


Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de líderes do setor. Saiba mais
Todo o cenário de IA mudou em janeiro de 2025, após o então pouco conhecido startup de IA chinesa DeepSeek (uma subsidiária da empresa de análise quantitativa High-Flyer Capital Management, baseada em Hong Kong) lançar seu poderoso modelo de raciocínio em linguagem de código aberto, o DeepSeek R1, publicamente ao mundo, superando o desempenho de gigantes da tecnologia dos EUA, como a Meta.
À medida que o uso do DeepSeek se espalhou rapidamente entre pesquisadores e empresas, a Meta entrou em modo de pânico ao descobrir que esse novo modelo R1 foi treinado por uma fração do custo de muitos outros modelos líderes, tão pouco quanto alguns milhões de dólares – o que a empresa paga a alguns de seus próprios líderes de equipe de IA – e ainda assim alcançou um desempenho de ponta na categoria de código aberto.
A estratégia de IA generativa da Meta até aquele momento baseava-se na liberação de modelos de código aberto de ponta sob a marca “Llama” para que pesquisadores e empresas construíssem livremente (pelo menos, se tivessem menos de 700 milhões de usuários mensais, momento em que deveriam contatar a Meta para termos de licenciamento pagos especiais).
No entanto, o desempenho surpreendentemente bom do DeepSeek R1 com um orçamento muito menor aparentemente abalou a liderança da empresa e forçou algum tipo de reflexão, com a última versão do Llama, 3.3, tendo sido lançada apenas um mês antes, em dezembro de 2024, já parecendo desatualizada.
Agora sabemos os frutos dessa reflexão: hoje, o fundador e CEO da Meta, Mark Zuckerberg, usou sua conta no Instagram para anunciar uma nova série de modelos Llama 4, com dois deles — o Llama 4 Maverick de 400 bilhões de parâmetros e o Llama 4 Scout de 109 bilhões de parâmetros — disponíveis hoje para desenvolvedores baixarem e começarem a usar ou aprimorar agora em llama.com e na comunidade de compartilhamento de código de IA Hugging Face.
Um massivo Llama 4 Behemoth de 2 trilhões de parâmetros também está sendo exibido hoje, embora o post do blog da Meta sobre os lançamentos tenha dito que ainda estava sendo treinado e não deu indicação de quando poderia ser lançado. (Lembre-se de que parâmetros referem-se às configurações que governam o comportamento do modelo e que, geralmente, mais parâmetros significam um modelo mais poderoso e complexo.)
Uma característica de destaque desses modelos é que eles são todos multimodais — treinados e, portanto, capazes de receber e gerar texto, vídeo e imagens (o áudio não foi mencionado).
Outro destaque é que eles têm janelas de contexto incrivelmente longas — 1 milhão de tokens para o Llama 4 Maverick e 10 milhões para o Llama 4 Scout — o que é equivalente a cerca de 1.500 e 15.000 páginas de texto, respectivamente, tudo o que o modelo pode manipular em uma única interação de entrada/saída. Isso significa que um usuário poderia teoricamente carregar ou colar até 7.500 páginas de texto e receber uma quantidade equivalente em resposta do Llama 4 Scout, o que seria útil para áreas densas em informação, como medicina, ciência, engenharia, matemática, literatura, etc.
Aqui está o que mais aprendemos sobre este lançamento até agora:
Comprometidos com a mistura de especialistas
Todos os três modelos utilizam a abordagem de arquitetura “mistura de especialistas (MoE)” popularizada em lançamentos anteriores de modelos da OpenAI e Mistral, que essencialmente combina vários modelos menores especializados (“especialistas”) em diferentes tarefas, assuntos e formatos de mídia em um modelo maior e unificado. Cada lançamento do Llama 4 é, portanto, dito ser uma mistura de 128 especialistas diferentes, e mais eficiente de executar porque apenas o especialista necessário para uma tarefa específica, juntamente com um “especialista compartilhado”, processa cada token, em vez de todo o modelo ter que ser executado para cada um.
Como observa o post do blog do Llama 4:
Como resultado, enquanto todos os parâmetros são armazenados na memória, apenas um subconjunto dos parâmetros totais é ativado ao servir esses modelos. Isso melhora a eficiência da inferência ao reduzir os custos de serviço do modelo e a latência — o Llama 4 Maverick pode ser executado em um único host [Nvidia] H100 DGX para fácil implantação, ou com inferência distribuída para máxima eficiência.
Tanto o Scout quanto o Maverick estão disponíveis ao público para auto-hospedagem, enquanto nenhuma API hospedada ou faixas de preços foram anunciadas para a infraestrutura oficial da Meta. Em vez disso, a Meta se concentra na distribuição através de download aberto e integração com a Meta AI no WhatsApp, Messenger, Instagram e na web.
A Meta estima que o custo de inferência para o Llama 4 Maverick seja de $0,19 a $0,49 por 1 milhão de tokens (usando uma mistura de 3:1 de entrada e saída). Isso o torna substancialmente mais barato do que modelos proprietários como o GPT-4o, que é estimado em $4,38 por milhão de tokens, com base em benchmarks da comunidade.
De fato, logo após a publicação deste post, recebi a informação de que o provedor de inferência em nuvem Groq habilitou o Llama 4 Scout e Maverick nos seguintes preços:
- Llama 4 Scout: $0.11 / M tokens de entrada e $0.34 / M tokens de saída, com uma taxa misturada de $0.13
- Llama 4 Maverick: $0.50 / M tokens de entrada e $0.77 / M tokens de saída, com uma taxa misturada de $0.53
Todos os três modelos Llama 4 — especialmente Maverick e Behemoth — são explicitamente projetados para raciocínio, codificação e resolução de problemas passo a passo — embora não pareçam exibir as cadeias de pensamento de modelos de raciocínio dedicados, como a série “o” da OpenAI, nem o DeepSeek R1.
Em vez disso, parecem ser projetados para competir mais diretamente com LLMs e modelos multimodais “clássicos” não voltados para raciocínio, como o GPT-4o da OpenAI e o V3 do DeepSeek — com exceção do Llama 4 Behemoth, que parece ameaçar o DeepSeek R1 (mais sobre isso abaixo!)
Além disso, para o Llama 4, a Meta construiu fluxos de trabalho de pós-treinamento personalizados focados em aprimorar o raciocínio, tais como:
- Remover mais de 50% dos “prompts fáceis” durante o ajuste fino supervisionado.
- Adotar um loop de aprendizado por reforço contínuo com prompts progressivamente mais difíceis.
- Usar avaliação pass@k e amostragem curricular para fortalecer o desempenho em matemática, lógica e codificação.
- Implementar o MetaP, uma nova técnica que permite aos engenheiros ajustar hiperparâmetros (como taxas de aprendizado por camada) em modelos e aplicá-los a outros tamanhos de modelo e tipos de tokens, preservando o comportamento pretendido do modelo.
O MetaP é de particular interesse, pois poderá ser usado futuramente para definir hiperparâmetros em um modelo e, a partir disso, obter muitos outros tipos de modelos, aumentando a eficiência do treinamento.
Como meu colega do VentureBeat e especialista em LLM, Ben Dickson, opinou sobre a nova técnica MetaP: “Isso pode economizar muito tempo e dinheiro. Significa que eles realizam experimentos em modelos menores em vez de fazê-los em grande escala.”
Isso é especialmente crítico ao treinar modelos tão grandes quanto o Behemoth, que utiliza 32K GPUs e precisão FP8, alcançando 390 TFLOPs/GPU em um total de mais de 30 trilhões de tokens — mais do que o dobro dos dados de treinamento do Llama 3.
Em outras palavras: os pesquisadores podem informar amplamente como desejam que o modelo aja e aplicar isso a versões maiores e menores do modelo, e através de diferentes formas de mídia.
Uma família de modelos poderosa – mas ainda não a mais poderosa
Em seu vídeo de anúncio no Instagram (uma subsidiária da Meta, naturalmente), o CEO da Meta, Mark Zuckerberg, disse que o objetivo da empresa é “construir a IA líder do mundo, abrir o código e torná-la universalmente acessível para que todos no mundo se beneficiem… Eu disse por um tempo que acreditava que a IA de código aberto se tornaria os modelos líderes, e com o Llama 4, isso está começando a acontecer.”
É uma declaração claramente cuidadosamente formulada, assim como o post do blog da Meta chamando o Llama 4 Scout de “o melhor modelo multimodal do mundo em sua classe e mais poderoso do que todos os modelos Llama anteriores,” (ênfase adicionada por mim).
Em outras palavras, esses são modelos muito poderosos, perto do topo da pilha em comparação com outros em sua classe de tamanho de parâmetro, mas não necessariamente estabelecendo novos recordes de desempenho. Ainda assim, a Meta fez questão de destacar os modelos que sua nova família Llama 4 supera, entre eles:
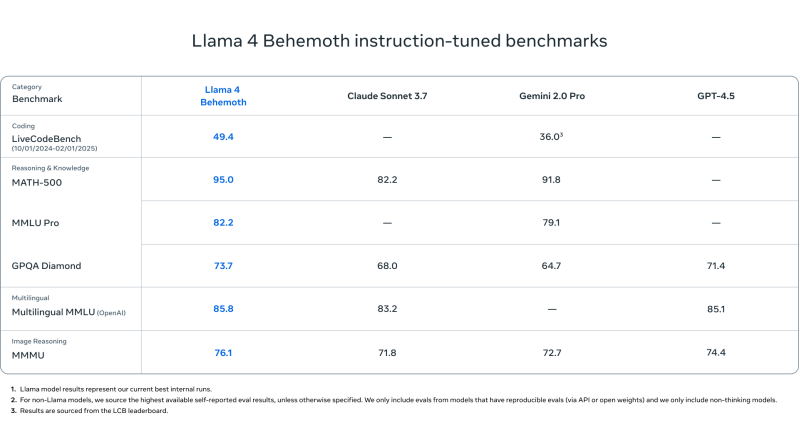
Llama 4 Behemoth
- Supera o GPT-4.5, Gemini 2.0 Pro e Claude Sonnet 3.7 em:
- MATH-500 (95.0)
- GPQA Diamond (73.7)
- MMLU Pro (82.2)
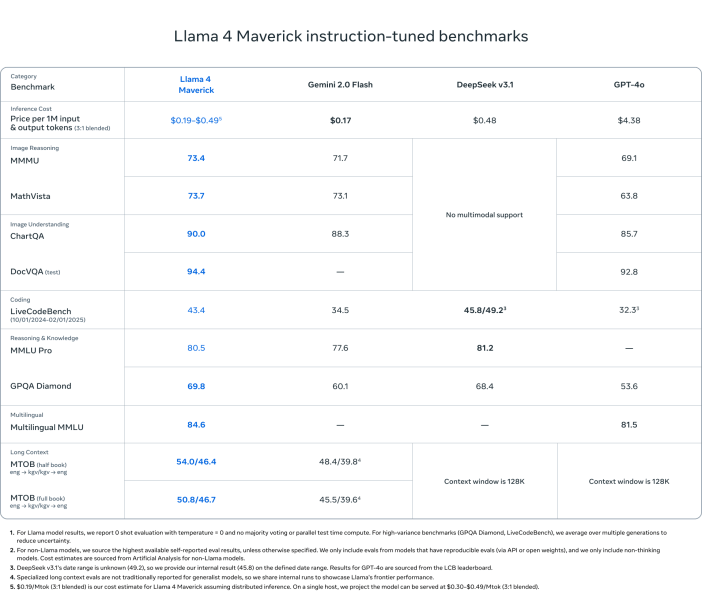
Llama 4 Maverick
- Supera o GPT-4o e Gemini 2.0 Flash na maioria dos benchmarks de raciocínio multimodal:
- ChartQA, DocVQA, MathVista, MMMU
- Competitivo com o DeepSeek v3.1 (45.8B de parâmetros) enquanto usa menos da metade dos parâmetros ativos (17B)
- Scores em benchmarks:
- ChartQA: 90.0 (contra 85.7 do GPT-4o)
- DocVQA: 94.4 (contra 92.8)
- MMLU Pro: 80.5
- Economicamente viável: $0.19–$0.49 por 1M tokens
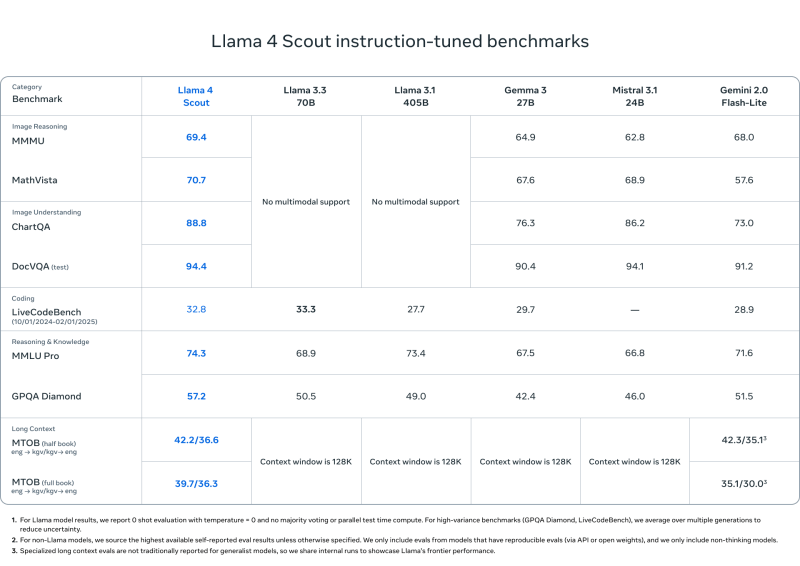
Llama 4 Scout
- Iguala ou supera modelos como Mistral 3.1, Gemini 2.0 Flash-Lite e Gemma 3 em:
- DocVQA: 94.4
- MMLU Pro: 74.3
- MathVista: 70.7
- Comprimento de contexto imbatível de 10M de tokens — ideal para documentos longos, bases de código ou análises em múltiplas interações
- Projetado para implantação eficiente em uma única GPU H100
Mas após tudo isso, como o Llama 4 se compara ao DeepSeek?
Mas, claro, há toda uma outra classe de modelos densos em raciocínio, como o DeepSeek R1, a série “o” da OpenAI (como o GPT-4o), Gemini 2.0 e Claude Sonnet.
Usando o modelo de maior parâmetro testado — Llama 4 Behemoth — e comparando-o com o gráfico de lançamento do DeepSeek R1 para os modelos R1-32B e OpenAI o1, aqui está como o Llama 4 Behemoth se compara:
| Benchmark | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
O que podemos concluir?
- MATH-500: Llama 4 Behemoth está ligeiramente atrasado em relação ao DeepSeek R1 e ao OpenAI o1.
- GPQA Diamond: Behemoth está à frente do DeepSeek R1, mas atrás do OpenAI o1.
- MMLU: Behemoth está atrás de ambos, mas ainda assim supera Gemini 2.0 Pro e GPT-4.5.
Conclusão: Embora DeepSeek R1 e OpenAI o1 superem o Behemoth em algumas métricas, o Llama 4 Behemoth continua altamente competitivo e apresenta desempenho próximo ao topo na classificação de raciocínio em sua classe.
Segurança e menos “viés” político
A Meta também enfatizou o alinhamento e a segurança do modelo ao apresentar ferramentas como Llama Guard, Prompt Guard e CyberSecEval para ajudar desenvolvedores a detectar entradas/saídas inseguras ou prompts adversariais, e implementar o Generative Offensive Agent Testing (GOAT) para testes automatizados de segurança.
A empresa também afirma que o Llama 4 mostra melhorias substanciais em relação ao “viés político” e diz que “especificamente, [os LLMs líderes] historicamente se inclinaram para a esquerda quando se trata de tópicos políticos e sociais debatidos,” e que o Llama 4 se sai melhor ao atrair a direita… em consonância com a aproximação de Zuckerberg com o presidente republicano dos EUA, Donald J. Trump e seu partido após as eleições de 2024.
Onde o Llama 4 se posiciona até agora
Os modelos Llama 4 da Meta unem eficiência, abertura e alto desempenho em tarefas multimodais e de raciocínio.
Com o Scout e Maverick já disponíveis ao público e Behemoth sendo apresentado como um modelo de ensino de estado-da-arte, o ecossistema Llama está posicionado para oferecer uma alternativa aberta competitiva aos modelos proprietários de primeira linha da OpenAI, Anthropic, DeepSeek e Google.
Se você está desenvolvendo assistentes em escala empresarial, pipelines de pesquisa em IA ou ferramentas analíticas de longo contexto, o Llama 4 oferece opções flexíveis de alto desempenho com uma clara orientação para um design voltado para raciocínio.


Conteúdo relacionado

Sam Altman pede por ‘privilégio da IA’ enquanto a OpenAI esclarece ordem judicial sobre retenção de sessões temporárias e deletadas do ChatGPT.
[the_ad id="145565"] Sure, here's the rewritten content in Portuguese while keeping the HTML tags intact: <div> <div id="boilerplate_2682874"…

Seguro de Responsabilidade Civil para IA: O Próximo Passo para Proteger Negócios de Falhas em IA
[the_ad id="145565"] As empresas hoje dependem fortemente da Inteligência Artificial (IA) para executar tarefas importantes, como lidar com perguntas de clientes, identificar…

Voice AI That Delivers: New TTS Model Increases Sales by 15% for Leading Brands in Portuguese
[the_ad id="145565"] Certainly! Here's the rewritten content in Portuguese while retaining the HTML tags: <div> <div id="boilerplate_2682874"…