


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura líder da indústria em IA. Saiba mais
Tudo começou com o anúncio do modelo o1 da OpenAI em setembro de 2024, mas realmente decolou com o lançamento do DeepSeek R1 em janeiro de 2025.
Agora, parece que a maioria dos principais fornecedores e treinadores de modelos de IA está em uma nova corrida para entregar modelos de linguagem “raciocínio” melhores, mais rápidos e mais baratos — ou seja, aqueles que podem demorar um pouco mais para responder a um usuário humano, mas que idealmente o fazem com respostas melhores, mais completas e mais bem “raciocinadas”, que essa classe de modelos consegue realizando “cadeias de pensamento”, refletindo sobre suas próprias conclusões e interrogando-as quanto à veracidade antes de responder.
ByteDance, o gigante da mídia online chinês e proprietário do TikTok, é o mais recente a entrar na disputa com o anúncio e a publicação do artigo técnico por trás do Seed-Thinking-v1.5, um próximo modelo de linguagem grande (LLM) projetado para avançar o desempenho de raciocínio em campos de ciência, tecnologia, matemática e engenharia (STEM) e em domínios de uso geral.
O modelo ainda não está disponível para download ou uso, e não está claro quais serão os termos de licenciamento — se será proprietário/código fechado, de código aberto/gratuito para todos usarem e modificarem à vontade, ou algo intermediário. No entanto, o artigo técnico fornece alguns detalhes notáveis que valem a pena ser abordados agora e em antecipação a quando forem disponibilizados.
Construído sobre a arquitetura cada vez mais popular Mixture-of-Experts (MoE)
Assim como o novo Llama 4 da Meta e o Mixtral da Mistral antes dele, o Seed-Thinking-v1.5 é construído usando uma arquitetura de Mixture-of-Experts (MoE).
Essa arquitetura é projetada para tornar os modelos mais eficientes. Ela essencialmente combina as capacidades de múltiplos modelos em um só, cada um especializado em um domínio diferente.
Neste caso, a arquitetura MoE significa que o Seed-Thinking-v1.5 utiliza apenas 20 bilhões dos 200 bilhões de parâmetros ao mesmo tempo.
A ByteDance diz em seu artigo técnico publicado no GitHub que o Seed-Thinking-v1.5 prioriza raciocínio estruturado e geração de respostas reflexivas.
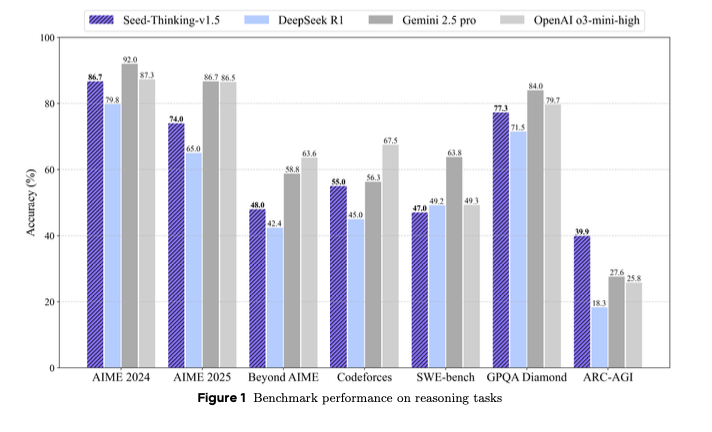
Os resultados quase falam por si mesmos, com Seed-Thinking-v1.5 superando o DeepSeek R1 e se aproximando do Gemini 2.5 Pro da Google e do raciocinador o3-mini-high da OpenAI em muitas avaliações de benchmark de terceiros. Ele até supera esses dois no caso do benchmark ARC-AGI, que mede o progresso em direção à inteligência geral artificial, vista como o objetivo ou “Santo Graal” da IA. Este modelo supera humanos na maioria das tarefas economicamente valiosas, de acordo com a definição da OpenAI.
Posicionado como uma alternativa compacta, mas capaz, em relação a modelos maiores de última geração, o Seed-Thinking-v1.5 alcança resultados competitivos em benchmarks. Ele introduz inovações em aprendizado por reforço (RL), curadoria de dados de treinamento e infraestrutura de IA.
Benchmarks de desempenho e foco do modelo
O Seed-Thinking-v1.5 apresenta forte desempenho em uma gama de tarefas desafiadoras, pontuando 86,7% no AIME 2024, 55,0% pass@8 no Codeforces e 77,3% no benchmark de ciência GPQA. Esses resultados o colocam próximo ou igualando modelos como o o3-mini-high da OpenAI e o Gemini 2.5 Pro da Google em métricas específicas de raciocínio.
Em tarefas não relacionadas ao raciocínio, o modelo foi avaliado através de comparações de preferência humana e alcançou uma taxa de vitória 8,0% maior em relação ao DeepSeek R1, sugerindo que suas forças se generalizam além de desafios lógicos ou matemáticos.
Para abordar a saturação em benchmarks padrão como AIME, a ByteDance introduziu o BeyondAIME, um novo benchmark de matemática mais difícil com problemas curados, projetados para resistir à memorização e discriminar melhor o desempenho dos modelos. Este e o conjunto de avaliação do Codeforces devem ser lançados publicamente para apoiar futuras pesquisas.
Estratégia de dados
Os dados de treinamento desempenharam um papel central no desenvolvimento do modelo. Para o ajuste fino supervisionado (SFT), a equipe curou 400.000 amostras, incluindo 300.000 problemas verificáveis (tarefa de STEM, lógica e programação) e 100.000 problemas não verificáveis, como redação criativa e interpretação de papéis.
Para o treinamento de RL, os dados foram segmentados em:
- Problemas verificáveis: 100.000 perguntas rigorosamente filtradas de STEM e quebra-cabeças lógicos com respostas conhecidas, provenientes de competições de elite e revisões de especialistas.
- Tarefas não verificáveis: Conjuntos de dados de preferência humana focados em prompts abertos, avaliados usando modelos de recompensa comparativos.
Os dados de STEM dependeram fortemente de matemática avançada, representando mais de 80% do conjunto de problemas. Dados adicionais de lógica incluíram tarefas como Sudoku e quebra-cabeças de 24 pontos, com dificuldade ajustável para corresponder ao progresso do modelo.
Abordagem de aprendizado por reforço
O aprendizado por reforço no Seed-Thinking-v1.5 é impulsionado por estruturas personalizadas de ator-crítico (VAPO) e gradiente de política (DAPO), desenvolvidas para abordar instabilidades conhecidas no treinamento de RL. Essas técnicas reduzem a escassez de sinal de recompensa e melhoram a estabilidade de treinamento, especialmente em configurações de cadeia de pensamento (CoT) longas.
Modelos de recompensa desempenham um papel crítico na supervisão da saída de RL. A ByteDance introduziu duas ferramentas principais:
- Seed-Verifier: Um LLM baseado em regras que verifica se as respostas geradas e de referência são matematicamente equivalentes.
- Seed-Thinking-Verifier: Um juiz baseado em raciocínio passo a passo que melhora a consistência do julgamento e resiste ao “hack” da recompensa.
Este sistema de recompensa de duas camadas permite uma avaliação matizada para tarefas tanto simples quanto complexas.
Infraestrutura e escalabilidade
Para suportar um treinamento em grande escala eficiente, a ByteDance construiu um sistema em cima de sua infraestrutura HybridFlow. A execução é gerida por clusters Ray, e os processos de treinamento e inferência são co-localizados para reduzir o tempo ocioso da GPU.
O Sistema de Lançamento de Streaming (SRS) é uma inovação notável que separa a evolução do modelo da execução em tempo de execução. Ele acelera a velocidade de iteração gerenciando de forma assíncrona as gerações parcialmente concluídas em versões de modelo. Esta arquitetura supostamente fornece ciclos de RL até 3 vezes mais rápidos.
Técnicas adicionais de infraestrutura incluem:
- Precisão mista (FP8) para economia de memória
- Paralelismo de especialistas e ajuste automático de núcleo para eficiência MoE
- ByteCheckpoint para checkpointing resiliente e flexível
- AutoTuner para otimização de paralelismo e configurações de memória
Avaliação humana e impacto no mundo real
Para avaliar a conformidade com as preferências centradas no ser humano, a ByteDance conduziu testes humanos em uma variedade de domínios, incluindo redação criativa, conhecimento das ciências humanas e conversa geral.
O Seed-Thinking-v1.5 consistentemente superou o DeepSeek R1 em sessões, reforçando sua aplicabilidade às necessidades reais dos usuários.
A equipe de desenvolvimento observa que modelos de raciocínio treinados principalmente em tarefas verificáveis demonstraram forte generalização para domínios criativos — um resultado atribuído à estrutura e rigores embutidos nos fluxos de trabalho de treinamento matemático.
O que isso significa para líderes técnicos, engenheiros de dados e tomadores de decisão empresariais
Para líderes técnicos que gerenciam o ciclo de vida de modelos de linguagem grandes — desde a curadoria de dados até a implementação — o Seed-Thinking-v1.5 apresenta uma oportunidade de repensar como as capacidades de raciocínio são integradas nas pilhas de IA das empresas.
Seu processo de treinamento modular, que inclui conjuntos de dados de raciocínio verificáveis e aprendizado por reforço em várias fases, atrai particularmente equipes que buscam escalar o desenvolvimento de LLM, mantendo controle refinado.
As ações da ByteDance para introduzir o Seed-Verifier e o Seed-Thinking-Verifier oferecem mecanismos para modelagem de recompensas mais confiáveis, que podem ser críticos ao implantar modelos em ambientes voltados para o cliente ou regulamentados.
Para equipes que operam sob prazos apertados e capacidade limitada, a estabilidade do modelo sob aprendizado por reforço, possibilitada por inovações como VAPO e amostragem dinâmica, pode reduzir ciclos de iteração e agilizar o ajuste fino para tarefas específicas.
De uma perspectiva de orquestração e implantação, a abordagem híbrida de infraestrutura do modelo — incluindo o Sistema de Lançamento de Streaming (SRS) e suporte para otimização FP8 — sugere ganhos significativos em rendimento de treinamento e utilização de hardware.
Essas características seriam valiosas para engenheiros responsáveis por escalar operações de LLM em sistemas de nuvem e locais. O fato de que o Seed-Thinking-v1.5 foi treinado com mecanismos para adaptar o feedback de recompensas com base em dinâmicas de tempo de execução aborda diretamente os desafios de gerenciar pipelines de dados heterogêneos e manter consistência em domínios.
Para equipes encarregadas de garantir confiabilidade, reprodutibilidade e integração contínua de novas ferramentas, o design em nível de sistema do Seed-Thinking-v1.5 pode servir como um modelo para construir sistemas de orquestração robustos e multimodais.
Para profissionais de engenharia de dados, a abordagem estruturada para os dados de treinamento — incluindo filtragem rigorosa, aumento e verificação por especialistas — reforça a importância da qualidade dos dados como um multiplicador do desempenho do modelo. Isso pode inspirar abordagens mais deliberadas para o desenvolvimento de conjuntos de dados e pipelines de validação.
Perspectivas futuras
O Seed-Thinking-v1.5 resulta da colaboração dentro da equipe de Sistemas Seed LLM da ByteDance, liderada por Yonghui Wu e com representação pública de Haibin Lin, um colaborador de IA de longa data.
O projeto também se baseia em esforços anteriores, como o Doubao 1.5 Pro, e incorpora técnicas compartilhadas em RLHF e curadoria de dados.
A equipe planeja continuar refinando as técnicas de aprendizado por reforço, com foco na eficiência de treinamento e modelagem de recompensas para tarefas não verificáveis. A liberação pública de benchmarks internos, como o BeyondAIME, tem a intenção de fomentar um avanço mais amplo na pesquisa em IA focada no raciocínio.


Conteúdo relacionado

Sora da OpenAI agora está disponível GRATUITAMENTE para todos os usuários através do Criador de Vídeos do Microsoft Bing no mobile.
[the_ad id="145565"] Here's the rewritten content in Portuguese, maintaining the HTML tags: <div> <div id="boilerplate_2682874" class="post-boilerplate…

Salesforce compra a Moonhub, uma startup desenvolvendo ferramentas de IA para recrutamento.
[the_ad id="145565"] Atualizado às 13h13, horário do Pacífico: Um porta-voz da Salesforce disse ao TechCrunch que a Moonhub não foi adquirida, de fato, pela definição da…

Plataforma de chatbot Character.AI lança geração de vídeos e feeds sociais
[the_ad id="145565"] Uma plataforma para conversar e fazer jogos de interpretação com personagens gerados por IA, a Character.AI anunciou em um post no blog na segunda-feira…