


Junte-se aos nossos boletins diários e semanais para atualizações mais recentes e conteúdo exclusivo sobre coberturas de IA líderes na indústria. Saiba mais
A inteligência é onipresente, mas sua medição parece subjetiva. No melhor dos casos, aproximamo-nos de sua medida por meio de testes e benchmarks. Pense nos exames de admissão à faculdade: a cada ano, muitos estudantes se inscrevem, memorizam truques de preparação para os testes e, às vezes, saem com notas perfeitas. Um único número, digamos 100%, significa que aqueles que o obtiveram compartilham a mesma inteligência — ou que de alguma forma maximizam sua inteligência? Claro que não. Os benchmarks são aproximações, não medidas exatas das verdadeiras capacidades de alguém — ou de algo.
A comunidade de IA generativa há muito se baseia em benchmarks como MMLU (Massive Multitask Language Understanding) para avaliar as capacidades dos modelos por meio de perguntas de múltipla escolha em diversas disciplinas acadêmicas. Este formato permite comparações diretas, mas falha em capturar verdadeiramente as capacidades inteligentes.
Tanto o Claude 3.5 Sonnet quanto o GPT-4.5, por exemplo, alcançam pontuações semelhantes nesse benchmark. No papel, isso sugere capacidades equivalentes. No entanto, quem trabalha com esses modelos sabe que existem diferenças substanciais em seu desempenho no mundo real.
O que significa medir a ‘inteligência’ na IA?
Com o lançamento do novo benchmark ARC-AGI — um teste projetado para impulsionar modelos em direção ao raciocínio geral e à resolução criativa de problemas — há um debate renovado sobre o que significa medir “inteligência” na IA. Embora nem todos tenham testado o benchmark ARC-AGI ainda, a indústria acolhe este e outros esforços para evoluir as estruturas de teste. Cada benchmark tem seu mérito, e o ARC-AGI é um passo promissor nessa conversa mais ampla.
Outro desenvolvimento notável na avaliação da IA é o ‘Último Exame da Humanidade’, um benchmark abrangente que contém 3.000 perguntas multi-etapas revisadas por pares em várias disciplinas. Enquanto este teste representa uma tentativa ambiciosa de desafiar sistemas de IA em raciocínio em nível de especialista, resultados iniciais mostram um progresso rápido — com a OpenAI supostamente alcançando uma pontuação de 26,6% dentro de um mês após seu lançamento. No entanto, como outros benchmarks tradicionais, ele avalia principalmente conhecimento e raciocínio de forma isolada, sem testar as capacidades práticas de uso de ferramentas que são cada vez mais cruciais para aplicações de IA no mundo real.
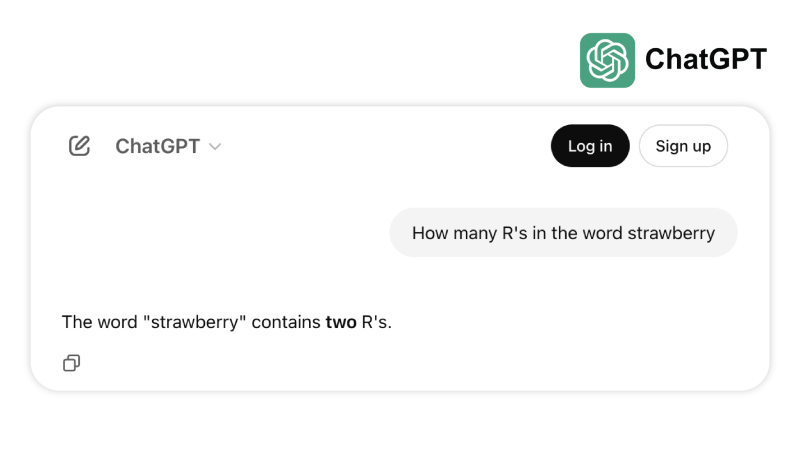
Em um exemplo, vários modelos de ponta falham em contar corretamente o número de “r” no word strawberry. Em outro, eles identificam incorretamente 3,8 como menor que 3,1111. Esses tipos de falhas — em tarefas que até mesmo uma criança pequena ou uma calculadora básica poderiam resolver — expõem uma discrepância entre o progresso orientado por benchmarks e a robustez no mundo real, lembrando-nos de que inteligência não é apenas sobre passar em exames, mas sobre navegar de forma confiável na lógica cotidiana.
O novo padrão para medir a capacidade de IA
À medida que os modelos avanços, esses benchmarks tradicionais revelaram suas limitações — o GPT-4 com ferramentas alcança apenas cerca de 15% em tarefas reais mais complexas no benchmark GAIA, apesar de pontuações impressionantes em testes de múltipla escolha.
Essa desconexão entre desempenho em benchmarks e capacidade prática tornou-se cada vez mais problemática à medida que os sistemas de IA vão de ambientes de pesquisa para aplicações comerciais. Os benchmarks tradicionais testam o recall de conhecimento, mas perdem aspectos cruciais da inteligência: a capacidade de coletar informações, executar código, analisar dados e sintetizar soluções em múltiplos domínios.
O GAIA é a mudança necessária na metodologia de avaliação da IA. Criado por meio da colaboração entre as equipes Meta-FAIR, Meta-GenAI, HuggingFace e AutoGPT, o benchmark inclui 466 perguntas cuidadosamente elaboradas em três níveis de dificuldade. Essas perguntas testam navegação na web, compreensão multimodal, execução de código, manipulação de arquivos e raciocínio complexo — capacidades essenciais para aplicações de IA no mundo real.
As perguntas do Nível 1 exigem aproximadamente 5 etapas e uma ferramenta para humanos resolverem. As perguntas do Nível 2 exigem de 5 a 10 etapas e várias ferramentas, enquanto as perguntas do Nível 3 podem exigir até 50 etapas discretas e qualquer número de ferramentas. Essa estrutura reflete a complexidade real dos problemas empresariais, onde soluções raramente vêm de uma única ação ou ferramenta.
Ao priorizar flexibilidade em vez de complexidade, um modelo de IA alcançou 75% de precisão no GAIA — superando gigantes da indústria como o Magnetic-1 da Microsoft (38%) e o Langfun Agent do Google (49%). O sucesso deles decorre da utilização de uma combinação de modelos especializados para compreensão áudio-visual e raciocínio, com o modelo principal sendo o Sonnet 3.5 da Anthropic.
Essa evolução na avaliação da IA reflete uma mudança mais ampla na indústria: estamos passando de aplicações SaaS independentes para agentes de IA que podem orquestrar múltiplas ferramentas e fluxos de trabalho. À medida que as empresas dependem cada vez mais de sistemas de IA para lidar com tarefas complexas e em várias etapas, benchmarks como o GAIA fornecem uma medida mais significativa de capacidade do que os tradicionais testes de múltipla escolha.
O futuro da avaliação da IA não reside em testes isolados de conhecimento, mas em avaliações abrangentes da capacidade de resolução de problemas. O GAIA estabelece um novo padrão para medir a capacidade de IA — um que reflete melhor os desafios e oportunidades da implementação de IA no mundo real.
Sri Ambati é o fundador e CEO da H2O.ai.


Conteúdo relacionado

Telli, uma ex-aluna da YC, levanta financiamento pré-seed para seus agentes de voz com IA.
[the_ad id="145565"] A ex-startup do Y Combinator Telli está auxiliando empresas a aliviar o gargalo que ocorre quando um grande volume de clientes tenta, por exemplo, agendar…

Exportações do chip Nvidia H20 enfrentam exigência de licença pelo governo dos EUA
[the_ad id="145565"] A gigante de semicondutores Nvidia está enfrentando novos controles de exportação inesperados dos EUA sobre seus chips H20. Em um comunicado na…

Moveworks entra na onda da biblioteca de agentes de IA
[the_ad id="145565"] Participe de nossos boletins diários e semanais para receber as últimas atualizações e conteúdos exclusivos sobre a cobertura líder da indústria em IA.…