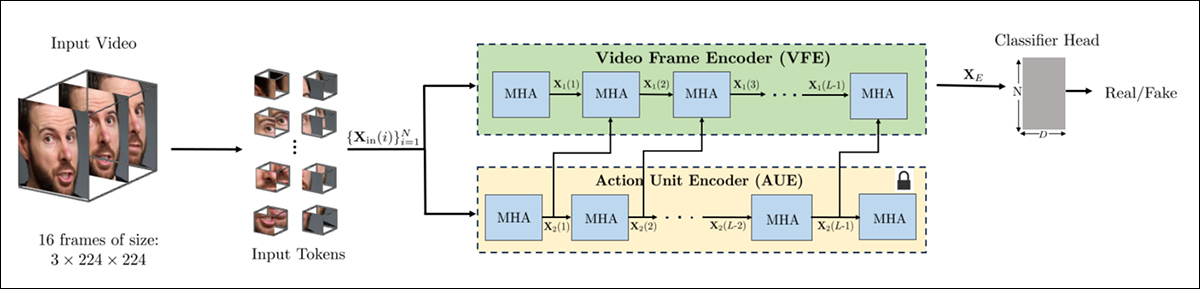
Esquema para o novo método. O vídeo de entrada é processado com detecção facial para extrair quadros espaçados uniformemente, centrados no rosto, que são então divididos em ‘patches’ tubulares e passados por um codificador que funde representações latentes de duas tarefas pré-treinadas. O vetor resultante é então usado por um classificador para determinar se o vídeo é real ou falso.
Cada patch 3D contém uma janela de pixels de tamanho fixo (ou seja, 16×16) de um pequeno número de quadros sucessivos (ou seja, 2). Isso permite que o modelo aprenda mudanças de movimento e expressão de curto prazo – não apenas como o rosto parece, mas como ele se move.
Os patches são incorporados e codificados positivamente antes de serem passados para um codificador projetado para extrair características que podem distinguir real de falso.
Os autores reconhecem que isso é particularmente difícil ao lidar com manipulações sutis e abordam essa questão construindo um codificador que combina dois tipos separados de representações aprendidas, usando um mecanismo de atenção cruzada para fundi-las. Isso é feito para produzir um espaço de recursos mais sensível e generalizável para detectar edições localizadas.
Tarefas Pretextuais
A primeira dessas representações é um codificador treinado com uma tarefa de autoencodagem mascarada. Com o vídeo dividido em patches 3D (a maior parte deles está oculta), o codificador aprende a reconstruir as partes faltantes, forçando-o a capturar padrões espaço-temporais importantes, como movimento facial ou consistência ao longo do tempo.
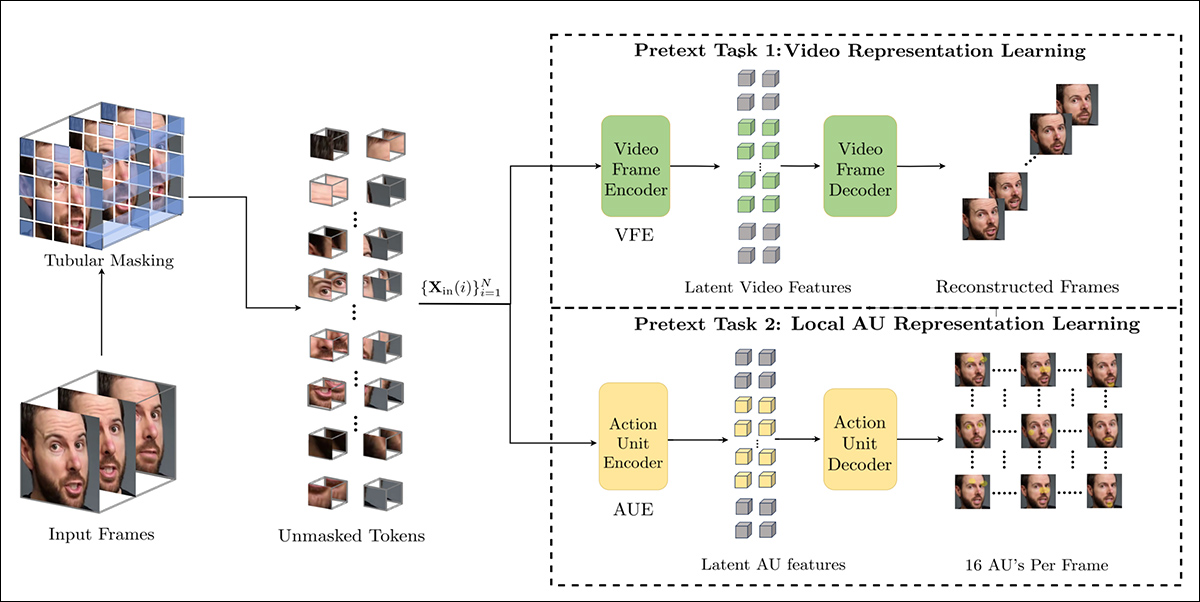
O treinamento da tarefa pré-textual envolve mascarar partes da entrada de vídeo e usar uma configuração de codificador-decodificador para reconstruir os quadros originais ou mapas de unidades de ação por quadro, dependendo da tarefa.
No entanto, como observa o artigo, isso sozinho não fornece sensibilidade suficiente para detectar edições finas, e os autores, portanto, introduzem um segundo codificador treinado para detectar unidades de ação faciais (AUs). Para essa tarefa, o modelo aprende a reconstruir mapas densos de AU para cada quadro, novamente a partir de entradas parcialmente mascaradas. Isso o incentiva a se concentrar na atividade muscular localizada, onde muitas edições sutis de deepfake ocorrem.

Mais exemplos de Unidades de Ação Faciais (FAUs, ou AUs). Fonte: https://www.eiagroup.com/the-facial-action-coding-system/
Após o pré-treinamento de ambos os codificadores, suas saídas são combinadas usando atenção cruzada. Em vez de simplesmente fundir os dois conjuntos de características, o modelo utiliza as características baseadas em AU como consultas que guiam a atenção sobre as características espaço-temporais aprendidas através da autoencodagem mascarada. Na prática, o codificador de unidades de ação indica ao modelo onde olhar.
O resultado é uma representação latente fundida que visa capturar tanto o contexto de movimento mais amplo quanto o detalhe de nível de expressão localizado. Esse espaço de características combinado é então utilizado para a tarefa de classificação final: prever se um vídeo é real ou manipulado.
Dados e Testes
Implementação
Os autores implementaram o sistema pré-processando vídeos de entrada com a estrutura de detecção facial FaceXZoo baseada em PyTorch, obtendo 16 quadros centrados no rosto de cada clipe. As tarefas pré-textuais descritas acima foram então treinadas no conjunto de dados CelebV-HQ, que consiste em 35.000 vídeos faciais de alta qualidade.

Do artigo de origem, exemplo do conjunto de dados CelebV-HQ usado no novo projeto. Fonte: https://arxiv.org/pdf/2207.12393
Metade dos exemplos de dados foram mascarados, forçando o sistema a aprender princípios gerais em vez de se sobreajustar aos dados originais.
Para a tarefa de reconstrução de quadros mascarados, o modelo foi treinado para prever regiões ausentes dos quadros de vídeo usando uma perda L1, minimizando a diferença entre o conteúdo original e reconstruído.
Para a segunda tarefa, o modelo foi treinado para gerar mapas para 16 unidades de ação faciais, cada uma representando movimentos sutis dos músculos em áreas como sobrancelhas, pálpebras, nariz e lábios, novamente supervisionado por perda L1.
Após o pré-treinamento, os dois codificadores foram fundidos e ajustados para a detecção de deepfake usando o conjunto de dados FaceForensics++, que contém tanto vídeos reais quanto manipulados.

O conjunto de dados FaceForensics++ tem sido a referência central para detecção de deepfake desde 2017, embora agora esteja consideravelmente desatualizado, em relação às mais recentes técnicas de síntese facial. Fonte: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Para lidar com o desequilíbrio de classes, os autores usaram Focal Loss (uma variante de perda de entropia cruzada), que enfatiza exemplos mais desafiadores durante o treinamento.
Todo o treinamento foi conduzido em uma única GPU RTX 4090 com 24GB de VRAM, com um tamanho de lote de 8 por 600 épocas (revisões completas dos dados), usando checkpoints pré-treinados do VideoMAE para inicializar os pesos para cada uma das tarefas pré-textuais.
Testes
Avaliações quantitativas e qualitativas foram realizadas contra uma variedade de métodos de detecção de deepfake: FTCN; RealForensics; Lip Forensics; EfficientNet+ViT; Face X-Ray; Alt-Freezing; CADMM; LAANet; e o SBI do BlendFace. Em todos os casos, o código-fonte estava disponível para esses frameworks.
Os testes se concentraram em deepfakes com edições locais, onde apenas parte de um clipe fonte foi alterada. As arquiteturas utilizadas foram Diffusion Video Autoencoders (DVA); Stitch It In Time (STIT); Desentangled Face Editing (DFE); Tokenflow; VideoP2P; Text2Live; e FateZero. Esses métodos empregam uma diversidade de abordagens (difusão para DVA e StyleGAN2 para STIT e DFE, por exemplo).
Os autores afirmam:
‘Para garantir uma cobertura abrangente de diferentes manipulações faciais, incorporamos uma ampla variedade de edições de características e atributos faciais. Para edição de características faciais, modificamos o tamanho dos olhos, distância olho-sobrancelha, proporção do nariz, distância nariz-boca, proporção dos lábios e proporção das bochechas. Para a edição de atributos faciais, variamos expressões como sorriso, raiva, nojo e tristeza.
‘Essa diversidade é essencial para validar a robustez do nosso modelo em uma ampla gama de edições localizadas. No total, geramos 50 vídeos para cada um dos métodos de edição mencionados acima e validamos a forte generalização do nosso método para a detecção de deepfakes.’
Conjuntos de dados de deepfake mais antigos também foram incluídos nos testes, a saber, Celeb-DFv2 (CDF2); Detecção de DeepFake (DFD); Desafio de Detecção de DeepFake (DFDC); e WildDeepfake (DFW).
Métricas de avaliação foram Área Sob a Curva (AUC); Precisão Média; e Média F1 Score.
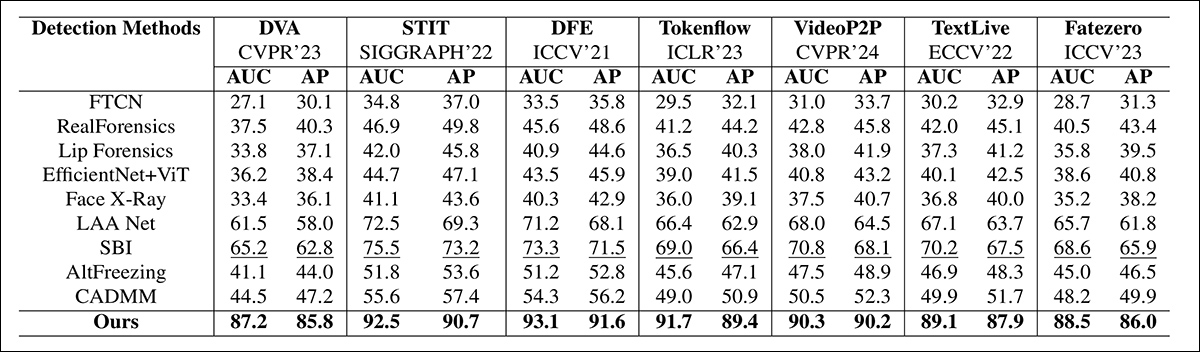
Do artigo: comparação em deepfakes localizados recentes mostra que o método proposto superou todos os outros, com um ganho de 15 a 20 por cento em AUC e precisão média em relação à próxima melhor abordagem.
Os autores também fornecem uma comparação de detecção visual para visualizações manipuladas localmente (reproduzidas apenas em parte abaixo, devido à falta de espaço):

Um vídeo real foi alterado usando três diferentes manipulações localizadas para produzir fakes que permaneceram visualmente semelhantes ao original. Aqui estão quadros representativos, juntamente com as médias das pontuações de detecção de fake para cada método. Enquanto detectores existentes lutaram com essas edições sutis, o modelo proposto consistentemente atribuiu altas probabilidades de fake, indicando maior sensibilidade a mudanças localizadas.
Os pesquisadores comentam:
‘[Os] métodos de detecção SOTA existentes, [LAANet], [SBI], [AltFreezing] e [CADMM], enfrentam uma queda significativa no desempenho nos últimos métodos de geração de deepfake. Os métodos atuais SOTA exibem AUCs tão baixas quanto 48-71%, demonstrando suas fracas capacidades de generalização para os deepfakes recentes.
‘Por outro lado, nosso método demonstra uma robusta generalização, alcançando uma AUC na faixa de 87-93%. Uma tendência semelhante é perceptível no caso de precisão média também. Como mostrado [abaixo], nosso método também consistentemente alcança alto desempenho em conjuntos de dados padrão, superando 90% AUC e é competitivo com modelos de detecção de deepfake recentes.’
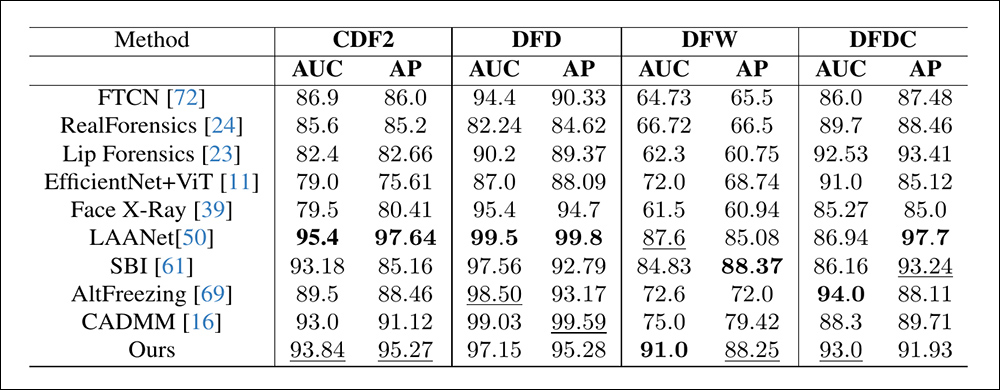
Desempenho em conjuntos de dados tradicionais de deepfake mostra que o método proposto permaneceu competitivo com abordagens líderes, indicando forte generalização em uma ampla gama de tipos de manipulação.
Os autores observam que esses últimos testes envolvem modelos que poderiam razoavelmente ser vistos como obsoletos, e que foram introduzidos antes de 2020.
Como uma representação visual mais extensa do desempenho do novo modelo, os autores fornecem uma tabela abrangente no final, da qual reproduzimos apenas uma parte aqui:

Nesses exemplos, um vídeo real foi modificado usando três edições localizadas para produzir fakes que eram visualmente semelhantes ao original. As médias das pontuações de confiança em relação a essas manipulações mostram, conforme afirmam os autores, que o método proposto detectou as falsificações de forma mais confiável do que outras abordagens líderes. Consulte a última página do PDF de origem para os resultados completos.
Os autores afirmam que seu método alcança pontuações de confiança acima de 90% na detecção de edições localizadas, enquanto os métodos de detecção existentes permaneceram abaixo de 50% na mesma tarefa. Eles interpretam essa diferença como uma evidência da sensibilidade e generalizabilidade de sua abordagem, e como uma indicação dos desafios enfrentados pelas técnicas atuais ao lidar com esse tipo de manipulação facial sutil.
Para avaliar a confiabilidade do modelo em condições do mundo real, e de acordo com o método estabelecido pelo CADMM, os autores testaram seu desempenho em vídeos modificados com distorções comuns, incluindo ajustes de saturação e contraste, desfoque gaussiano, pixelização e artefatos de compressão baseados em blocos, bem como ruído aditivo.
Os resultados mostraram que a precisão da detecção permaneceu amplamente estável diante dessas perturbações. A única queda notável ocorreu com a adição de ruído gaussiano, que causou uma ligeira queda no desempenho. Outras alterações tiveram efeito mínimo.
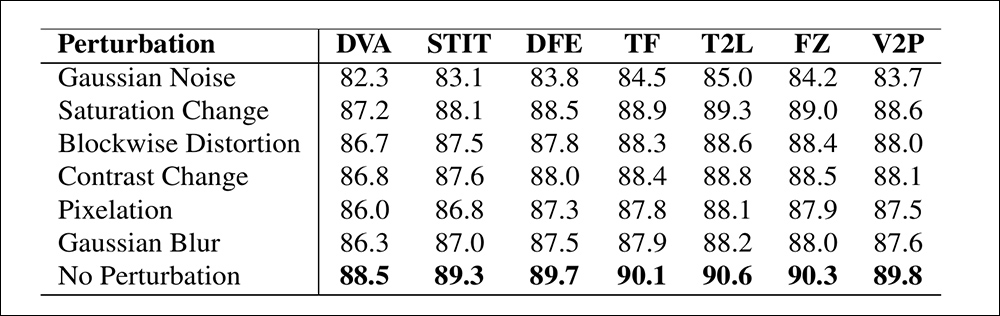
Uma ilustração de como a precisão da detecção muda sob diferentes distorções de vídeo. O novo método permaneceu resiliente na maioria dos casos, com apenas uma pequena queda na AUC. A queda mais significativa ocorreu quando o ruído gaussiano foi introduzido.
Essas descobertas, os autores propõem, sugerem que a habilidade do método de detectar manipulações localizadas não é facilmente interrompida por degradações típicas na qualidade do vídeo, apoiando seu potencial de robustez em configurações práticas.
Conclusão
A manipulação por IA existe na consciência pública principalmente na noção tradicional de deepfakes, onde a identidade de uma pessoa é imposta ao corpo de outra pessoa, que pode estar realizando ações antitéticas aos princípios do proprietário da identidade. Essa concepção está lentamente se atualizando para reconhecer as capacidades mais insidiosas dos sistemas de vídeo geradores (na nova geração de deepfakes de vídeo) e as capacidades dos modelos de difusão latente (LDMs) em geral.
Assim, é razoável esperar que o tipo de edição local que o novo artigo aborda pode não chegar à atenção pública até que um evento pivotal no estilo Pelosi ocorra, já que as pessoas estão distraídas por essa possibilidade por tópicos mais chamativos, como fraudes de deepfake em vídeo.
Porém, assim como o ator Nic Cage expressou uma preocupação constante sobre a possibilidade de os processos de pós-produção ‘revisarem’ o desempenho de um ator, nós também deveríamos talvez incentivar uma maior conscientização sobre esse tipo de ajuste de vídeo ‘sutil’ – não menos, pois somos por natureza incrivelmente sensíveis a variações muito pequenas de expressão facial, e porque o contexto pode alterar significativamente o impacto de pequenos movimentos faciais (considere o efeito disruptivo de até mesmo sorrir em um funeral, por exemplo).
Primeira publicação na quarta-feira, 2 de abril de 2025

Conteúdo relacionado

Como Claude Pensa? A Busca da Anthropic para Desvendar a Caixa-preta da IA
[the_ad id="145565"] Modelos de linguagem de grande escala (LLMs) como Claude mudaram a maneira como usamos a tecnologia. Eles alimentam ferramentas como chatbots, ajudam a…

A OpenAI busca reunir um grupo para aconselhar sobre seus objetivos sem fins lucrativos.
[the_ad id="145565"] Enquanto se prepara para fazer a transição de uma corporação sem fins lucrativos para uma com fins lucrativos, a OpenAI afirma que está convenindo um grupo…

Como a Amex utiliza IA para aumentar a eficiência: 40% menos escalonamentos de TI e 85% de aumento na assistência ao viajante.
[the_ad id="145565"] Participe das nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba mais A…