


Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura da IA de ponta. Saiba mais
Pesquisadores da Universidade de Stanford e do Google DeepMind revelaram o Aprendizado por Reforço Passo a Passo (SWiRL), uma técnica projetada para melhorar a capacidade de modelos de linguagem de grande porte (LLMs) em abordar tarefas complexas que exigem raciocínio em múltiplas etapas e uso de ferramentas.
À medida que o interesse em agentes de IA e no uso de ferramentas por LLMs continua a crescer, essa técnica pode oferecer benefícios substanciais para empresas que buscam integrar modelos de raciocínio em suas aplicações e fluxos de trabalho.
O desafio dos problemas de múltiplas etapas
Aplicações empresariais no mundo real muitas vezes envolvem processos de múltiplas etapas. Por exemplo, planejar uma campanha de marketing complexa pode envolver pesquisa de mercado, análise de dados internos, cálculo de orçamento e revisão de tickets de suporte ao cliente. Isso requer pesquisas online, acesso a bancos de dados internos e execução de código.
Métodos tradicionais de aprendizado por reforço (RL) usados para ajustar LLMs, como Aprendizado por Reforço a partir de Feedback Humano (RLHF) ou RL a partir de Feedback de IA (RLAIF), normalmente se concentram na otimização de modelos para tarefas de raciocínio de uma única etapa.
Os autores principais do artigo sobre SWiRL, Anna Goldie, cientista de pesquisa no Google DeepMind, e Azalia Mirhosseini, professora assistente de ciência da computação na Universidade de Stanford, acreditam que os métodos atuais de treinamento de LLM não são adequados para as tarefas de raciocínio em múltiplas etapas que as aplicações do mundo real exigem.
“LLMs treinados por métodos tradicionais normalmente têm dificuldade com planejamento de múltiplas etapas e integração de ferramentas, o que significa que eles têm dificuldades em realizar tarefas que exigem recuperação e síntese de documentos de várias fontes (por exemplo, escrever um relatório de negócios) ou múltiplas etapas de raciocínio e cálculo aritmético (por exemplo, preparar um resumo financeiro),” disseram eles ao VentureBeat.
Aprendizado por Reforço Passo a Passo (SWiRL)
SWiRL enfrenta esse desafio de múltiplas etapas por meio de uma combinação de geração de dados sintéticos e uma abordagem de RL especializada que treina modelos em sequências inteiras de ações.
Conforme afirmam os pesquisadores em seu artigo, “Nosso objetivo é ensinar o modelo a decompor problemas complexos em uma sequência de subtarefas mais gerenciáveis, quando chamar a ferramenta, como formular uma chamada para a ferramenta, quando usar os resultados dessas consultas para responder à pergunta, e como sintetizar efetivamente suas descobertas.”
SWiRL utiliza uma metodologia de duas etapas. Primeiro, gera e filtra grandes quantidades de dados sobre raciocínio em múltiplas etapas e uso de ferramentas. Em segundo lugar, utiliza um algoritmo de RL passo a passo para otimizar um LLM base usando essas trajetórias geradas.
“Essa abordagem tem a vantagem prática fundamental de que podemos gerar rapidamente grandes volumes de dados de treinamento em múltiplas etapas por meio de chamadas paralelas para evitar sobrecarregar o processo de treinamento com a execução lenta do uso de ferramentas,” observa o artigo. “Além disso, esse processo offline permite maior reprodutibilidade devido à possuírem um conjunto de dados fixo.”
Geração de dados de treinamento
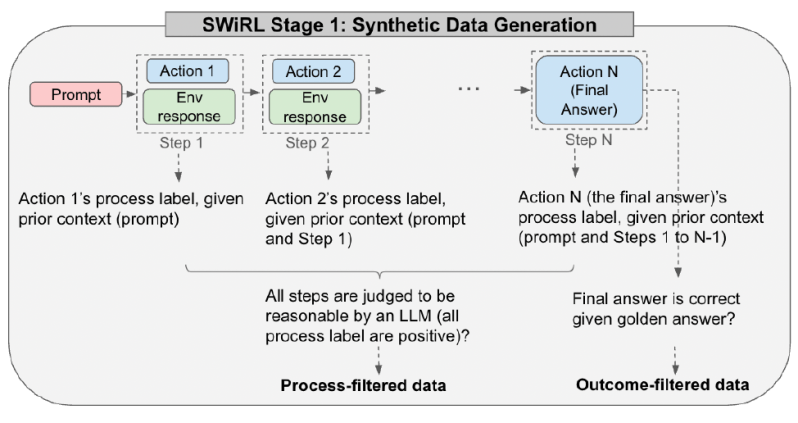
A primeira etapa envolve a criação dos dados sintéticos dos quais o SWiRL aprende. Um LLM tem acesso a uma ferramenta relevante, como um mecanismo de busca ou uma calculadora. O modelo é então incentivado de forma iterativa a gerar uma “trajetória”, uma sequência de etapas para resolver um determinado problema. Em cada etapa, o modelo pode gerar raciocínio interno (sua “cadeia de pensamento”), chamar uma ferramenta ou produzir a resposta final. Se chamar uma ferramenta, a consulta é extraída, executada (por exemplo, uma pesquisa é realizada) e o resultado é alimentado novamente no contexto do modelo para a próxima etapa. Isso continua até que o modelo forneça uma resposta final.
Cada trajetória completa, desde o prompt inicial até a resposta final, é então fragmentada em várias sub-trajectórias sobrepostas. Cada sub-trajetória representa o processo até uma ação específica, proporcionando uma visão granular do raciocínio passo a passo do modelo. Usando esse método, a equipe compilou grandes conjuntos de dados com base em questões de resposta a perguntas de múltiplas etapas (HotPotQA) e resolução de problemas matemáticos (GSM8K), gerando dezenas de milhares de trajetórias.
Os pesquisadores exploraram quatro diferentes estratégias de filtragem de dados: sem filtragem, filtragem baseada exclusivamente na correção da resposta final (filtragem de resultados), filtragem baseada na razoabilidade julgada de cada etapa individual (filtragem de processos) e filtragem com base em ambos: processo e resultado.
Muitas abordagens padrão, como Ajuste Supervisionado (SFT), dependem fortemente de “rótulos dourados” (respostas corretas, predefinidas e perfeitas) e frequentemente descartam dados que não levam à resposta final correta. Abordagens de RL recentes, como a usada no DeepSeek-R1, também usam recompensas baseadas no resultado para treinar o modelo.
Em contraste, o SWiRL alcançou seus melhores resultados usando dados filtrados por processo. Isso significa que os dados incluíam trajetórias nas quais cada etapa de raciocínio ou chamada de ferramenta era considerada lógica, dado o contexto anterior, mesmo que a resposta final se mostrasse errada.
Os pesquisadores descobriram que o SWiRL pode “aprender mesmo a partir de trajetórias que terminam em respostas finais incorretas. Na verdade, nossos melhores resultados são alcançados ao incluir dados filtrados por processo, independentemente da correção do resultado.”
Treinando LLMs com SWiRL

Na segunda etapa, o SWiRL utiliza aprendizado por reforço para treinar um LLM base com as trajetórias sintéticas geradas. Em cada passo dentro de uma trajetória, o modelo é otimizado para prever a próxima ação apropriada (um passo de raciocínio intermediário, uma chamada de ferramenta ou a resposta final) com base no contexto anterior.
O LLM recebe feedback a cada passo de um modelo de recompensa gerador separado, que avalia a ação gerada pelo modelo dado o contexto até aquele ponto.
“Nosso paradigma de ajuste granular e passo a passo permite que o modelo aprenda tanto a tomada de decisão local (previsão do próximo passo) quanto a otimização global da trajetória (geração da resposta final), enquanto é guiado por feedback imediato sobre a solidez de cada previsão,” escrevem os pesquisadores.
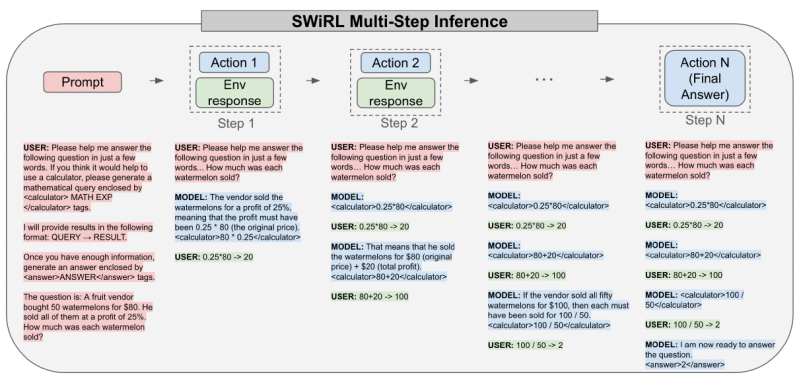
No momento da inferência, um modelo treinado com SWiRL opera da mesma forma iterativa. Ele recebe um prompt e gera texto em resposta. Se gerar uma chamada de ferramenta (como uma consulta de busca ou uma expressão matemática), o sistema a analisa, executa a ferramenta e alimenta o resultado de volta na janela de contexto do modelo. O modelo continua gerando, potencialmente fazendo mais chamadas de ferramenta, até que produza uma resposta final ou atinja um limite predefinido no número de etapas.
“Ao treinar o modelo para dar passos razoáveis em cada momento (e fazê-lo de uma maneira coerente e potencialmente mais explicável), abordamos uma fraqueza central dos LLMs tradicionais, nomeadamente sua fragilidade diante de tarefas complexas de múltiplas etapas, onde a probabilidade de sucesso decai exponencialmente com o comprimento do caminho,” afirmaram Goldie e Mirhoseini. “A IA empresarial útil e robusta inevitavelmente precisará integrar uma ampla variedade de ferramentas diferentes, encadeando-as em sequências complexas.”
SWiRL em ação
A equipe da Stanford e do Google DeepMind avaliou o SWiRL em várias tarefas desafiadoras de resposta a perguntas de múltiplas etapas e raciocínio matemático. Comparado a modelos de referência, o SWiRL demonstrou melhorias de precisão relativas significativas, variando de 11% a mais de 21% em conjuntos de dados como GSM8K, HotPotQA, MuSiQue e BeerQA.
Os experimentos confirmaram que treinar um modelo Gemma 2-27B com SWiRL em dados filtrados por processo produziu os melhores resultados, superando modelos treinados com dados filtrados por resultado ou usando SFT tradicional. Isso sugere que o SWiRL aprende o processo de raciocínio subjacente de forma mais eficaz, em vez de apenas memorizar caminhos para respostas corretas, o que ajuda no desempenho em problemas não vistos.
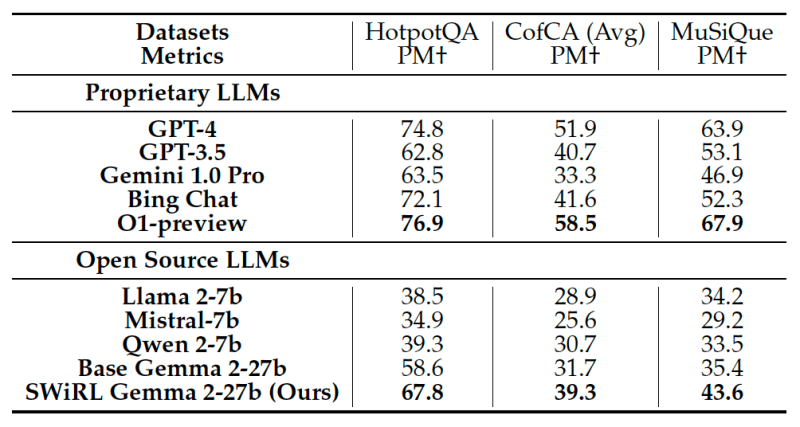
Mais importante ainda, o SWiRL exibiu fortes capacidades de generalização. Por exemplo, treinar um modelo usando SWiRL em exemplos de respostas a perguntas baseados em texto melhorou seu desempenho em tarefas de raciocínio matemático, mesmo que o modelo não tivesse sido explicitamente treinado em problemas matemáticos.
Essa transferibilidade entre diferentes tarefas e tipos de ferramentas é extremamente valiosa, já que há uma explosão de aplicações agentivas para modelos de linguagem, e métodos que se generalizam entre conjuntos de dados e tarefas serão mais fáceis, mais baratos e mais rápidos de adaptar a novos ambientes.
“A generalização do SWiRL parece bastante robusta nos domínios que exploramos, mas seria interessante testar isso em outras áreas, como programação,” afirmaram Goldie e Mirhoseini. “Nossas descobertas sugerem que um modelo de IA empresarial treinado em uma tarefa central usando SWiRL provavelmente apresentaria melhorias significativas de desempenho em outras tarefas aparentemente não relacionadas, sem ajuste específico para a tarefa. O SWiRL generaliza melhor quando aplicado a modelos maiores (ou seja, mais poderosos), indicando que essa técnica pode ser ainda mais eficaz no futuro, à medida que as capacidades básicas crescem.”


Conteúdo relacionado

OpenAI explica por que o ChatGPT se tornou excessivamente bajulador
[the_ad id="145565"] A OpenAI publicou um postmortem sobre os recentes problemas de bajulação com o modelo padrão que alimenta o ChatGPT, o GPT-4o — questões que forçaram a…

Structify capta R$ 4,1 milhões em seed para transformar dados não estruturados da web em conjuntos de dados prontos para empresas.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder do setor. Saiba mais…

A startup de vendas de IA Kintsugi dobrou sua avaliação em 6 meses.
[the_ad id="145565"] Kintsugi, uma startup baseada no Vale do Silício que ajuda empresas a automatizar e facilitar a conformidade com impostos sobre vendas, levantou US$ 18…