


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre a cobertura de IA de ponta. Saiba Mais
O novo modelo de linguagem IA da Meta, Llama 4, foi divulgado repentinamente no final de semana, com a empresa-mãe do Facebook, Instagram, WhatsApp e Quest VR (entre outros serviços e produtos) apresentando não um, não dois, mas três versões — todas atualizadas para serem mais poderosas e eficientes utilizando a popular arquitetura “Mixture-of-Experts” e um novo método de treinamento envolvendo hiperparâmetros fixos, conhecido como MetaP.
Além disso, todas as três versões são equipadas com janelas de contexto massivas — a quantidade de informações que um modelo de linguagem IA pode lidar em uma única troca de entrada/saída com um usuário ou ferramenta.
Mas após o anúncio surpresa e lançamento público de dois desses modelos para download e uso — o Llama 4 Scout de menor parâmetro e o Llama 4 Maverick de médio porte — no sábado, a resposta da comunidade de IA nas redes sociais foi menos do que adorável.
Llama 4 gera confusão e críticas entre usuários de IA
Um post não verificado na comunidade de língua chinesa da América do Norte 1point3acres foi compartilhado no subreddit r/LocalLlama do Reddit, alegando ser de um pesquisador da organização GenAI da Meta, que afirmou que o modelo teve um desempenho ruim em benchmark de terceiros internamente e que a liderança da empresa “sugeriu mesclar conjuntos de teste de vários benchmarks durante o processo pós-treinamento, com o objetivo de atender às metas em várias métricas e produzir um resultado ‘apresentável’.”
O post foi recebido com ceticismo quanto à sua autenticidade pela comunidade, e um e-mail da VentureBeat para um porta-voz da Meta ainda não recebeu resposta.
Mas outros usuários encontraram motivos para duvidar dos benchmarks, de qualquer forma.
“Neste ponto, suspeito muito que a Meta tenha cometido um erro nos pesos liberados… se não, deveriam demitir todos que trabalharam nisso e usar o dinheiro para adquirir a Nous,” comentou @cto_junior no X, referindo-se a um teste de usuário independente que mostrou o pobre desempenho do Llama 4 Maverick (16%) em um benchmark conhecido como aide polyglot, que avalia um modelo em 225 tarefas de codificação. Isso está bem abaixo do desempenho de modelos mais antigos e comparáveis, como DeepSeek V3 e Claude 3.7 Sonnet.
Referindo-se à janela de contexto de 10 milhões de tokens que a Meta se orgulhava para o Llama 4 Scout, o PhD em IA e autor Andriy Burkov escreveu no X em parte: “O contexto declarado de 10M é virtual porque nenhum modelo foi treinado com prompts mais longos que 256k tokens. Isso significa que se você enviar mais de 256k tokens, a maioria das vezes terá uma saída de baixa qualidade.”
Também no subreddit r/LocalLlama, o usuário Dr_Karminski escreveu que “Estou incrivelmente decepcionado com o Llama-4,” e demonstrou seu pobre desempenho em comparação ao modelo V3 sem raciocínio da DeepSeek em tarefas de codificação como simular bolas pulando em um heptágono.
O ex-pesquisador da Meta e atual Cientista de Pesquisa Sênior da AI2 (Instituto Allen para Inteligência Artificial), Nathan Lambert, foi ao seu blog Interconnects Substack na segunda-feira para apontar que uma comparação de benchmark postada pela Meta em seu site de download do Llama comparando o Llama 4 Maverick a outros modelos, com base no custo-desempenho na ferramenta de comparação de terceiros LMArena ELO, também conhecida como Chatbot Arena, na verdade usou uma versão diferente do Llama 4 Maverick do que a empresa havia disponibilizado publicamente — uma “otimizada para conversação.”
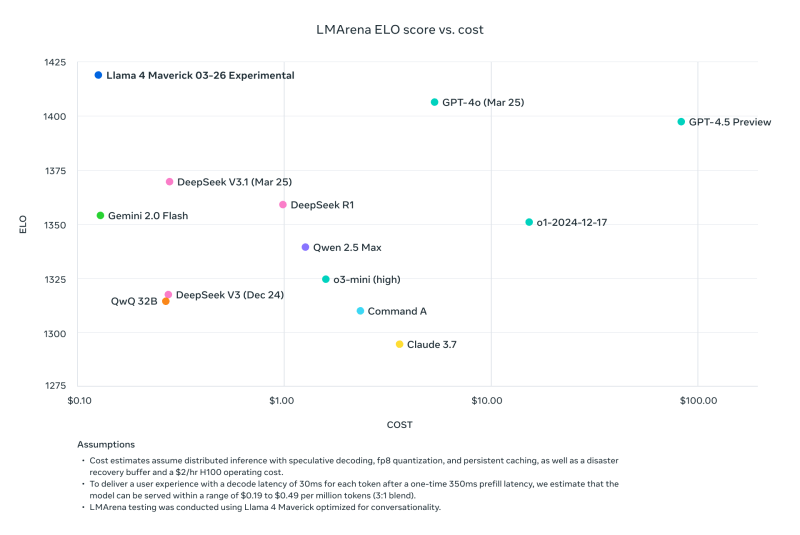
Como Lambert escreveu: “Sneaky. Os resultados abaixo são falsos, e é uma grande desconsideração com a comunidade da Meta não liberar o modelo que usaram para criar seu grande impulso de marketing. Vimos muitos modelos abertos que surgem para maximizar nas interfaces de ChatBotArena enquanto destroem o desempenho do modelo em habilidades importantes como matemática ou programação.”
Lambert prosseguiu observando que, enquanto este modelo específico na arena estava “afundando a reputação técnica do lançamento porque seu caráter é juvenil,” incluindo muitos emojis e diálogos emotivos fúteis, “O modelo real em outros provedores de hospedagem é bastante inteligente e tem um tom razoável!”
Em resposta ao turbilhão de críticas e acusações de manipulação de benchmarks, o VP e Chefe de GenAI da Meta, Ahmad Al-Dahle, usou o X para declarar:
“Estamos felizes em começar a disponibilizar o Llama 4 nas suas mãos. Já estamos ouvindo muitos ótimos resultados que as pessoas estão obtendo com esses modelos.
Isso dito, também estamos ouvindo alguns relatos de qualidade mista entre diferentes serviços. Como liberamos os modelos assim que estavam prontos, esperamos que leve vários dias para todas as implementações públicas se ajustarem. Continuaremos trabalhando nas correções de bugs e no processo de integração com os parceiros.
Também ouvimos alegações de que treinamos em conjuntos de teste — isso simplesmente não é verdade e nós nunca faríamos isso. Nossa melhor compreensão é que a qualidade variável que as pessoas estão vendo se deve à necessidade de estabilizar implementações.
Acreditamos que os modelos Llama 4 são um avanço significativo e estamos ansiosos para trabalhar com a comunidade para desbloquear seu valor.
Mesmo essa resposta encontrou muitas reclamações de desempenho ruim e pedidos por mais informações, como mais documentação técnica detalhando os modelos Llama 4 e seus processos de treinamento, além de perguntas adicionais sobre por que esse lançamento em comparação a todos os lançamentos anteriores do Llama estava particularmente repleto de problemas.
Isso também ocorre após o anúncio de Joelle Pineau, a número dois da pesquisa na Meta, que trabalhou na adjacente organização de Pesquisa em Inteligência Artificial Fundamentais (FAIR) da Meta, sobre sua saída da empresa no LinkedIn na semana passada com “nada além de admiração e profunda gratidão por cada um dos meus gerentes.” Pineau, deve-se notar, também promoveu a liberação da família de modelos Llama 4 no final de semana.
O Llama 4 continua a se espalhar para outros provedores de inferência com resultados mistos, mas é seguro dizer que o lançamento inicial da família de modelos não foi um grande sucesso na comunidade de IA.
Além disso, a próxima Meta LlamaCon em 29 de abril, a primeira celebração e reunião para desenvolvedores de terceiros da família de modelos, provavelmente terá muito o que discutir. Vamos acompanhar tudo isso, fique atento.


Conteúdo relacionado

Google afirma que a prévia do Gemini 2.5 Pro supera o DeepSeek R1 e o Grok 3 Beta em desempenho de programação.
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira…

AMD contrata os funcionários por trás da Untether AI
[the_ad id="145565"] A AMD continua sua onda de aquisições. A gigante de semicondutores AMD adquiriu a equipe por trás da Untether AI, uma startup que desenvolve chips de…

Chefe de marketing da OpenAI se afasta para tratar câncer de mama.
[the_ad id="145565"] A chefe de marketing da OpenAI, Kate Rouch, anunciou que estará se afastando de sua função por três meses enquanto passa por tratamento para câncer de mama…